 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract, Integrate, Compete: Towards Verification Style Reading Comprehension
Paper and Code
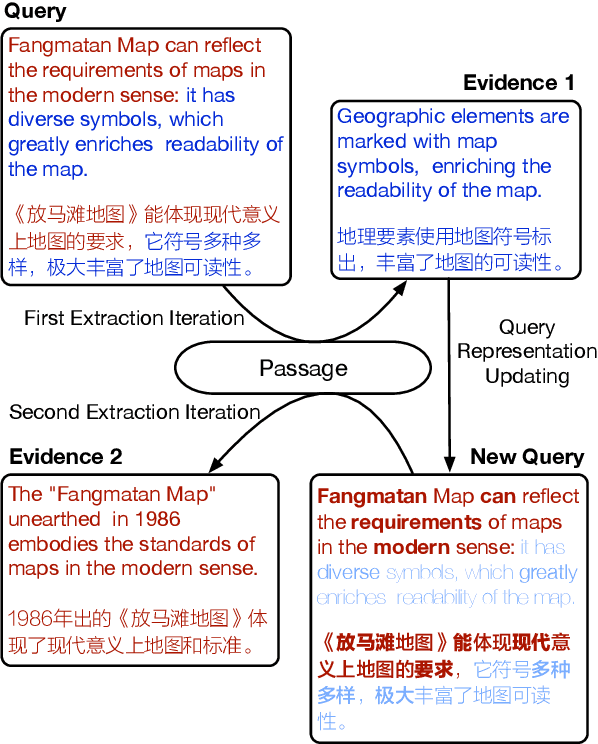

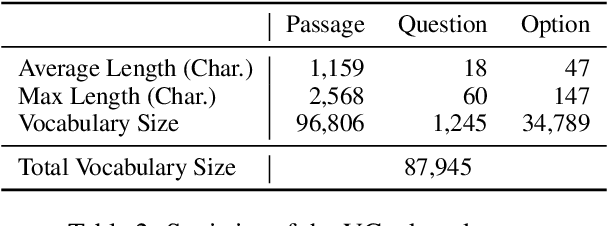
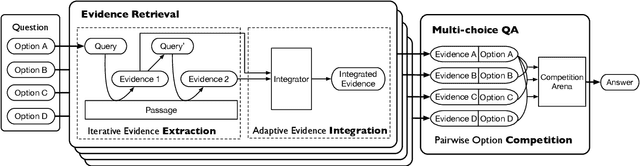
In this paper, we present a new verification style reading comprehension dataset named VGaokao from Chinese Language tests of Gaokao. Different from existing efforts, the new dataset is originally designed for native speakers' evaluation, thus requiring more advanced language understanding skills. To address the challenges in VGaokao, we propose a novel Extract-Integrate-Compete approach, which iteratively selects complementary evidence with a novel query updating mechanism and adaptively distills supportive evidence, followed by a pairwise competition to push models to learn the subtle difference among similar text pieces. Experiments show that our methods outperform various baselines on VGaokao with retrieved complementary evidence, while having the merits of efficiency and explainability. Our dataset and code are released for further research.