 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Variational Autoencoders with Smooth Robust Latent Encoding
Apr 24, 2025
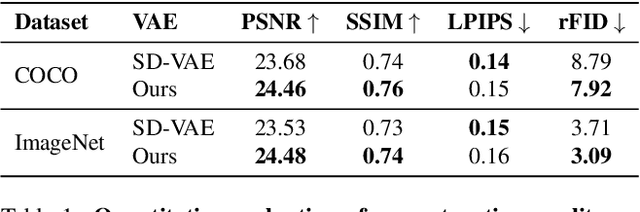
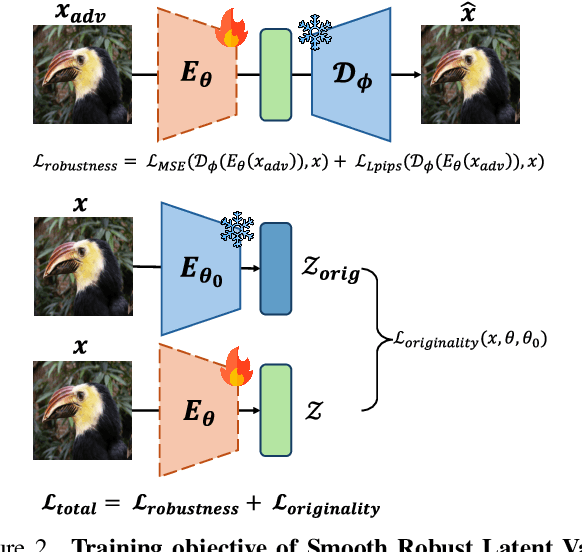
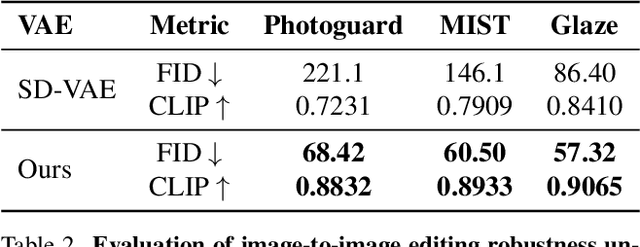
Variational Autoencoders (VAEs) have played a key role in scaling up diffusion-based generative models, as in Stable Diffusion, yet questions regarding their robustness remain largely underexplored. Although adversarial training has been an established technique for enhancing robustness in predictive models, it has been overlooked for generative models due to concerns about potential fidelity degradation by the nature of trade-offs between performance and robustness. In this work, we challenge this presumption, introducing Smooth Robust Latent VAE (SRL-VAE), a novel adversarial training framework that boosts both generation quality and robustness. In contrast to conventional adversarial training, which focuses on robustness only, our approach smooths the latent space via adversarial perturbations, promoting more generalizable representations while regularizing with originality representation to sustain original fidelity. Applied as a post-training step on pre-trained VAEs, SRL-VAE improves image robustness and fidelity with minimal computational overhead. Experiments show that SRL-VAE improves both generation quality, in image reconstruction and text-guided image editing, and robustness, against Nightshade attacks and image editing attacks. These results establish a new paradigm, showing that adversarial training, once thought to be detrimental to generative models, can instead enhance both fidelity and robustness.
Automatic Jailbreaking of the Text-to-Image Generative AI Systems
May 28, 2024



Recent AI systems have shown extremely powerful performance, even surpassing human performance, on various tasks such as information retrieval, language generation, and image generation based on large language models (LLMs). At the same time, there are diverse safety risks that can cause the generation of malicious contents by circumventing the alignment in LLMs, which are often referred to as jailbreaking. However, most of the previous works only focused on the text-based jailbreaking in LLMs, and the jailbreaking of the text-to-image (T2I) generation system has been relatively overlooked. In this paper, we first evaluate the safety of the commercial T2I generation systems, such as ChatGPT, Copilot, and Gemini, on copyright infringement with naive prompts. From this empirical study, we find that Copilot and Gemini block only 12% and 17% of the attacks with naive prompts, respectively, while ChatGPT blocks 84% of them. Then, we further propose a stronger automated jailbreaking pipeline for T2I generation systems, which produces prompts that bypass their safety guards. Our automated jailbreaking framework leverages an LLM optimizer to generate prompts to maximize degree of violation from the generated images without any weight updates or gradient computation. Surprisingly, our simple yet effective approach successfully jailbreaks the ChatGPT with 11.0% block rate, making it generate copyrighted contents in 76% of the time. Finally, we explore various defense strategies, such as post-generation filtering and machine unlearning techniques, but found that they were inadequate, which suggests the necessity of stronger defense mechanisms.