 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Adversarial Examples for Vertical Federated Learning: Optimal Client Corruption through Multi-Armed Bandit
Paper and Code
Aug 08, 2024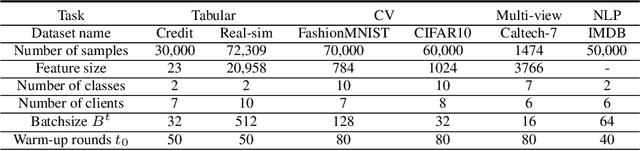
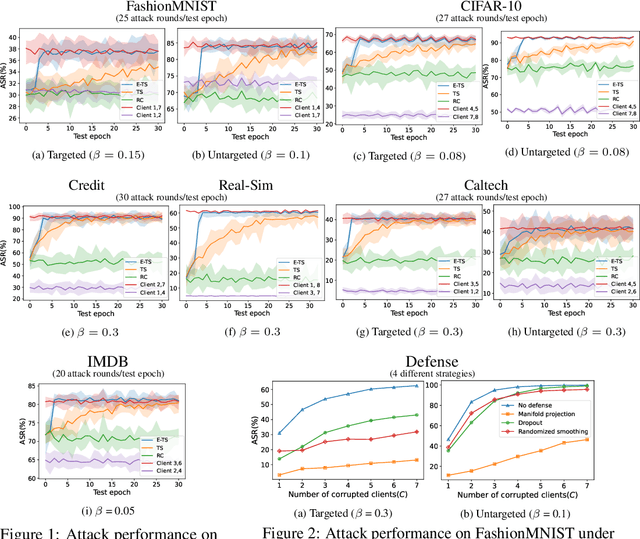
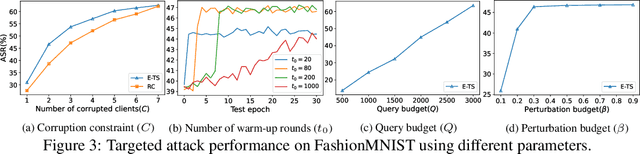
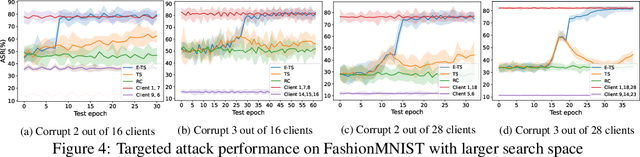
Vertical federated learning (VFL), where each participating client holds a subset of data features, has found numerous applications in finance, healthcare, and IoT systems. However, adversarial attacks, particularly through the injection of adversarial examples (AEs), pose serious challenges to the security of VFL models. In this paper, we investigate such vulnerabilities through developing a novel attack to disrupt the VFL inference process, under a practical scenario where the adversary is able to adaptively corrupt a subset of clients. We formulate the problem of finding optimal attack strategies as an online optimization problem, which is decomposed into an inner problem of adversarial example generation (AEG) and an outer problem of corruption pattern selection (CPS). Specifically, we establish the equivalence between the formulated CPS problem and a multi-armed bandit (MAB) problem, and propose the Thompson sampling with Empirical maximum reward (E-TS) algorithm for the adversary to efficiently identify the optimal subset of clients for corruption. The key idea of E-TS is to introduce an estimation of the expected maximum reward for each arm, which helps to specify a small set of competitive arms, on which the exploration for the optimal arm is performed. This significantly reduces the exploration space, which otherwise can quickly become prohibitively large as the number of clients increases. We analytically characterize the regret bound of E-TS, and empirically demonstrate its capability of efficiently revealing the optimal corruption pattern with the highest attack success rate, under various datasets of popular VFL tasks.