 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark on Drug Target Interaction Modeling from a Structure Perspective
Jul 04, 2024The prediction modeling of drug-target interactions is crucial to drug discovery and design, which has seen rapid advancements owing to deep learning technologies. Recently developed methods, such as those based on graph neural networks (GNNs) and Transformers, demonstrate exceptional performance across various datasets by effectively extracting structural information. However, the benchmarking of these novel methods often varies significantly in terms of hyperparameter settings and datasets, which limits algorithmic progress. In view of these, we conduct a comprehensive survey and benchmark for drug-target interaction modeling from a structure perspective, via integrating tens of explicit (i.e., GNN-based) and implicit (i.e., Transformer-based) structure learning algorithms. To this end, we first unify the hyperparameter setting within each class of structure learning methods. Moreover, we conduct a macroscopical comparison between these two classes of encoding strategies as well as the different featurization techniques that inform molecules' chemical and physical properties. We then carry out the microscopical comparison between all the integrated models across the six datasets, via comprehensively benchmarking their effectiveness and efficiency. Remarkably, the summarized insights from the benchmark studies lead to the design of model combos. We demonstrate that our combos can achieve new state-of-the-art performance on various datasets associated with cost-effective memory and computation. Our code is available at \hyperlink{https://github.com/justinwjl/GTB-DTI/tree/main}{https://github.com/justinwjl/GTB-DTI/tree/main}.
The Heterophilic Snowflake Hypothesis: Training and Empowering GNNs for Heterophilic Graphs
Jun 18, 2024



Graph Neural Networks (GNNs) have become pivotal tools for a range of graph-based learning tasks. Notably, most current GNN architectures operate under the assumption of homophily, whether explicitly or implicitly. While this underlying assumption is frequently adopted, it is not universally applicable, which can result in potential shortcomings in learning effectiveness. In this paper, \textbf{for the first time}, we transfer the prevailing concept of ``one node one receptive field" to the heterophilic graph. By constructing a proxy label predictor, we enable each node to possess a latent prediction distribution, which assists connected nodes in determining whether they should aggregate their associated neighbors. Ultimately, every node can have its own unique aggregation hop and pattern, much like each snowflake is unique and possesses its own characteristics. Based on observations, we innovatively introduce the Heterophily Snowflake Hypothesis and provide an effective solution to guide and facilitate research on heterophilic graphs and beyond. We conduct comprehensive experiments including (1) main results on 10 graphs with varying heterophily ratios across 10 backbones; (2) scalability on various deep GNN backbones (SGC, JKNet, etc.) across various large number of layers (2,4,6,8,16,32 layers); (3) comparison with conventional snowflake hypothesis; (4) efficiency comparison with existing graph pruning algorithms. Our observations show that our framework acts as a versatile operator for diverse tasks. It can be integrated into various GNN frameworks, boosting performance in-depth and offering an explainable approach to choosing the optimal network depth. The source code is available at \url{https://github.com/bingreeky/HeteroSnoH}.
CRB Analysis for Mixed-ADC Based DOA Estimation
Mar 14, 2024
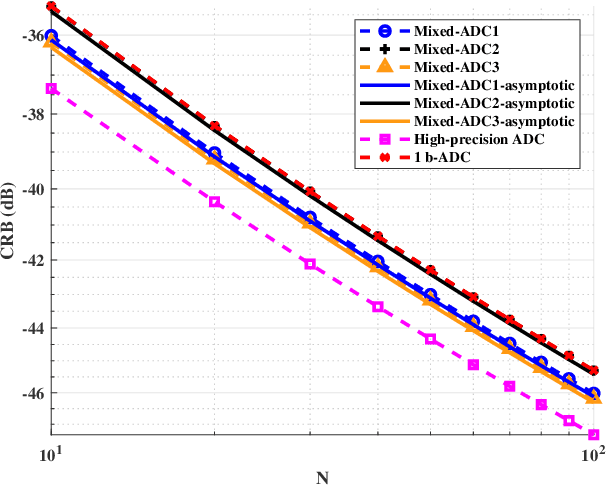
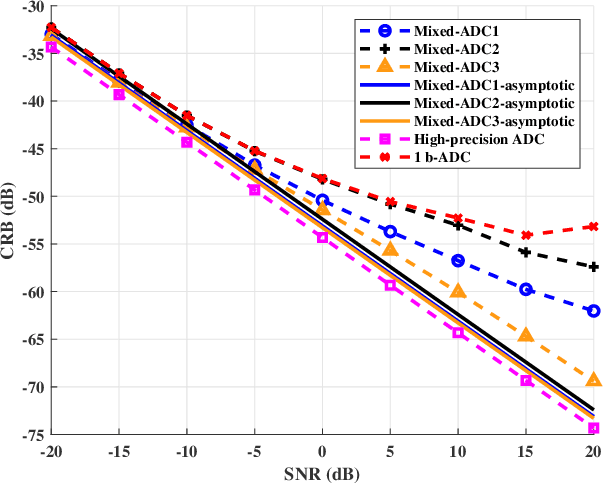
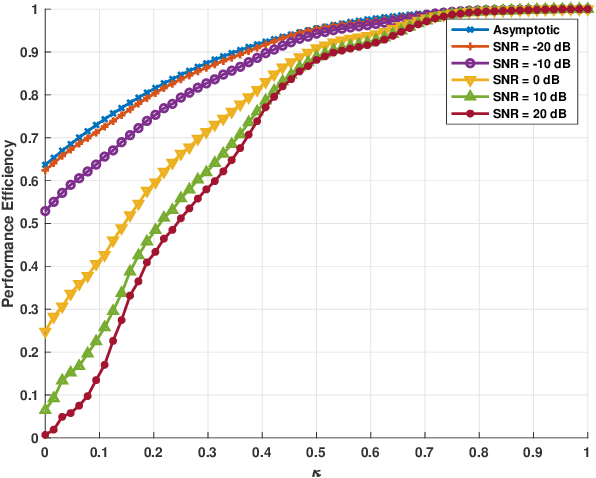
We consider a mixed analog-to-digital converter (ADC) based architecture consisting of high-precision and one-bit ADCs with the antenna-varying threshold for direction of arrival (DOA) estimation using a uniform linear array (ULA), which utilizes fixed but different thresholds for one-bit ADCs across different receive antennas. The Cram{\'e}r-Rao bound (CRB) with the antenna-varying threshold is obtained. Then based on the lower bound of the CRB, we derive the asymptotic CRB of the DOA, which depends on the placement of mixed-ADC. Our analysis shows that distributing high-precision ADCs evenly around the two edges of the ULA yields improved performance. This result can be extended to a more general case where the ULA is equipped with two types of ADCs with different quantization precisions. To efficiently obtain the maximum likelihood DOA estimates, we propose a two-step algorithm. Firstly, we formulate the model as a sparse signal representation problem, and modify the sparse learning via iterative minimization (SLIM) approach to the mixed-ADC based DOA estimation. In the second step, we use the relaxation-based approach to cyclically refine the estimates of SLIM, further enhancing the DOA estimation performance. Numerical examples are presented to demonstrate the validity of the CRB analysis and the effectiveness of our methods.
Optimal Mixed-ADC arrangement for DOA Estimation via CRB using ULA
Mar 27, 2023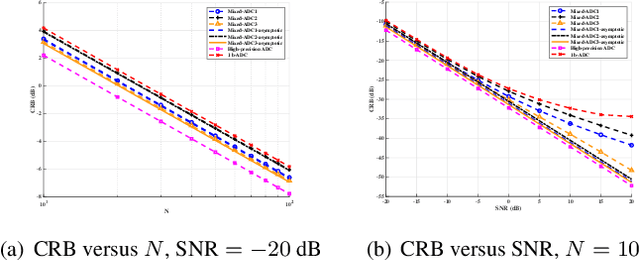
We consider a mixed analog-to-digital converter (ADC) based architecture for direction of arrival (DOA) estimation using a uniform linear array (ULA). We derive the Cram{\'e}r-Rao bound (CRB) of the DOA under the optimal time-varying threshold, and find that the asymptotic CRB is related to the arrangement of high-precision and one-bit ADCs for a fixed number of ADCs. Then, a new concept called ``mixed-precision arrangement" is proposed. It is proven that better performance for DOA estimation is achieved when high-precision ADCs are distributed evenly around the edges of the ULA. This result can be extended to a more general case where the ULA is equipped with various precision ADCs. Simulation results show the validity of the asymptotic CRB and better performance under the optimal mixed-precision arrangement.