 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Ultrasound Robotic System based on Deep Learning for Gas and Arc Hazard Detection in Manufacturing
Feb 08, 2025



Gas leaks and arc discharges present significant risks in industrial environments, requiring robust detection systems to ensure safety and operational efficiency. Inspired by human protocols that combine visual identification with acoustic verification, this study proposes a deep learning-based robotic system for autonomously detecting and classifying gas leaks and arc discharges in manufacturing settings. The system is designed to execute all experimental tasks entirely onboard the robot. Utilizing a 112-channel acoustic camera operating at a 96 kHz sampling rate to capture ultrasonic frequencies, the system processes real-world datasets recorded in diverse industrial scenarios. These datasets include multiple gas leak configurations (e.g., pinhole, open end) and partial discharge types (Corona, Surface, Floating) under varying environmental noise conditions. Proposed system integrates visual detection and a beamforming-enhanced acoustic analysis pipeline. Signals are transformed using STFT and refined through Gamma Correction, enabling robust feature extraction. An Inception-inspired CNN further classifies hazards, achieving 99% gas leak detection accuracy. The system not only detects individual hazard sources but also enhances classification reliability by fusing multi-modal data from both vision and acoustic sensors. When tested in reverberation and noise-augmented environments, the system outperformed conventional models by up to 44%p, with experimental tasks meticulously designed to ensure fairness and reproducibility. Additionally, the system is optimized for real-time deployment, maintaining an inference time of 2.1 seconds on a mobile robotic platform. By emulating human-like inspection protocols and integrating vision with acoustic modalities, this study presents an effective solution for industrial automation, significantly improving safety and operational reliability.
Power of Cooperative Supervision: Multiple Teachers Framework for Enhanced 3D Semi-Supervised Object Detection
May 31, 2024To ensure safe urban driving for autonomous platforms, it is crucial not only to develop high-performance object detection techniques but also to establish a diverse and representative dataset that captures various urban environments and object characteristics. To address these two issues, we have constructed a multi-class 3D LiDAR dataset reflecting diverse urban environments and object characteristics, and developed a robust 3D semi-supervised object detection (SSOD) based on a multiple teachers framework. This SSOD framework categorizes similar classes and assigns specialized teachers to each category. Through collaborative supervision among these category-specialized teachers, the student network becomes increasingly proficient, leading to a highly effective object detector. We propose a simple yet effective augmentation technique, Pie-based Point Compensating Augmentation (PieAug), to enable the teacher network to generate high-quality pseudo-labels. Extensive experiments on the WOD, KITTI, and our datasets validate the effectiveness of our proposed method and the quality of our dataset. Experimental results demonstrate that our approach consistently outperforms existing state-of-the-art 3D semi-supervised object detection methods across all datasets. We plan to release our multi-class LiDAR dataset and the source code available on our Github repository in the near future.
Co-occurrence matrix analysis-based semi-supervised training for object detection
Feb 20, 2018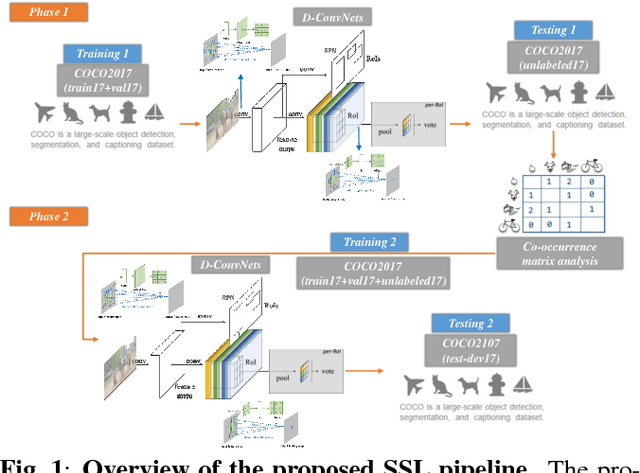
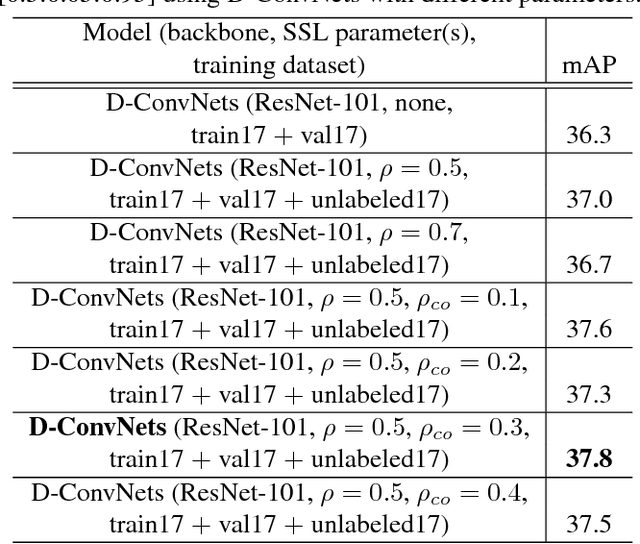

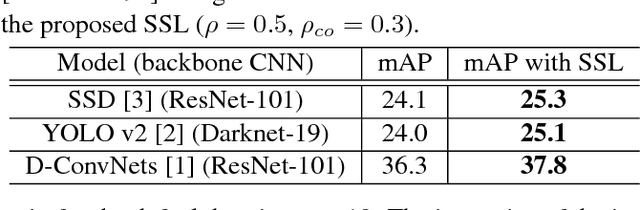
One of the most important factors in training object recognition networks using convolutional neural networks (CNNs) is the provision of annotated data accompanying human judgment. Particularly, in object detection or semantic segmentation, the annotation process requires considerable human effort. In this paper, we propose a semi-supervised learning (SSL)-based training methodology for object detection, which makes use of automatic labeling of un-annotated data by applying a network previously trained from an annotated dataset. Because an inferred label by the trained network is dependent on the learned parameters, it is often meaningless for re-training the network. To transfer a valuable inferred label to the unlabeled data, we propose a re-alignment method based on co-occurrence matrix analysis that takes into account one-hot-vector encoding of the estimated label and the correlation between the objects in the image. We used an MS-COCO detection dataset to verify the performance of the proposed SSL method and deformable neural networks (D-ConvNets) as an object detector for basic training. The performance of the existing state-of-the-art detectors (DConvNets, YOLO v2, and single shot multi-box detector (SSD)) can be improved by the proposed SSL method without using the additional model parameter or modifying the network architecture.