 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Contrastive Learning to Unsupervised Coreset Selection
Paper and Code
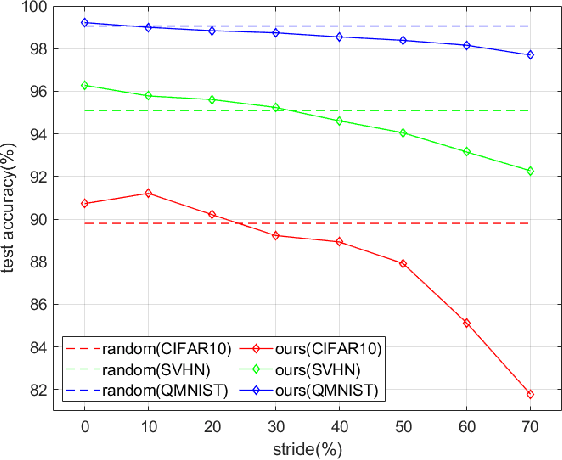
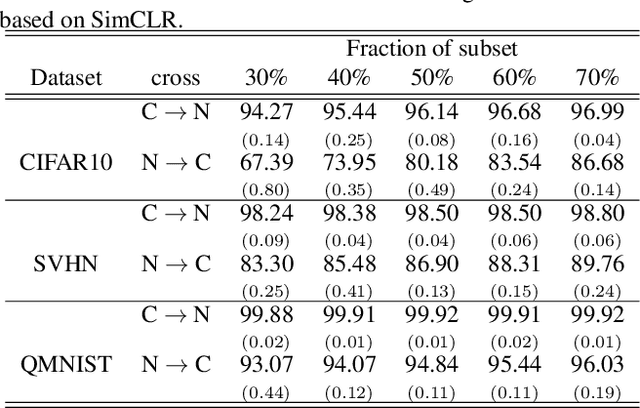
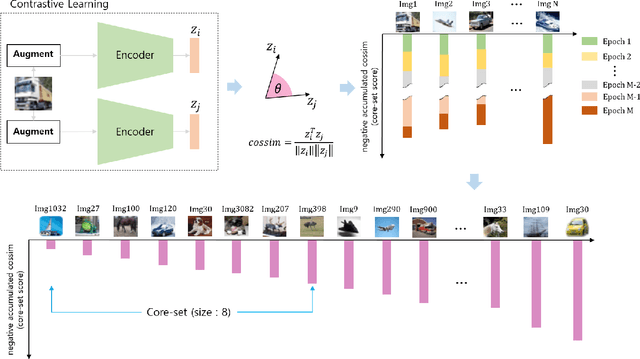
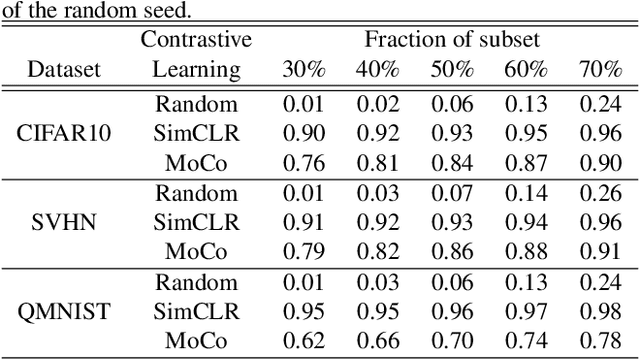
Self-supervised contrastive learning offers a means of learning informative features from a pool of unlabeled data. In this paper, we delve into another useful approach -- providing a way of selecting a core-set that is entirely unlabeled. In this regard, contrastive learning, one of a large number of self-supervised methods, was recently proposed and has consistently delivered the highest performance. This prompted us to choose two leading methods for contrastive learning: the simple framework for contrastive learning of visual representations (SimCLR) and the momentum contrastive (MoCo) learning framework. We calculated the cosine similarities for each example of an epoch for the entire duration of the contrastive learning process and subsequently accumulated the cosine-similarity values to obtain the coreset score. Our assumption was that an sample with low similarity would likely behave as a coreset. Compared with existing coreset selection methods with labels, our approach reduced the cost associated with human annotation. The unsupervised method implemented in this study for coreset selection obtained improved results over a randomly chosen subset, and were comparable to existing supervised coreset selection on various classification datasets (e.g., CIFAR, SVHN, and QMNIST).