 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Map Guided Synthesis of Wireless Capsule Endoscopy Images using Diffusion Models
Nov 10, 2023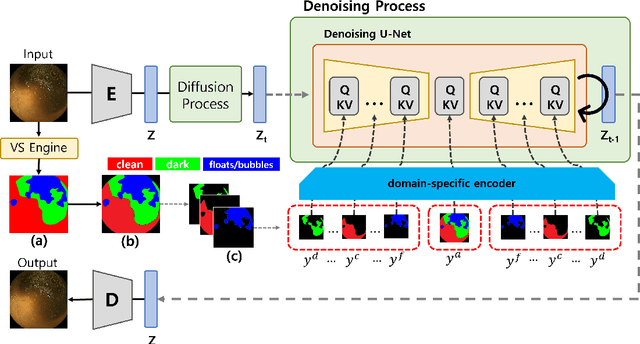
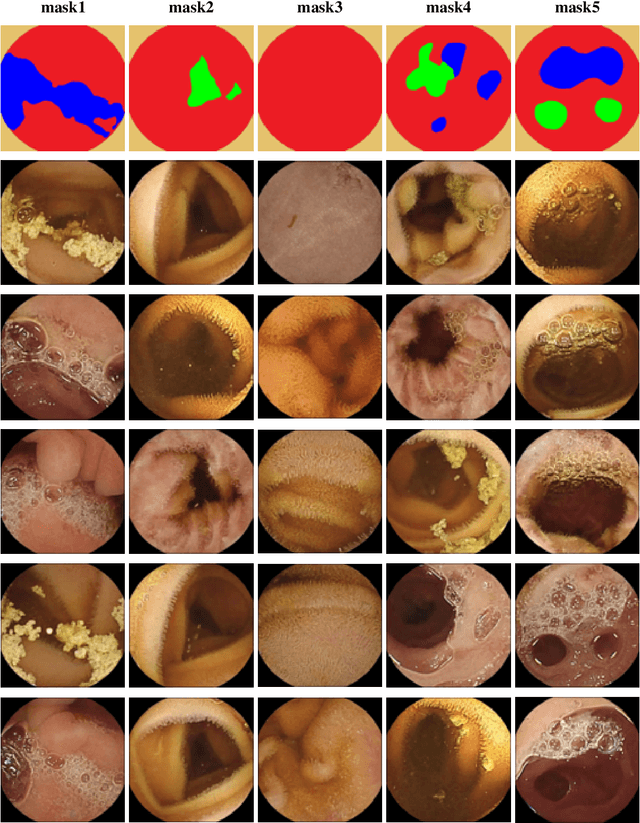
Wireless capsule endoscopy (WCE) is a non-invasive method for visualizing the gastrointestinal (GI) tract, crucial for diagnosing GI tract diseases. However, interpreting WCE results can be time-consuming and tiring. Existing studies have employed deep neural networks (DNNs) for automatic GI tract lesion detection, but acquiring sufficient training examples, particularly due to privacy concerns, remains a challenge. Public WCE databases lack diversity and quantity. To address this, we propose a novel approach leveraging generative models, specifically the diffusion model (DM), for generating diverse WCE images. Our model incorporates semantic map resulted from visualization scale (VS) engine, enhancing the controllability and diversity of generated images. We evaluate our approach using visual inspection and visual Turing tests, demonstrating its effectiveness in generating realistic and diverse WCE images.
Rethinking Query, Key, and Value Embedding in Vision Transformer under Tiny Model Constraints
Nov 19, 2021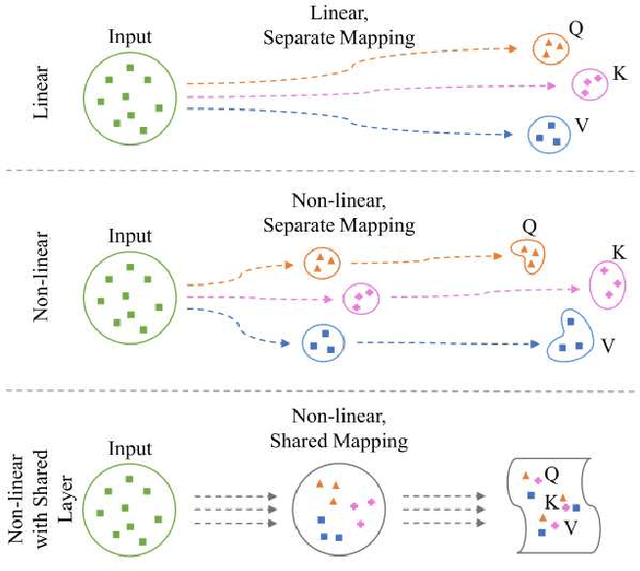
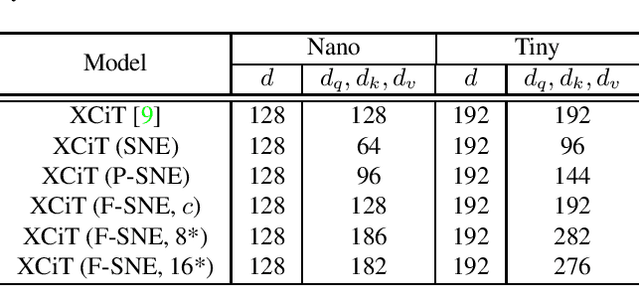
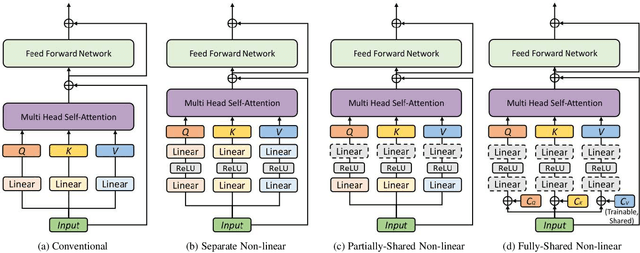
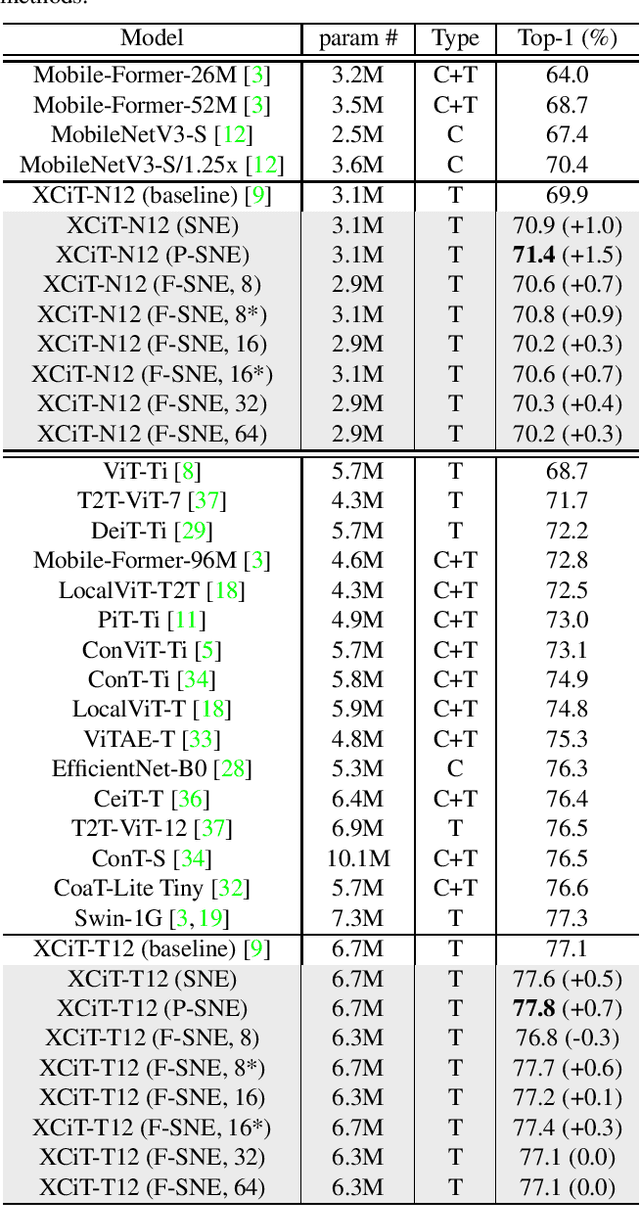
A vision transformer (ViT) is the dominant model in the computer vision field. Despite numerous studies that mainly focus on dealing with inductive bias and complexity, there remains the problem of finding better transformer networks. For example, conventional transformer-based models usually use a projection layer for each query (Q), key (K), and value (V) embedding before multi-head self-attention. Insufficient consideration of semantic $Q, K$, and $V$ embedding may lead to a performance drop. In this paper, we propose three types of structures for $Q$, $K$, and $V$ embedding. The first structure utilizes two layers with ReLU, which is a non-linear embedding for $Q, K$, and $V$. The second involves sharing one of the non-linear layers to share knowledge among $Q, K$, and $V$. The third proposed structure shares all non-linear layers with code parameters. The codes are trainable, and the values determine the embedding process to be performed among $Q$, $K$, and $V$. Hence, we demonstrate the superior image classification performance of the proposed approaches in experiments compared to several state-of-the-art approaches. The proposed method achieved $71.4\%$ with a few parameters (of $3.1M$) on the ImageNet-1k dataset compared to that required by the original transformer model of XCiT-N12 ($69.9\%$). Additionally, the method achieved $93.3\%$ with only $2.9M$ parameters in transfer learning on average for the CIFAR-10, CIFAR-100, Stanford Cars datasets, and STL-10 datasets, which is better than the accuracy of $92.2\%$ obtained via the original XCiT-N12 model.
Extending Contrastive Learning to Unsupervised Coreset Selection
Mar 05, 2021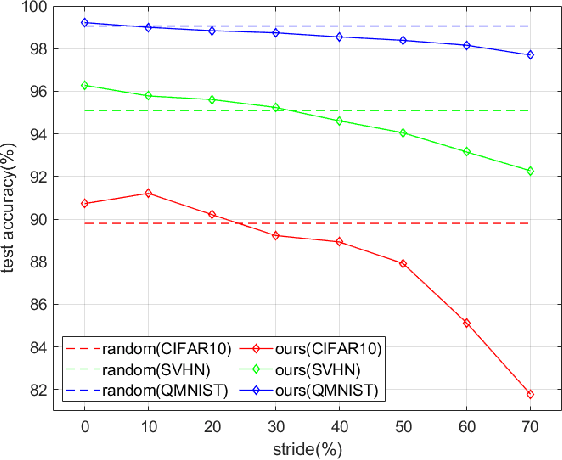
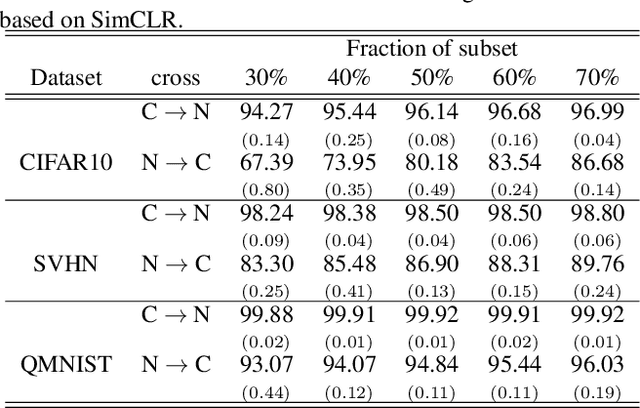
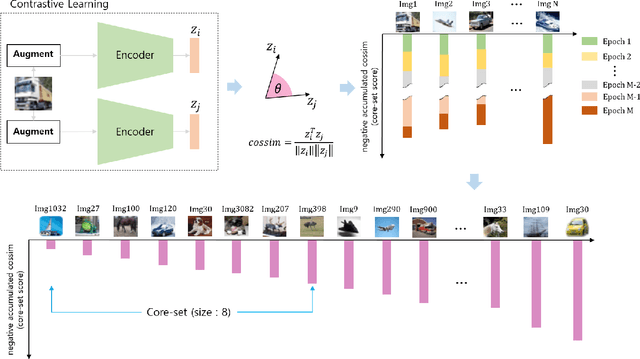
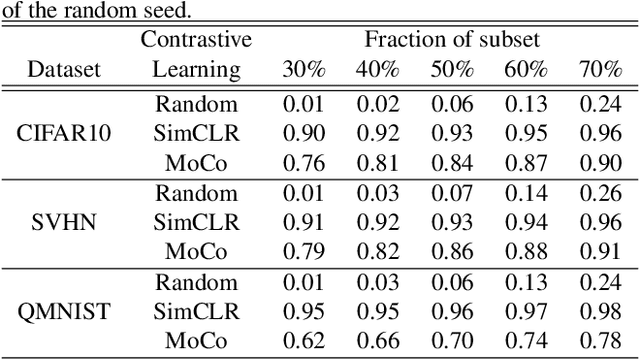
Self-supervised contrastive learning offers a means of learning informative features from a pool of unlabeled data. In this paper, we delve into another useful approach -- providing a way of selecting a core-set that is entirely unlabeled. In this regard, contrastive learning, one of a large number of self-supervised methods, was recently proposed and has consistently delivered the highest performance. This prompted us to choose two leading methods for contrastive learning: the simple framework for contrastive learning of visual representations (SimCLR) and the momentum contrastive (MoCo) learning framework. We calculated the cosine similarities for each example of an epoch for the entire duration of the contrastive learning process and subsequently accumulated the cosine-similarity values to obtain the coreset score. Our assumption was that an sample with low similarity would likely behave as a coreset. Compared with existing coreset selection methods with labels, our approach reduced the cost associated with human annotation. The unsupervised method implemented in this study for coreset selection obtained improved results over a randomly chosen subset, and were comparable to existing supervised coreset selection on various classification datasets (e.g., CIFAR, SVHN, and QMNIST).
Less-forgetful Learning for Domain Expansion in Deep Neural Networks
Nov 16, 2017

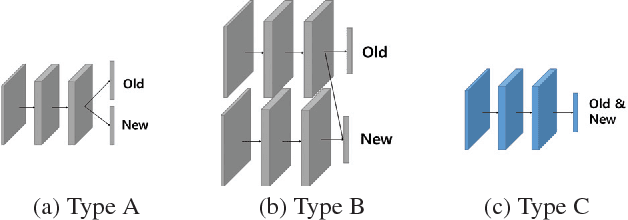

Expanding the domain that deep neural network has already learned without accessing old domain data is a challenging task because deep neural networks forget previously learned information when learning new data from a new domain. In this paper, we propose a less-forgetful learning method for the domain expansion scenario. While existing domain adaptation techniques solely focused on adapting to new domains, the proposed technique focuses on working well with both old and new domains without needing to know whether the input is from the old or new domain. First, we present two naive approaches which will be problematic, then we provide a new method using two proposed properties for less-forgetful learning. Finally, we prove the effectiveness of our method through experiments on image classification tasks. All datasets used in the paper, will be released on our website for someone's follow-up study.
Less-forgetting Learning in Deep Neural Networks
Jul 01, 2016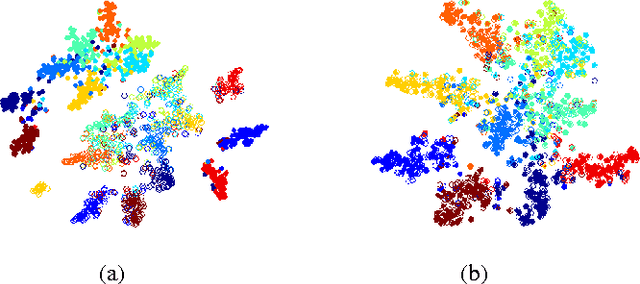
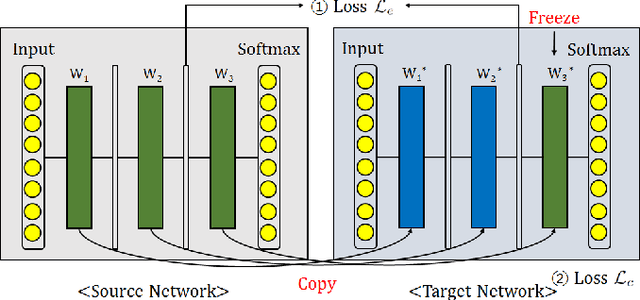

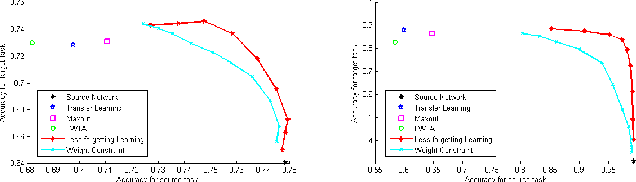
A catastrophic forgetting problem makes deep neural networks forget the previously learned information, when learning data collected in new environments, such as by different sensors or in different light conditions. This paper presents a new method for alleviating the catastrophic forgetting problem. Unlike previous research, our method does not use any information from the source domain. Surprisingly, our method is very effective to forget less of the information in the source domain, and we show the effectiveness of our method using several experiments. Furthermore, we observed that the forgetting problem occurs between mini-batches when performing general training processes using stochastic gradient descent methods, and this problem is one of the factors that degrades generalization performance of the network. We also try to solve this problem using the proposed method. Finally, we show our less-forgetting learning method is also helpful to improve the performance of deep neural networks in terms of recognition rates.