 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistorting Embedding Space for Safety: A Defense Mechanism for Adversarially Robust Diffusion Models
Jan 31, 2025



Text-to-image diffusion models show remarkable generation performance following text prompts, but risk generating Not Safe For Work (NSFW) contents from unsafe prompts. Existing approaches, such as prompt filtering or concept unlearning, fail to defend against adversarial attacks while maintaining benign image quality. In this paper, we propose a novel approach called Distorting Embedding Space (DES), a text encoder-based defense mechanism that effectively tackles these issues through innovative embedding space control. DES transforms unsafe embeddings, extracted from a text encoder using unsafe prompts, toward carefully calculated safe embedding regions to prevent unsafe contents generation, while reproducing the original safe embeddings. DES also neutralizes the nudity embedding, extracted using prompt ``nudity", by aligning it with neutral embedding to enhance robustness against adversarial attacks. These methods ensure both robust defense and high-quality image generation. Additionally, DES can be adopted in a plug-and-play manner and requires zero inference overhead, facilitating its deployment. Extensive experiments on diverse attack types, including black-box and white-box scenarios, demonstrate DES's state-of-the-art performance in both defense capability and benign image generation quality. Our model is available at https://github.com/aei13/DES.
Rethinking Query, Key, and Value Embedding in Vision Transformer under Tiny Model Constraints
Nov 19, 2021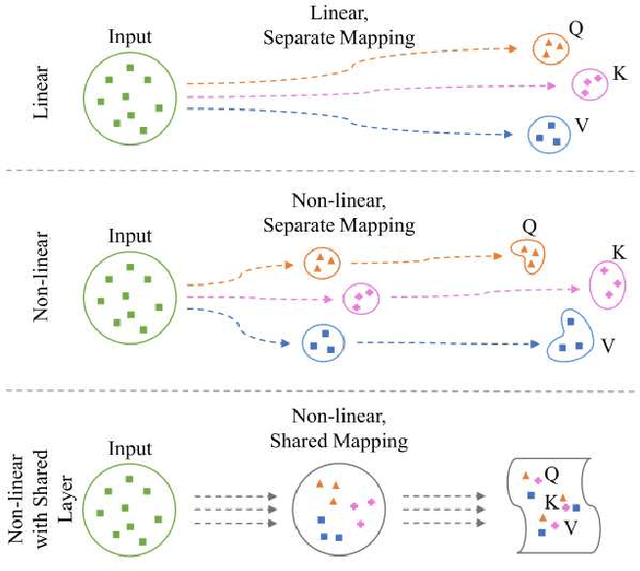
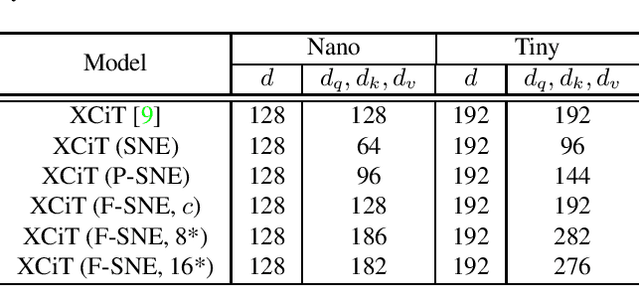
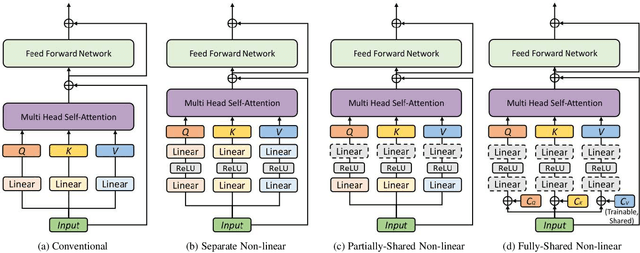
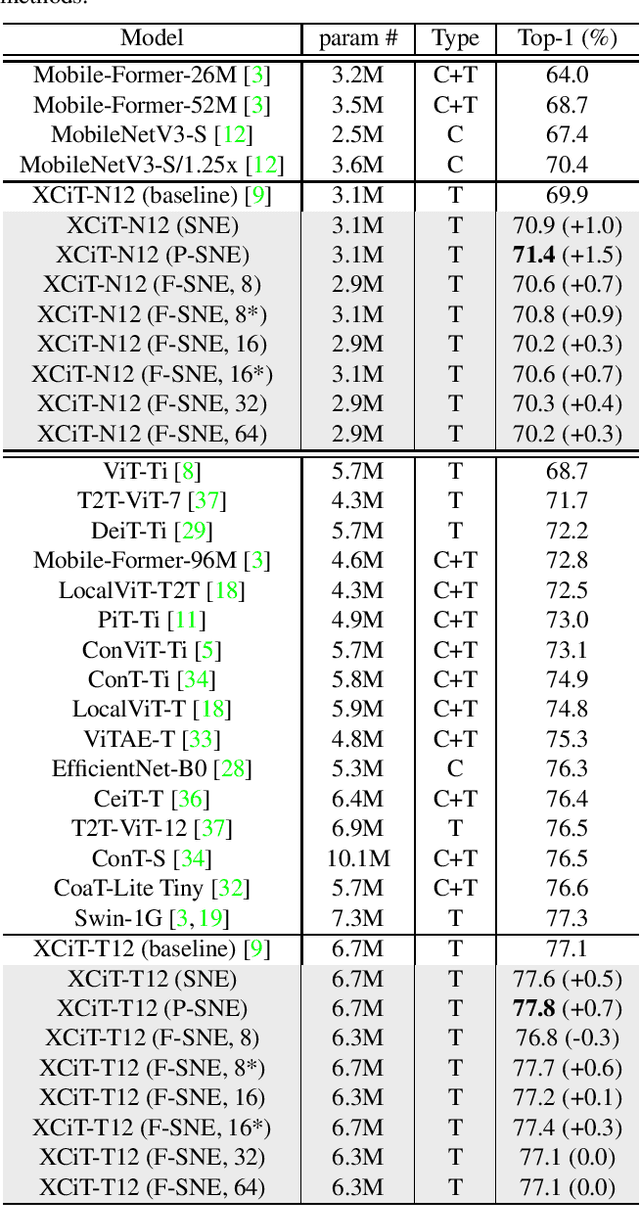
A vision transformer (ViT) is the dominant model in the computer vision field. Despite numerous studies that mainly focus on dealing with inductive bias and complexity, there remains the problem of finding better transformer networks. For example, conventional transformer-based models usually use a projection layer for each query (Q), key (K), and value (V) embedding before multi-head self-attention. Insufficient consideration of semantic $Q, K$, and $V$ embedding may lead to a performance drop. In this paper, we propose three types of structures for $Q$, $K$, and $V$ embedding. The first structure utilizes two layers with ReLU, which is a non-linear embedding for $Q, K$, and $V$. The second involves sharing one of the non-linear layers to share knowledge among $Q, K$, and $V$. The third proposed structure shares all non-linear layers with code parameters. The codes are trainable, and the values determine the embedding process to be performed among $Q$, $K$, and $V$. Hence, we demonstrate the superior image classification performance of the proposed approaches in experiments compared to several state-of-the-art approaches. The proposed method achieved $71.4\%$ with a few parameters (of $3.1M$) on the ImageNet-1k dataset compared to that required by the original transformer model of XCiT-N12 ($69.9\%$). Additionally, the method achieved $93.3\%$ with only $2.9M$ parameters in transfer learning on average for the CIFAR-10, CIFAR-100, Stanford Cars datasets, and STL-10 datasets, which is better than the accuracy of $92.2\%$ obtained via the original XCiT-N12 model.