 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanked Entropy Minimization for Continual Test-Time Adaptation
May 22, 2025



Test-time adaptation aims to adapt to realistic environments in an online manner by learning during test time. Entropy minimization has emerged as a principal strategy for test-time adaptation due to its efficiency and adaptability. Nevertheless, it remains underexplored in continual test-time adaptation, where stability is more important. We observe that the entropy minimization method often suffers from model collapse, where the model converges to predicting a single class for all images due to a trivial solution. We propose ranked entropy minimization to mitigate the stability problem of the entropy minimization method and extend its applicability to continuous scenarios. Our approach explicitly structures the prediction difficulty through a progressive masking strategy. Specifically, it gradually aligns the model's probability distributions across different levels of prediction difficulty while preserving the rank order of entropy. The proposed method is extensively evaluated across various benchmarks, demonstrating its effectiveness through empirical results. Our code is available at https://github.com/pilsHan/rem
OurDB: Ouroboric Domain Bridging for Multi-Target Domain Adaptive Semantic Segmentation
Mar 18, 2024

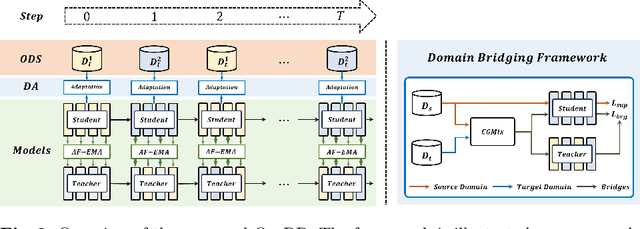

Multi-target domain adaptation (MTDA) for semantic segmentation poses a significant challenge, as it involves multiple target domains with varying distributions. The goal of MTDA is to minimize the domain discrepancies among a single source and multi-target domains, aiming to train a single model that excels across all target domains. Previous MTDA approaches typically employ multiple teacher architectures, where each teacher specializes in one target domain to simplify the task. However, these architectures hinder the student model from fully assimilating comprehensive knowledge from all target-specific teachers and escalate training costs with increasing target domains. In this paper, we propose an ouroboric domain bridging (OurDB) framework, offering an efficient solution to the MTDA problem using a single teacher architecture. This framework dynamically cycles through multiple target domains, aligning each domain individually to restrain the biased alignment problem, and utilizes Fisher information to minimize the forgetting of knowledge from previous target domains. We also propose a context-guided class-wise mixup (CGMix) that leverages contextual information tailored to diverse target contexts in MTDA. Experimental evaluations conducted on four urban driving datasets (i.e., GTA5, Cityscapes, IDD, and Mapillary) demonstrate the superiority of our method over existing state-of-the-art approaches.
Semantic Prompting with Image-Token for Continual Learning
Mar 18, 2024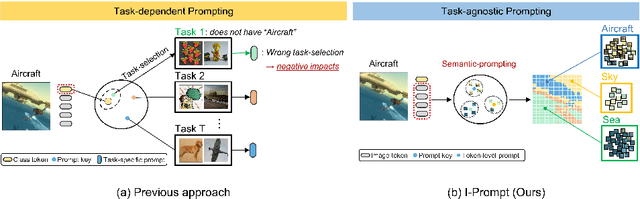
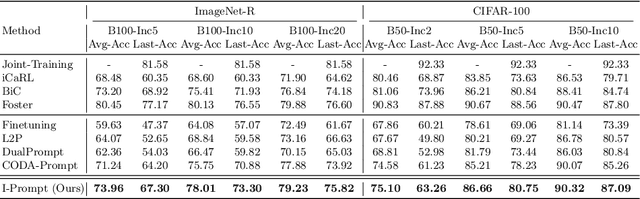
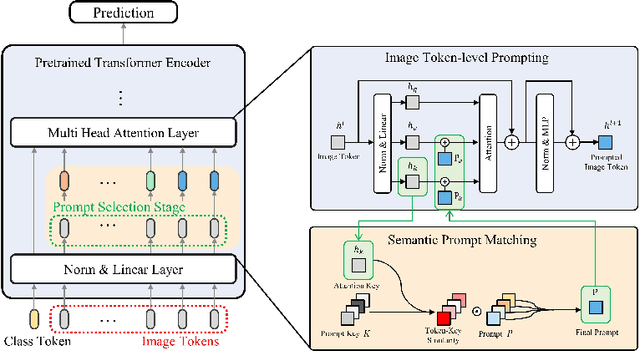
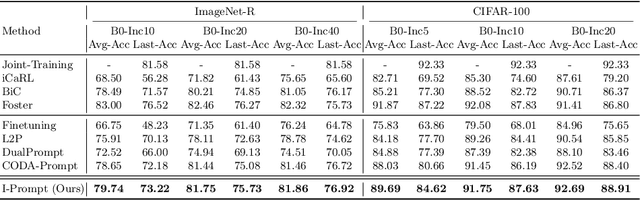
Continual learning aims to refine model parameters for new tasks while retaining knowledge from previous tasks. Recently, prompt-based learning has emerged to leverage pre-trained models to be prompted to learn subsequent tasks without the reliance on the rehearsal buffer. Although this approach has demonstrated outstanding results, existing methods depend on preceding task-selection process to choose appropriate prompts. However, imperfectness in task-selection may lead to negative impacts on the performance particularly in the scenarios where the number of tasks is large or task distributions are imbalanced. To address this issue, we introduce I-Prompt, a task-agnostic approach focuses on the visual semantic information of image tokens to eliminate task prediction. Our method consists of semantic prompt matching, which determines prompts based on similarities between tokens, and image token-level prompting, which applies prompts directly to image tokens in the intermediate layers. Consequently, our method achieves competitive performance on four benchmarks while significantly reducing training time compared to state-of-the-art methods. Moreover, we demonstrate the superiority of our method across various scenarios through extensive experiments.
D3T: Distinctive Dual-Domain Teacher Zigzagging Across RGB-Thermal Gap for Domain-Adaptive Object Detection
Mar 14, 2024
Domain adaptation for object detection typically entails transferring knowledge from one visible domain to another visible domain. However, there are limited studies on adapting from the visible to the thermal domain, because the domain gap between the visible and thermal domains is much larger than expected, and traditional domain adaptation can not successfully facilitate learning in this situation. To overcome this challenge, we propose a Distinctive Dual-Domain Teacher (D3T) framework that employs distinct training paradigms for each domain. Specifically, we segregate the source and target training sets for building dual-teachers and successively deploy exponential moving average to the student model to individual teachers of each domain. The framework further incorporates a zigzag learning method between dual teachers, facilitating a gradual transition from the visible to thermal domains during training. We validate the superiority of our method through newly designed experimental protocols with well-known thermal datasets, i.e., FLIR and KAIST. Source code is available at https://github.com/EdwardDo69/D3T .
Switching Temporary Teachers for Semi-Supervised Semantic Segmentation
Oct 28, 2023
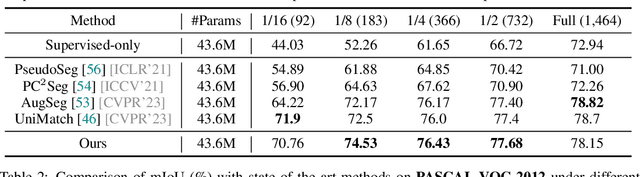


The teacher-student framework, prevalent in semi-supervised semantic segmentation, mainly employs the exponential moving average (EMA) to update a single teacher's weights based on the student's. However, EMA updates raise a problem in that the weights of the teacher and student are getting coupled, causing a potential performance bottleneck. Furthermore, this problem may become more severe when training with more complicated labels such as segmentation masks but with few annotated data. This paper introduces Dual Teacher, a simple yet effective approach that employs dual temporary teachers aiming to alleviate the coupling problem for the student. The temporary teachers work in shifts and are progressively improved, so consistently prevent the teacher and student from becoming excessively close. Specifically, the temporary teachers periodically take turns generating pseudo-labels to train a student model and maintain the distinct characteristics of the student model for each epoch. Consequently, Dual Teacher achieves competitive performance on the PASCAL VOC, Cityscapes, and ADE20K benchmarks with remarkably shorter training times than state-of-the-art methods. Moreover, we demonstrate that our approach is model-agnostic and compatible with both CNN- and Transformer-based models. Code is available at \url{https://github.com/naver-ai/dual-teacher}.
SRIL: Selective Regularization for Class-Incremental Learning
May 09, 2023
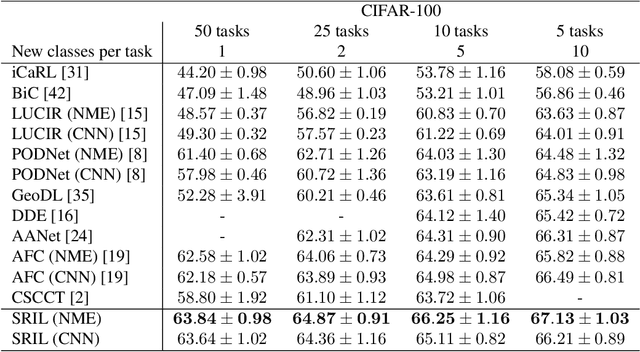

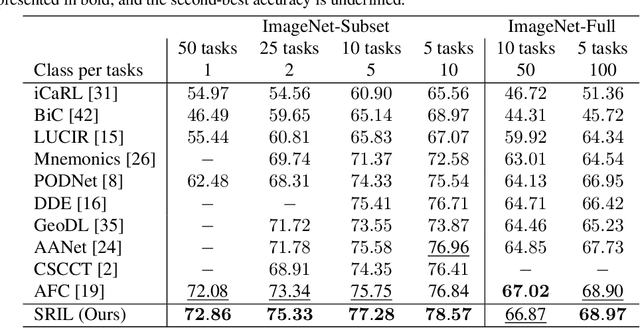
Human intelligence gradually accepts new information and accumulates knowledge throughout the lifespan. However, deep learning models suffer from a catastrophic forgetting phenomenon, where they forget previous knowledge when acquiring new information. Class-Incremental Learning aims to create an integrated model that balances plasticity and stability to overcome this challenge. In this paper, we propose a selective regularization method that accepts new knowledge while maintaining previous knowledge. We first introduce an asymmetric feature distillation method for old and new classes inspired by cognitive science, using the gradient of classification and knowledge distillation losses to determine whether to perform pattern completion or pattern separation. We also propose a method to selectively interpolate the weight of the previous model for a balance between stability and plasticity, and we adjust whether to transfer through model confidence to ensure the performance of the previous class and enable exploratory learning. We validate the effectiveness of the proposed method, which surpasses the performance of existing methods through extensive experimental protocols using CIFAR-100, ImageNet-Subset, and ImageNet-Full.
Contrastive Vicinal Space for Unsupervised Domain Adaptation
Dec 05, 2021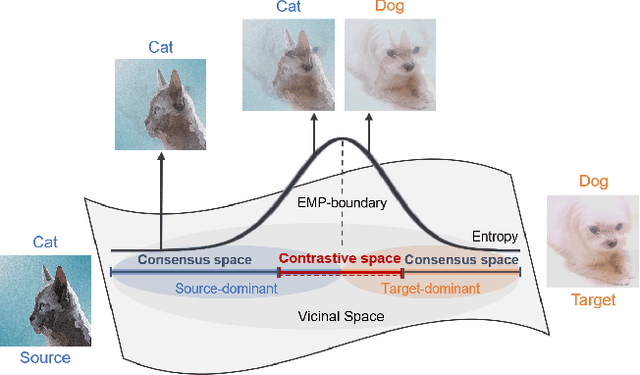



Utilizing vicinal space between the source and target domains is one of the recent unsupervised domain adaptation approaches. However, the problem of the equilibrium collapse of labels, where the source labels are dominant over the target labels in the predictions of vicinal instances, has never been addressed. In this paper, we propose an instance-wise minimax strategy that minimizes the entropy of high uncertainty instances in the vicinal space to tackle it. We divide the vicinal space into two subspaces through the solution of the minimax problem: contrastive space and consensus space. In the contrastive space, inter-domain discrepancy is mitigated by constraining instances to have contrastive views and labels, and the consensus space reduces the confusion between intra-domain categories. The effectiveness of our method is demonstrated on the public benchmarks, including Office-31, Office-Home, and VisDA-C, which achieve state-of-the-art performances. We further show that our method outperforms current state-of-the-art methods on PACS, which indicates our instance-wise approach works well for multi-source domain adaptation as well.
FixBi: Bridging Domain Spaces for Unsupervised Domain Adaptation
Nov 18, 2020
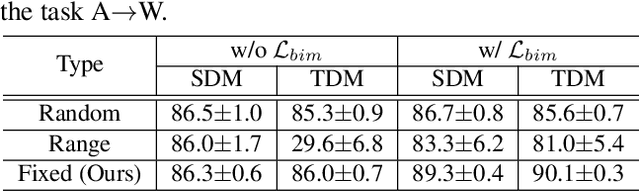
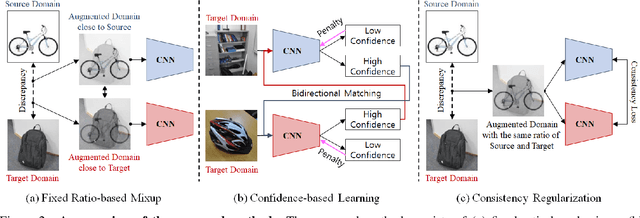

Unsupervised domain adaptation (UDA) methods for learning domain invariant representations have achieved remarkable progress. However, few studies have been conducted on the case of large domain discrepancies between a source and a target domain. In this paper, we propose a UDA method that effectively handles such large domain discrepancies. We introduce a fixed ratio-based mixup to augment multiple intermediate domains between the source and target domain. From the augmented-domains, we train the source-dominant model and the target-dominant model that have complementary characteristics. Using our confidence-based learning methodologies, e.g., bidirectional matching with high-confidence predictions and self-penalization using low-confidence predictions, the models can learn from each other or from its own results. Through our proposed methods, the models gradually transfer domain knowledge from the source to the target domain. Extensive experiments demonstrate the superiority of our proposed method on three public benchmarks: Office-31, Office-Home, and VisDA-2017.
Densely Guided Knowledge Distillation using Multiple Teacher Assistants
Sep 18, 2020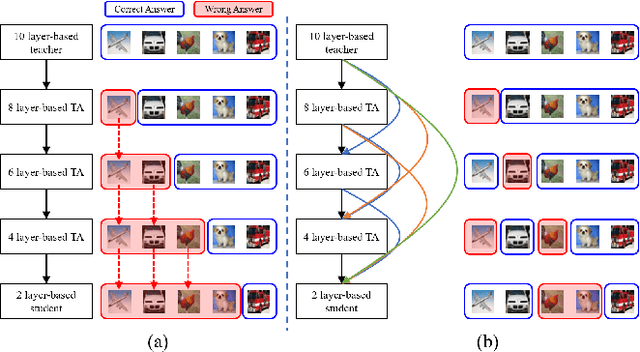


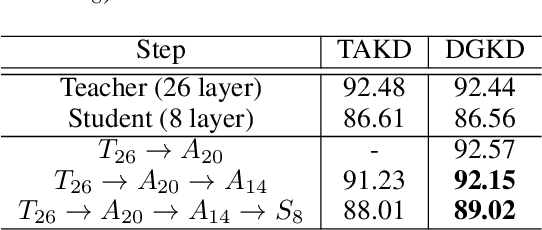
With the success of deep neural networks, knowledge distillation which guides the learning of a small student network from a large teacher network is being actively studied for model compression and transfer learning. However, few studies have been performed to resolve the poor learning issue of the student network when the student and teacher model sizes significantly differ. In this paper, we propose a densely guided knowledge distillation using multiple teacher assistants that gradually decrease the model size to efficiently bridge the gap between teacher and student networks. To stimulate more efficient learning of the student network, we guide each teacher assistant to every other smaller teacher assistant step by step. Specifically, when teaching a smaller teacher assistant at the next step, the existing larger teacher assistants from the previous step are used as well as the teacher network to increase the learning efficiency. Moreover, we design stochastic teaching where, for each mini-batch during training, a teacher or a teacher assistant is randomly dropped. This acts as a regularizer like dropout to improve the accuracy of the student network. Thus, the student can always learn rich distilled knowledge from multiple sources ranging from the teacher to multiple teacher assistants. We verified the effectiveness of the proposed method for a classification task using Cifar-10, Cifar-100, and Tiny ImageNet. We also achieved significant performance improvements with various backbone architectures such as a simple stacked convolutional neural network, ResNet, and WideResNet.