 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensely Guided Knowledge Distillation using Multiple Teacher Assistants
Sep 18, 2020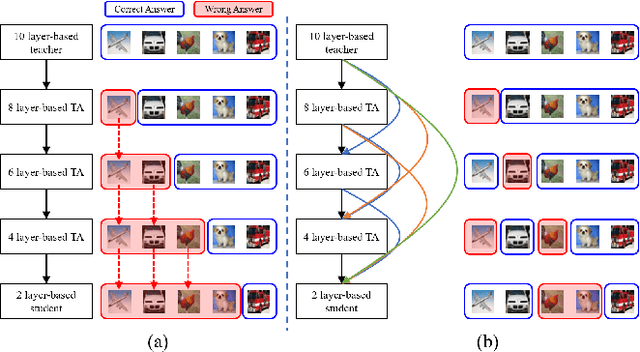


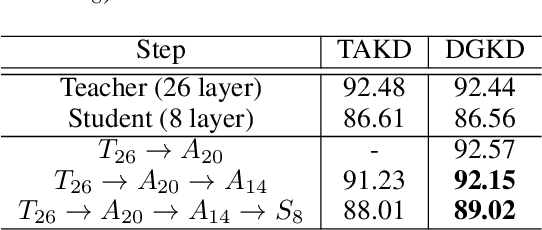
With the success of deep neural networks, knowledge distillation which guides the learning of a small student network from a large teacher network is being actively studied for model compression and transfer learning. However, few studies have been performed to resolve the poor learning issue of the student network when the student and teacher model sizes significantly differ. In this paper, we propose a densely guided knowledge distillation using multiple teacher assistants that gradually decrease the model size to efficiently bridge the gap between teacher and student networks. To stimulate more efficient learning of the student network, we guide each teacher assistant to every other smaller teacher assistant step by step. Specifically, when teaching a smaller teacher assistant at the next step, the existing larger teacher assistants from the previous step are used as well as the teacher network to increase the learning efficiency. Moreover, we design stochastic teaching where, for each mini-batch during training, a teacher or a teacher assistant is randomly dropped. This acts as a regularizer like dropout to improve the accuracy of the student network. Thus, the student can always learn rich distilled knowledge from multiple sources ranging from the teacher to multiple teacher assistants. We verified the effectiveness of the proposed method for a classification task using Cifar-10, Cifar-100, and Tiny ImageNet. We also achieved significant performance improvements with various backbone architectures such as a simple stacked convolutional neural network, ResNet, and WideResNet.
Pacemaker: Intermediate Teacher Knowledge Distillation For On-The-Fly Convolutional Neural Network
Mar 09, 2020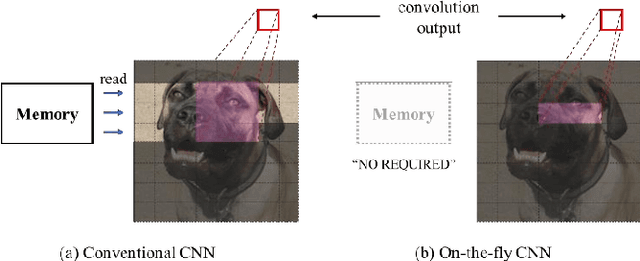



There is a need for an on-the-fly computational process with very low performance system such as system-on-chip (SoC) and embedded device etc. This paper presents pacemaker knowledge distillation as intermediate ensemble teacher to use convolutional neural network in these systems. For on-the-fly system, we consider student model using 1xN shape on-the-fly filter and teacher model using normal NxN shape filter. We note three points about training student model, caused by applying on-the-fly filter. First, same depth but unavoidable thin model compression. Second, the large capacity gap and parameter size gap due to only the horizontal field must be selected not the vertical receptive. Third, the performance instability and degradation of direct distilling. To solve these problems, we propose intermediate teacher, named pacemaker, for an on-the-fly student. So, student can be trained from pacemaker and original teacher step by step. Experiments prove our proposed method make significant performance (accuracy) improvements: on CIFAR100, 5.39% increased in WRN-40-4 than conventional knowledge distillation which shows even low performance than baseline. And we solve train instability, occurred when conventional knowledge distillation was applied without proposed method, by reducing deviation range by applying proposed method pacemaker knowledge distillation.