 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockwise Temporal-Spatial Pathway Network
Paper and Code
Aug 05, 2022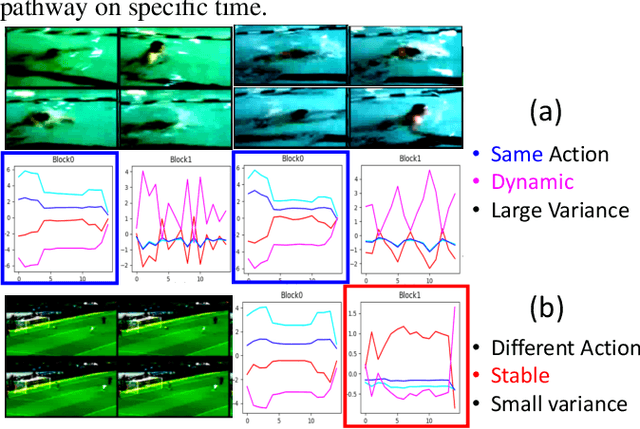
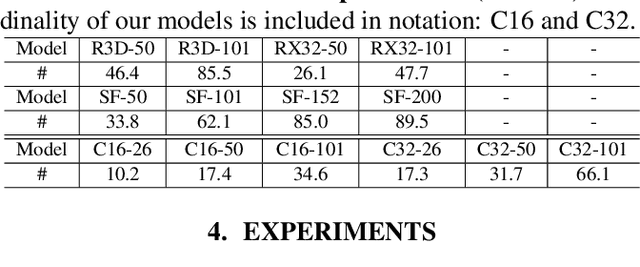
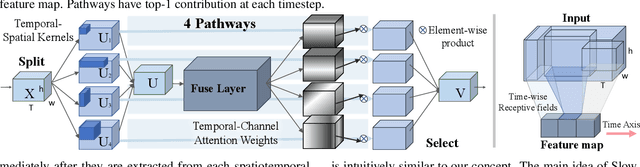
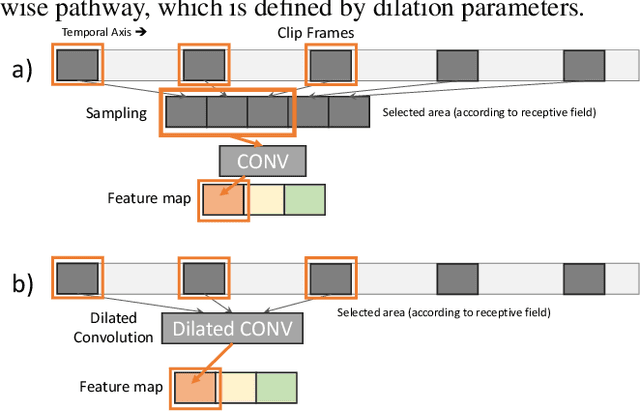
Algorithms for video action recognition should consider not only spatial information but also temporal relations, which remains challenging. We propose a 3D-CNN-based action recognition model, called the blockwise temporal-spatial path-way network (BTSNet), which can adjust the temporal and spatial receptive fields by multiple pathways. We designed a novel model inspired by an adaptive kernel selection-based model, which is an architecture for effective feature encoding that adaptively chooses spatial receptive fields for image recognition. Expanding this approach to the temporal domain, our model extracts temporal and channel-wise attention and fuses information on various candidate operations. For evaluation, we tested our proposed model on UCF-101, HMDB-51, SVW, and Epic-Kitchen datasets and showed that it generalized well without pretraining. BTSNet also provides interpretable visualization based on spatiotemporal channel-wise attention. We confirm that the blockwise temporal-spatial pathway supports a better representation for 3D convolutional blocks based on this visualization.