 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning with Augmentation-based Consistency Estimation
Paper and Code
Nov 05, 2020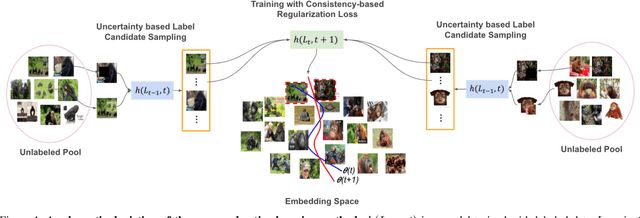
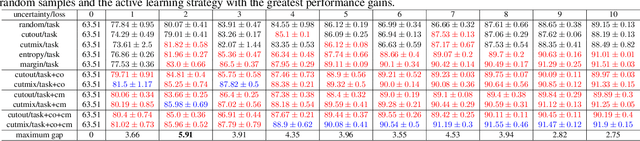
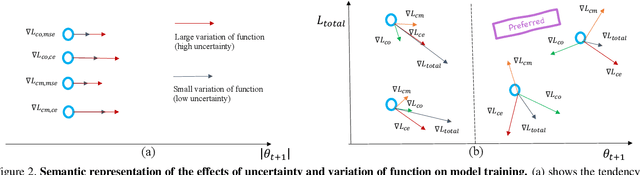

In active learning, the focus is mainly on the selection strategy of unlabeled data for enhancing the generalization capability of the next learning cycle. For this, various uncertainty measurement methods have been proposed. On the other hand, with the advent of data augmentation metrics as the regularizer on general deep learning, we notice that there can be a mutual influence between the method of unlabeled data selection and the data augmentation-based regularization techniques in active learning scenarios. Through various experiments, we confirmed that consistency-based regularization from analytical learning theory could affect the generalization capability of the classifier in combination with the existing uncertainty measurement method. By this fact, we propose a methodology to improve generalization ability, by applying data augmentation-based techniques to an active learning scenario. For the data augmentation-based regularization loss, we redefined cutout (co) and cutmix (cm) strategies as quantitative metrics and applied at both model training and unlabeled data selection steps. We have shown that the augmentation-based regularizer can lead to improved performance on the training step of active learning, while that same approach can be effectively combined with the uncertainty measurement metrics proposed so far. We used datasets such as FashionMNIST, CIFAR10, CIFAR100, and STL10 to verify the performance of the proposed active learning technique for multiple image classification tasks. Our experiments show consistent performance gains for each dataset and budget scenario.