 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Planning for Deep Neural Networks
Paper and Code
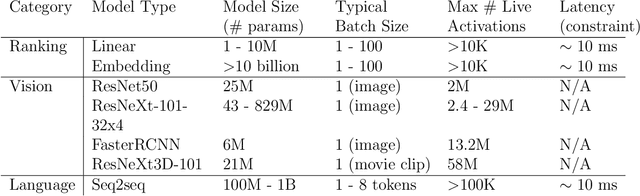
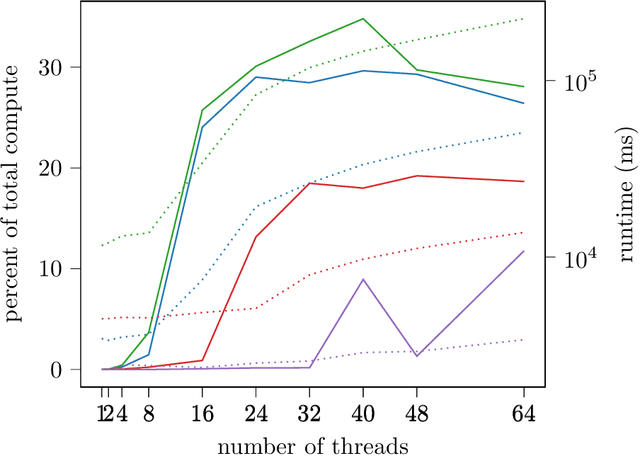
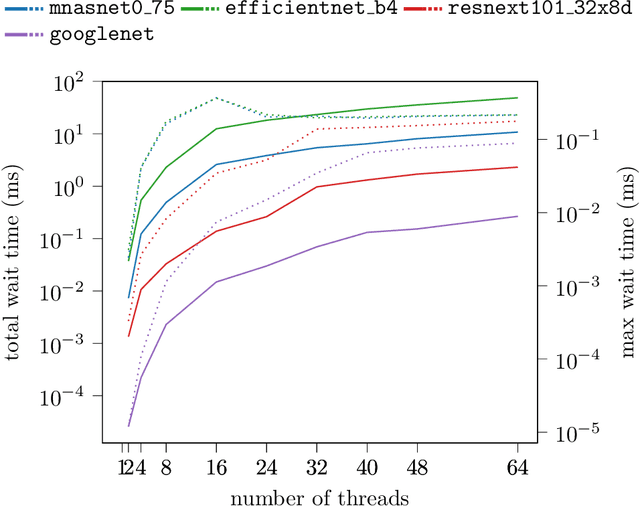
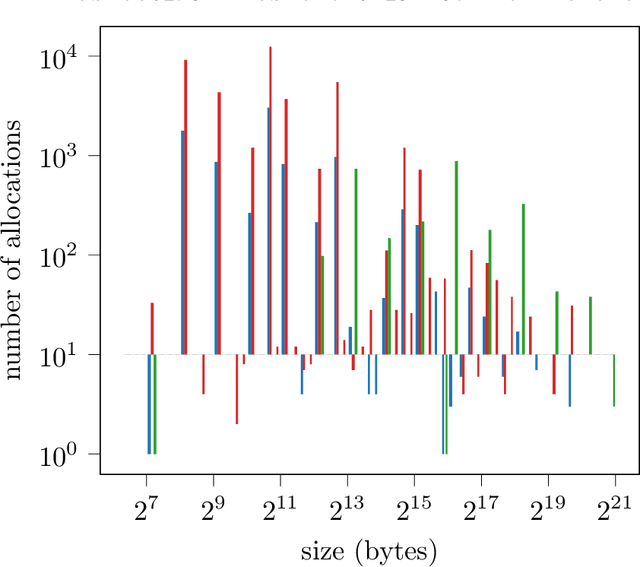
We study memory allocation patterns in DNNs during inference, in the context of large-scale systems. We observe that such memory allocation patterns, in the context of multi-threading, are subject to high latencies, due to \texttt{mutex} contention in the system memory allocator. Latencies incurred due to such \texttt{mutex} contention produce undesirable bottlenecks in user-facing services. Thus, we propose a "memorization" based technique, \texttt{MemoMalloc}, for optimizing overall latency, with only moderate increases in peak memory usage. Specifically, our technique consists of a runtime component, which captures all allocations and uniquely associates them with their high-level source operation, and a static analysis component, which constructs an efficient allocation "plan". We present an implementation of \texttt{MemoMalloc} in the PyTorch deep learning framework and evaluate memory consumption and execution performance on a wide range of DNN architectures. We find that \texttt{MemoMalloc} outperforms state-of-the-art general purpose memory allocators, with respect to DNN inference latency, by as much as 40\%.