 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models to Build and Execute Computational Workflows
Dec 12, 2023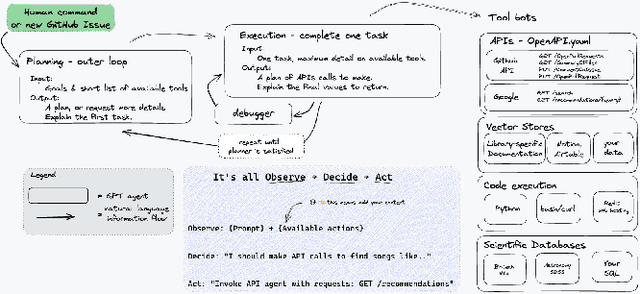
The recent development of large language models (LLMs) with multi-billion parameters, coupled with the creation of user-friendly application programming interfaces (APIs), has paved the way for automatically generating and executing code in response to straightforward human queries. This paper explores how these emerging capabilities can be harnessed to facilitate complex scientific workflows, eliminating the need for traditional coding methods. We present initial findings from our attempt to integrate Phyloflow with OpenAI's function-calling API, and outline a strategy for developing a comprehensive workflow management system based on these concepts.
FAIR AI Models in High Energy Physics
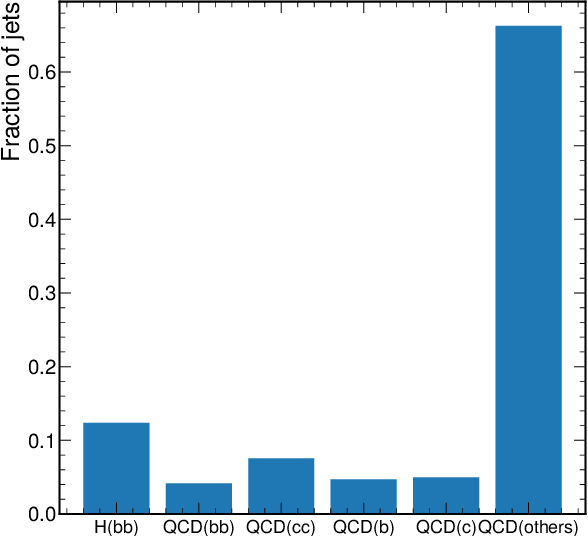
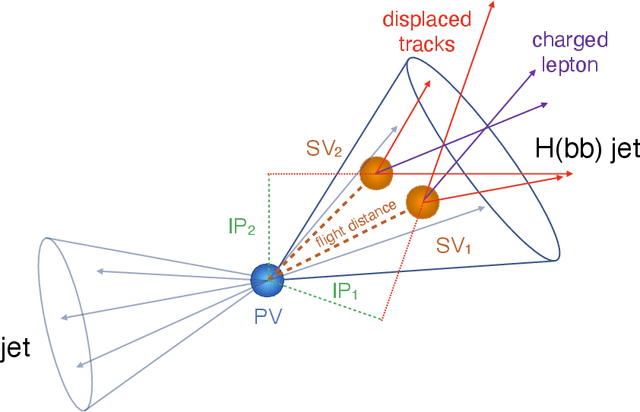
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
A FAIR and AI-ready Higgs Boson Decay Dataset
Aug 04, 2021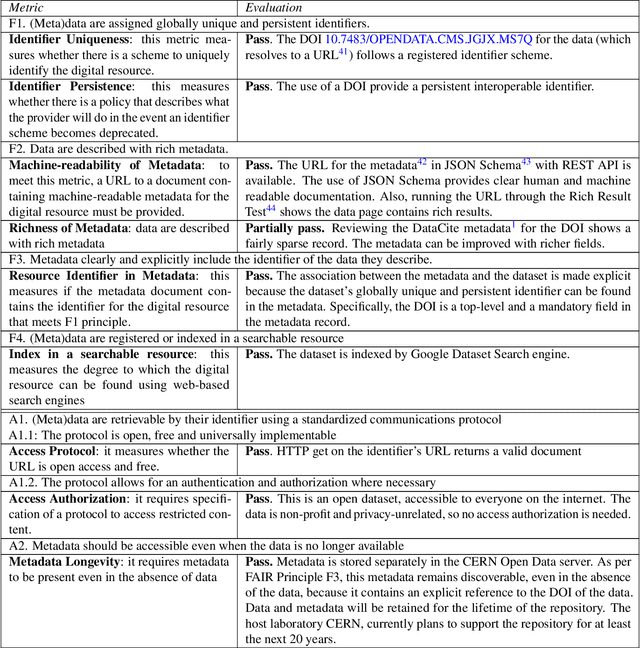
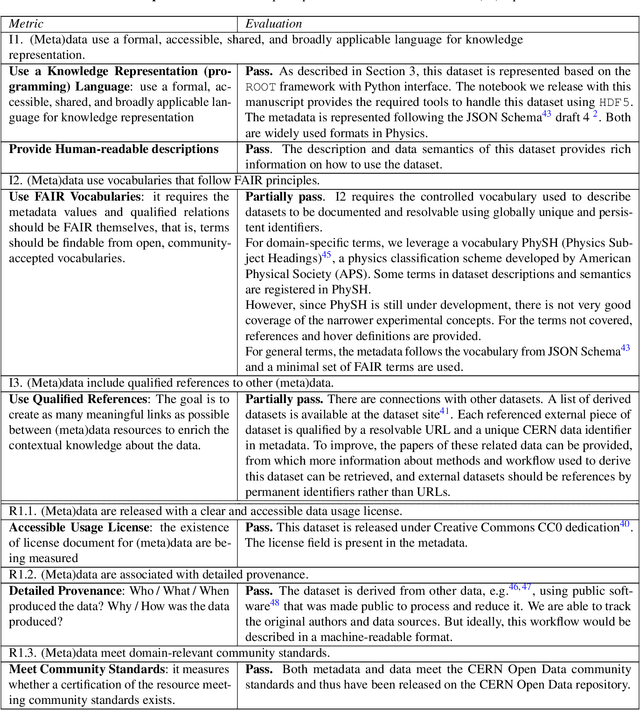
To enable the reusability of massive scientific datasets by humans and machines, researchers aim to create scientific datasets that adhere to the principles of findability, accessibility, interoperability, and reusability (FAIR) for data and artificial intelligence (AI) models. This article provides a domain-agnostic, step-by-step assessment guide to evaluate whether or not a given dataset meets each FAIR principle. We then demonstrate how to use this guide to evaluate the FAIRness of an open simulated dataset produced by the CMS Collaboration at the CERN Large Hadron Collider. This dataset consists of Higgs boson decays and quark and gluon background, and is available through the CERN Open Data Portal. We also use other available tools to assess the FAIRness of this dataset, and incorporate feedback from members of the FAIR community to validate our results. This article is accompanied by a Jupyter notebook to facilitate an understanding and exploration of the dataset, including visualization of its elements. This study marks the first in a planned series of articles that will guide scientists in the creation and quantification of FAIRness in high energy particle physics datasets and AI models.