 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent results on searches with boosted Higgs bosons at CMS
Jul 16, 2025The study of boosted Higgs bosons at the LHC provides a unique window to probe Higgs boson couplings at high energy scales and search for signs of physics beyond the standard model. In these proceedings, we present recent results on boosted Higgs boson searches at the CMS experiment, highlighting innovative reconstruction and tagging techniques that enhance sensitivity in this challenging regime.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Learning Symmetry-Independent Jet Representations via Jet-Based Joint Embedding Predictive Architecture
Dec 05, 2024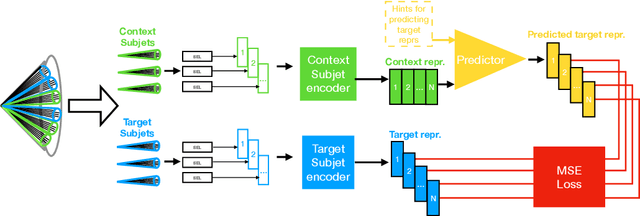
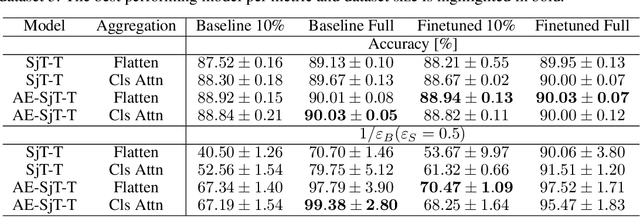
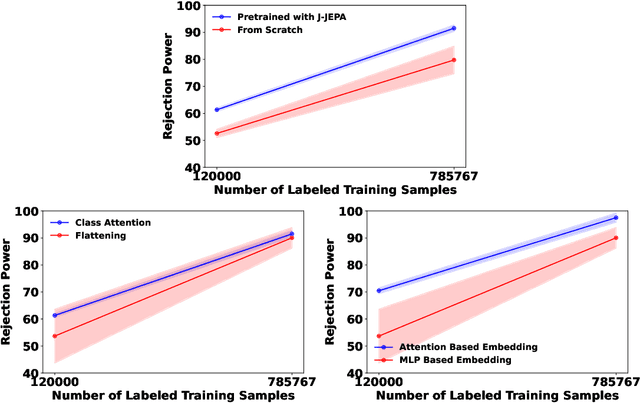
In high energy physics, self-supervised learning (SSL) methods have the potential to aid in the creation of machine learning models without the need for labeled datasets for a variety of tasks, including those related to jets -- narrow sprays of particles produced by quarks and gluons in high energy particle collisions. This study introduces an approach to learning jet representations without hand-crafted augmentations using a jet-based joint embedding predictive architecture (J-JEPA), which aims to predict various physical targets from an informative context. As our method does not require hand-crafted augmentation like other common SSL techniques, J-JEPA avoids introducing biases that could harm downstream tasks. Since different tasks generally require invariance under different augmentations, this training without hand-crafted augmentation enables versatile applications, offering a pathway toward a cross-task foundation model. We finetune the representations learned by J-JEPA for jet tagging and benchmark them against task-specific representations.
Scalable neural network models and terascale datasets for particle-flow reconstruction
Sep 13, 2023We study scalable machine learning models for full event reconstruction in high-energy electron-positron collisions based on a highly granular detector simulation. Particle-flow (PF) reconstruction can be formulated as a supervised learning task using tracks and calorimeter clusters or hits. We compare a graph neural network and kernel-based transformer and demonstrate that both avoid quadratic memory allocation and computational cost while achieving realistic PF reconstruction. We show that hyperparameter tuning on a supercomputer significantly improves the physics performance of the models. We also demonstrate that the resulting model is highly portable across hardware processors, supporting Nvidia, AMD, and Intel Habana cards. Finally, we demonstrate that the model can be trained on highly granular inputs consisting of tracks and calorimeter hits, resulting in a competitive physics performance with the baseline. Datasets and software to reproduce the studies are published following the findable, accessible, interoperable, and reusable (FAIR) principles.
Progress towards an improved particle flow algorithm at CMS with machine learning
Mar 30, 2023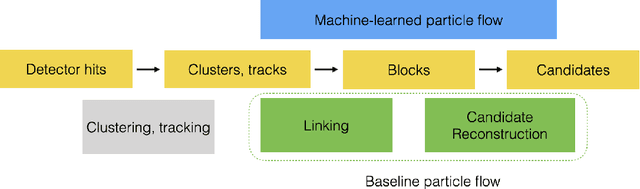

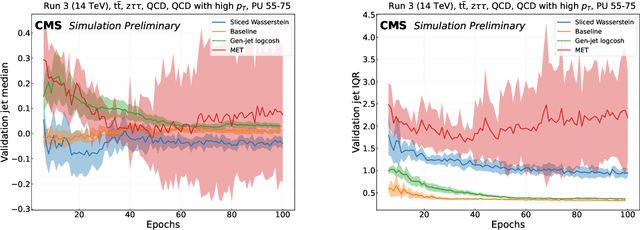
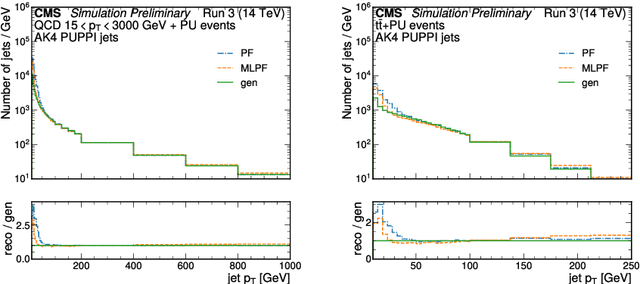
The particle-flow (PF) algorithm, which infers particles based on tracks and calorimeter clusters, is of central importance to event reconstruction in the CMS experiment at the CERN LHC, and has been a focus of development in light of planned Phase-2 running conditions with an increased pileup and detector granularity. In recent years, the machine learned particle-flow (MLPF) algorithm, a graph neural network that performs PF reconstruction, has been explored in CMS, with the possible advantages of directly optimizing for the physical quantities of interest, being highly reconfigurable to new conditions, and being a natural fit for deployment to heterogeneous accelerators. We discuss progress in CMS towards an improved implementation of the MLPF reconstruction, now optimized using generator/simulation-level particle information as the target for the first time. This paves the way to potentially improving the detector response in terms of physical quantities of interest. We describe the simulation-based training target, progress and studies on event-based loss terms, details on the model hyperparameter tuning, as well as physics validation with respect to the current PF algorithm in terms of high-level physical quantities such as the jet and missing transverse momentum resolutions. We find that the MLPF algorithm, trained on a generator/simulator level particle information for the first time, results in broadly compatible particle and jet reconstruction performance with the baseline PF, setting the stage for improving the physics performance by additional training statistics and model tuning.
* 7 pages, 4 Figures, 1 Table
FAIR AI Models in High Energy Physics
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
Do graph neural networks learn traditional jet substructure?
Nov 17, 2022



At the CERN LHC, the task of jet tagging, whose goal is to infer the origin of a jet given a set of final-state particles, is dominated by machine learning methods. Graph neural networks have been used to address this task by treating jets as point clouds with underlying, learnable, edge connections between the particles inside. We explore the decision-making process for one such state-of-the-art network, ParticleNet, by looking for relevant edge connections identified using the layerwise-relevance propagation technique. As the model is trained, we observe changes in the distribution of relevant edges connecting different intermediate clusters of particles, known as subjets. The resulting distribution of subjet connections is different for signal jets originating from top quarks, whose subjets typically correspond to its three decay products, and background jets originating from lighter quarks and gluons. This behavior indicates that the model is using traditional jet substructure observables, such as the number of prongs -- energetic particle clusters -- within a jet, when identifying jets.
Machine Learning for Particle Flow Reconstruction at CMS
Mar 01, 2022
We provide details on the implementation of a machine-learning based particle flow algorithm for CMS. The standard particle flow algorithm reconstructs stable particles based on calorimeter clusters and tracks to provide a global event reconstruction that exploits the combined information of multiple detector subsystems, leading to strong improvements for quantities such as jets and missing transverse energy. We have studied a possible evolution of particle flow towards heterogeneous computing platforms such as GPUs using a graph neural network. The machine-learned PF model reconstructs particle candidates based on the full list of tracks and calorimeter clusters in the event. For validation, we determine the physics performance directly in the CMS software framework when the proposed algorithm is interfaced with the offline reconstruction of jets and missing transverse energy. We also report the computational performance of the algorithm, which scales approximately linearly in runtime and memory usage with the input size.
Particle Graph Autoencoders and Differentiable, Learned Energy Mover's Distance
Nov 24, 2021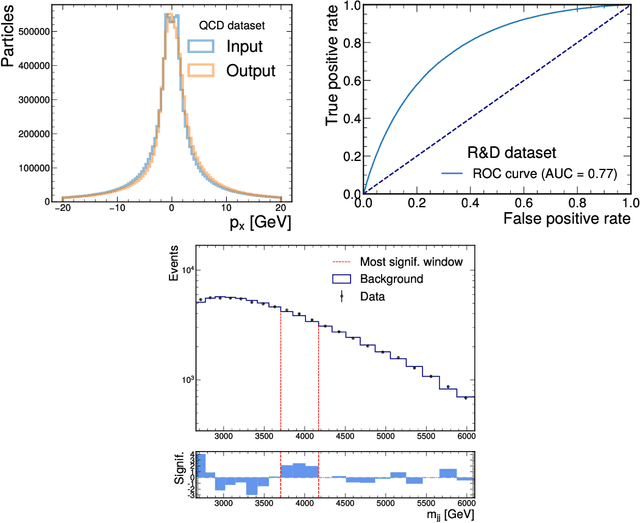
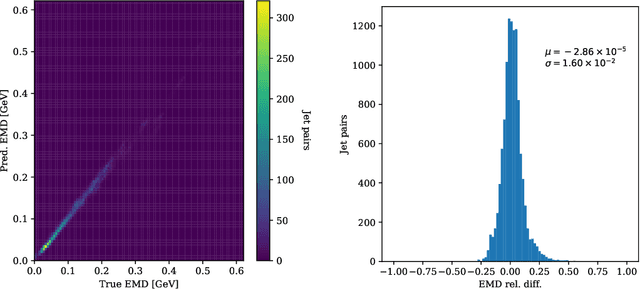
Autoencoders have useful applications in high energy physics in anomaly detection, particularly for jets - collimated showers of particles produced in collisions such as those at the CERN Large Hadron Collider. We explore the use of graph-based autoencoders, which operate on jets in their "particle cloud" representations and can leverage the interdependencies among the particles within a jet, for such tasks. Additionally, we develop a differentiable approximation to the energy mover's distance via a graph neural network, which may subsequently be used as a reconstruction loss function for autoencoders.
Explaining machine-learned particle-flow reconstruction
Nov 24, 2021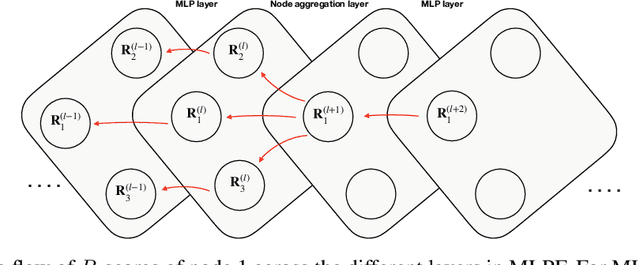
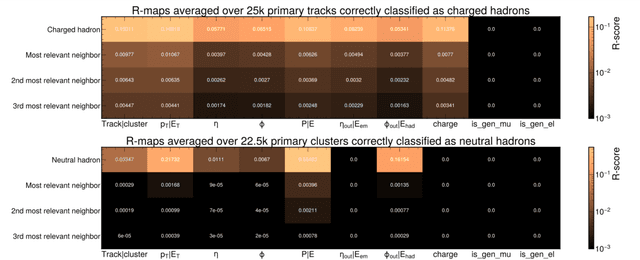
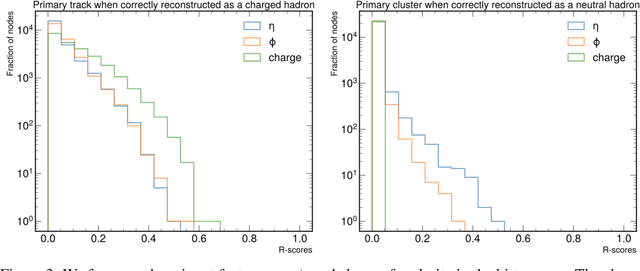
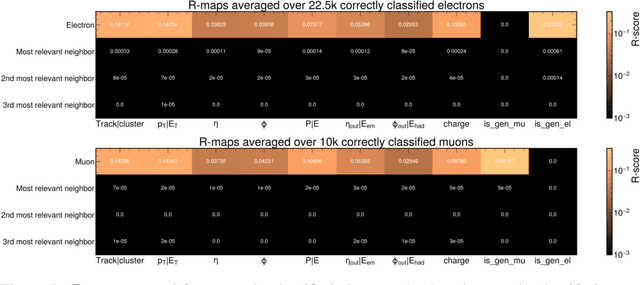
The particle-flow (PF) algorithm is used in general-purpose particle detectors to reconstruct a comprehensive particle-level view of the collision by combining information from different subdetectors. A graph neural network (GNN) model, known as the machine-learned particle-flow (MLPF) algorithm, has been developed to substitute the rule-based PF algorithm. However, understanding the model's decision making is not straightforward, especially given the complexity of the set-to-set prediction task, dynamic graph building, and message-passing steps. In this paper, we adapt the layerwise-relevance propagation technique for GNNs and apply it to the MLPF algorithm to gauge the relevant nodes and features for its predictions. Through this process, we gain insight into the model's decision-making.