 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Performance Prediction for Hyperparameter Optimization of Deep Learning Models Using High Performance Computing and Quantum Annealing
Nov 29, 2023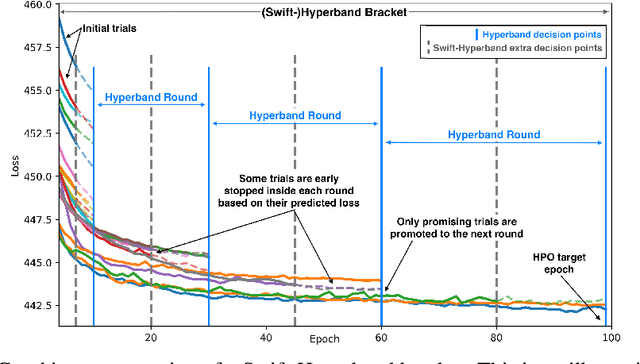
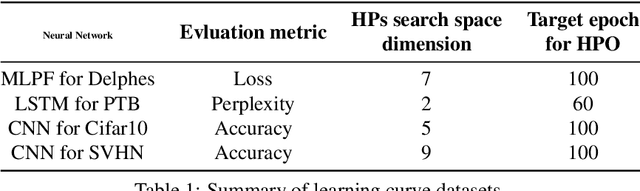
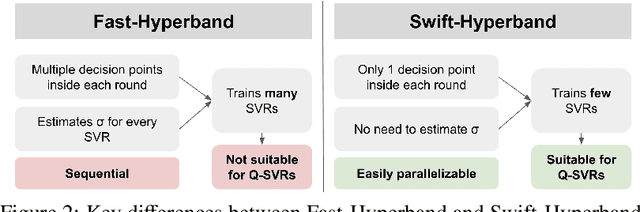

Hyperparameter Optimization (HPO) of Deep Learning-based models tends to be a compute resource intensive process as it usually requires to train the target model with many different hyperparameter configurations. We show that integrating model performance prediction with early stopping methods holds great potential to speed up the HPO process of deep learning models. Moreover, we propose a novel algorithm called Swift-Hyperband that can use either classical or quantum support vector regression for performance prediction and benefit from distributed High Performance Computing environments. This algorithm is tested not only for the Machine-Learned Particle Flow model used in High Energy Physics, but also for a wider range of target models from domains such as computer vision and natural language processing. Swift-Hyperband is shown to find comparable (or better) hyperparameters as well as using less computational resources in all test cases.
Scalable neural network models and terascale datasets for particle-flow reconstruction
Sep 13, 2023We study scalable machine learning models for full event reconstruction in high-energy electron-positron collisions based on a highly granular detector simulation. Particle-flow (PF) reconstruction can be formulated as a supervised learning task using tracks and calorimeter clusters or hits. We compare a graph neural network and kernel-based transformer and demonstrate that both avoid quadratic memory allocation and computational cost while achieving realistic PF reconstruction. We show that hyperparameter tuning on a supercomputer significantly improves the physics performance of the models. We also demonstrate that the resulting model is highly portable across hardware processors, supporting Nvidia, AMD, and Intel Habana cards. Finally, we demonstrate that the model can be trained on highly granular inputs consisting of tracks and calorimeter hits, resulting in a competitive physics performance with the baseline. Datasets and software to reproduce the studies are published following the findable, accessible, interoperable, and reusable (FAIR) principles.
Hyperparameter optimization, quantum-assisted model performance prediction, and benchmarking of AI-based High Energy Physics workloads using HPC
Mar 27, 2023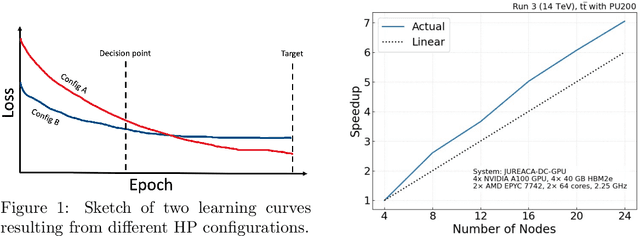

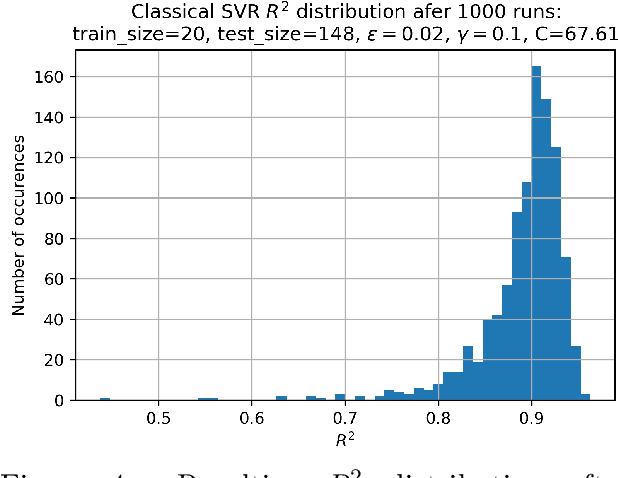
Training and Hyperparameter Optimization (HPO) of deep learning-based AI models are often compute resource intensive and calls for the use of large-scale distributed resources as well as scalable and resource efficient hyperparameter search algorithms. This work studies the potential of using model performance prediction to aid the HPO process carried out on High Performance Computing systems. In addition, a quantum annealer is used to train the performance predictor and a method is proposed to overcome some of the problems derived from the current limitations in quantum systems as well as to increase the stability of solutions. This allows for achieving results on a quantum machine comparable to those obtained on a classical machine, showing how quantum computers could be integrated within classical machine learning tuning pipelines. Furthermore, results are presented from the development of a containerized benchmark based on an AI-model for collision event reconstruction that allows us to compare and assess the suitability of different hardware accelerators for training deep neural networks.
Hyperparameter optimization of data-driven AI models on HPC systems
Mar 02, 2022
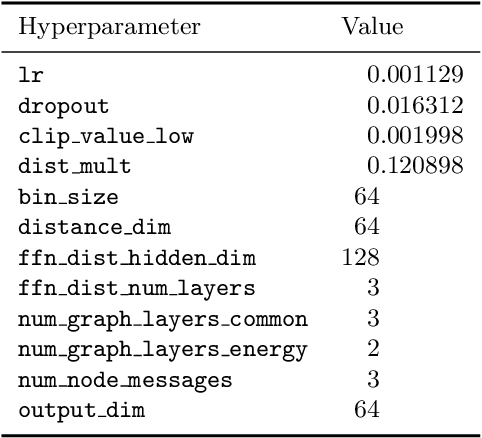
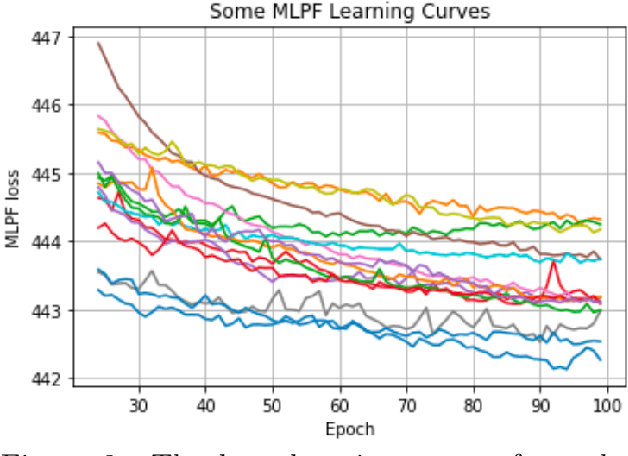
In the European Center of Excellence in Exascale computing "Research on AI- and Simulation-Based Engineering at Exascale" (CoE RAISE), researchers develop novel, scalable AI technologies towards Exascale. This work exercises High Performance Computing resources to perform large-scale hyperparameter optimization using distributed training on multiple compute nodes. This is part of RAISE's work on data-driven use cases which leverages AI- and HPC cross-methods developed within the project. In response to the demand for parallelizable and resource efficient hyperparameter optimization methods, advanced hyperparameter search algorithms are benchmarked and compared. The evaluated algorithms, including Random Search, Hyperband and ASHA, are tested and compared in terms of both accuracy and accuracy per compute resources spent. As an example use case, a graph neural network model known as MLPF, developed for the task of Machine-Learned Particle-Flow reconstruction in High Energy Physics, acts as the base model for optimization. Results show that hyperparameter optimization significantly increased the performance of MLPF and that this would not have been possible without access to large-scale High Performance Computing resources. It is also shown that, in the case of MLPF, the ASHA algorithm in combination with Bayesian optimization gives the largest performance increase per compute resources spent out of the investigated algorithms.
Machine Learning for Particle Flow Reconstruction at CMS
Mar 01, 2022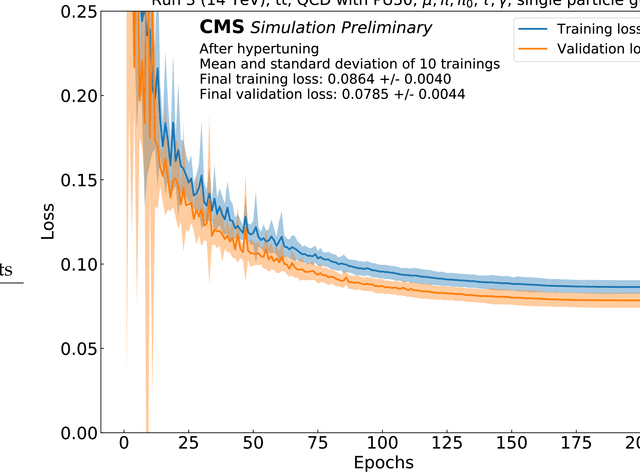
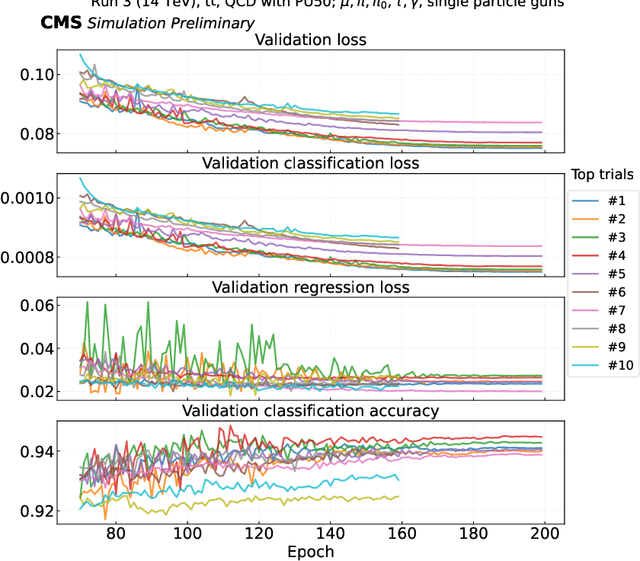
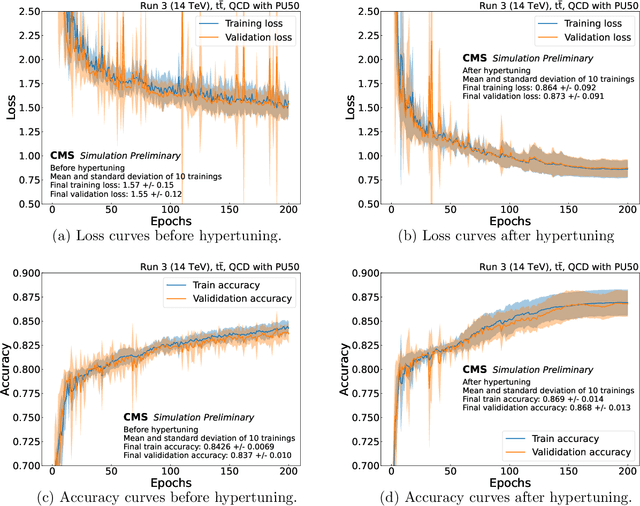
We provide details on the implementation of a machine-learning based particle flow algorithm for CMS. The standard particle flow algorithm reconstructs stable particles based on calorimeter clusters and tracks to provide a global event reconstruction that exploits the combined information of multiple detector subsystems, leading to strong improvements for quantities such as jets and missing transverse energy. We have studied a possible evolution of particle flow towards heterogeneous computing platforms such as GPUs using a graph neural network. The machine-learned PF model reconstructs particle candidates based on the full list of tracks and calorimeter clusters in the event. For validation, we determine the physics performance directly in the CMS software framework when the proposed algorithm is interfaced with the offline reconstruction of jets and missing transverse energy. We also report the computational performance of the algorithm, which scales approximately linearly in runtime and memory usage with the input size.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.