 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Geometry of Next Token Prediction Using Cumulant Expansion of the Softmax Entropy
Oct 05, 2025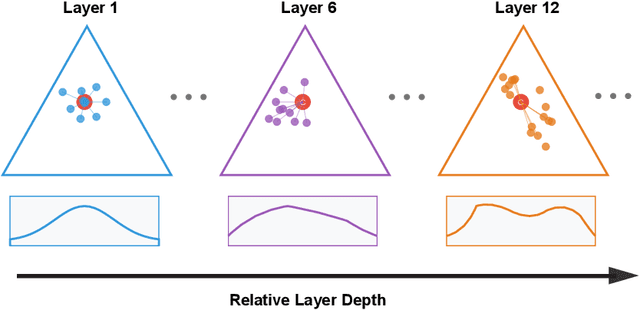

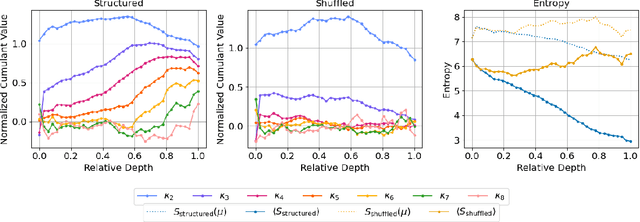
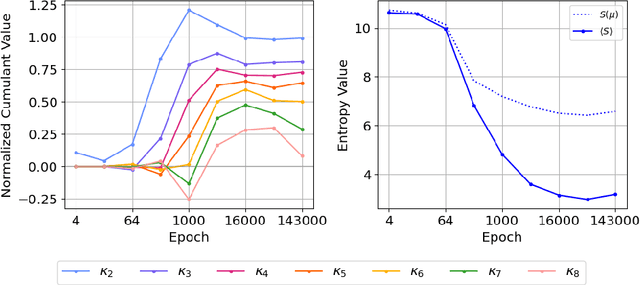
We introduce a cumulant-expansion framework for quantifying how large language models (LLMs) internalize higher-order statistical structure during next-token prediction. By treating the softmax entropy of each layer's logit distribution as a perturbation around its "center" distribution, we derive closed-form cumulant observables that isolate successively higher-order correlations. Empirically, we track these cumulants in GPT-2 and Pythia models on Pile-10K prompts. (i) Structured prompts exhibit a characteristic rise-and-plateau profile across layers, whereas token-shuffled prompts remain flat, revealing the dependence of the cumulant profile on meaningful context. (ii) During training, all cumulants increase monotonically before saturating, directly visualizing the model's progression from capturing variance to learning skew, kurtosis, and higher-order statistical structures. (iii) Mathematical prompts show distinct cumulant signatures compared to general text, quantifying how models employ fundamentally different processing mechanisms for mathematical versus linguistic content. Together, these results establish cumulant analysis as a lightweight, mathematically grounded probe of feature-learning dynamics in high-dimensional neural networks.
FAIR AI Models in High Energy Physics
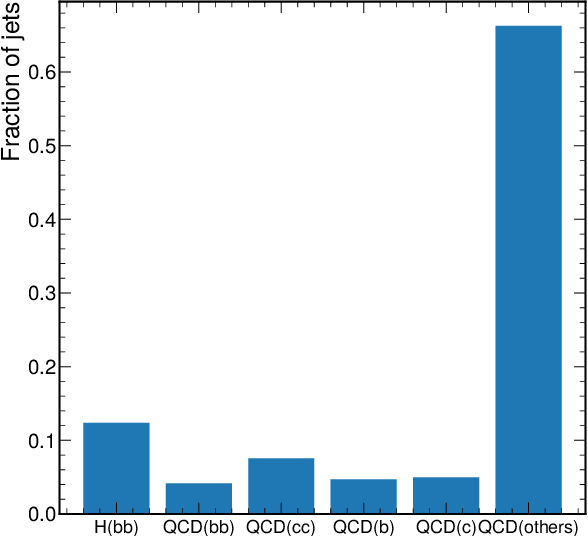
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
Neural Embedding: Learning the Embedding of the Manifold of Physics Data
Aug 14, 2022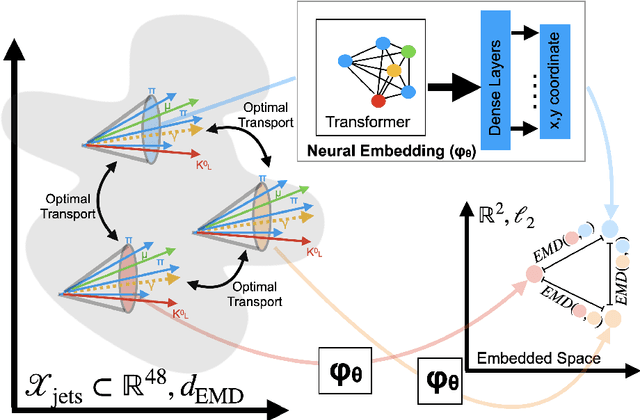
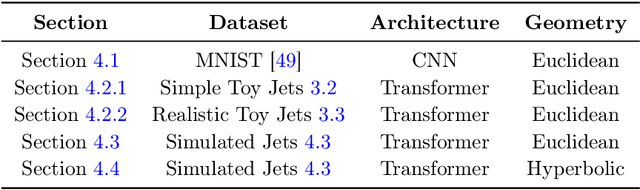
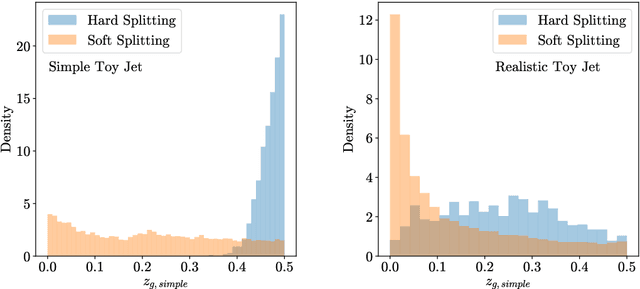

In this paper, we present a method of embedding physics data manifolds with metric structure into lower dimensional spaces with simpler metrics, such as Euclidean and Hyperbolic spaces. We then demonstrate that it can be a powerful step in the data analysis pipeline for many applications. Using progressively more realistic simulated collisions at the Large Hadron Collider, we show that this embedding approach learns the underlying latent structure. With the notion of volume in Euclidean spaces, we provide for the first time a viable solution to quantifying the true search capability of model agnostic search algorithms in collider physics (i.e. anomaly detection). Finally, we discuss how the ideas presented in this paper can be employed to solve many practical challenges that require the extraction of physically meaningful representations from information in complex high dimensional datasets.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
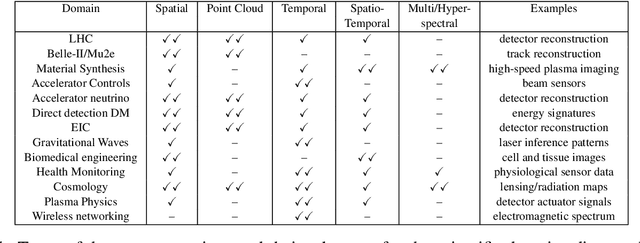
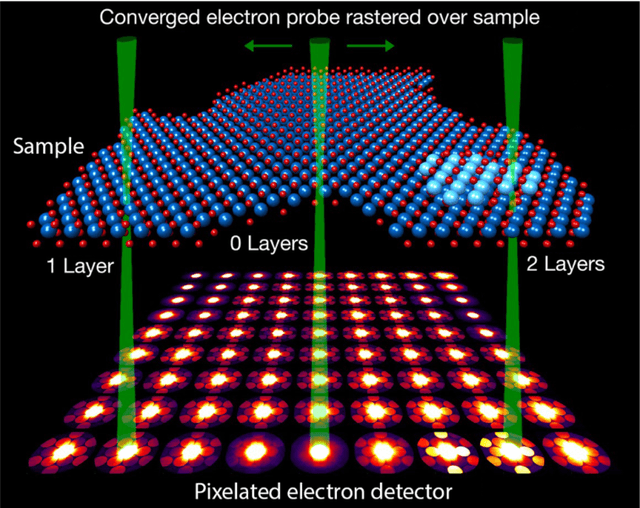
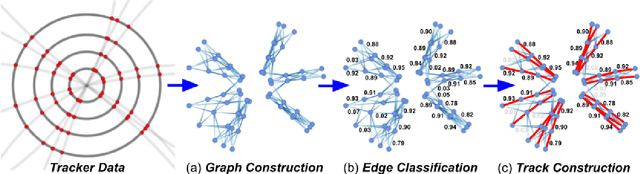
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
A FAIR and AI-ready Higgs Boson Decay Dataset
Aug 04, 2021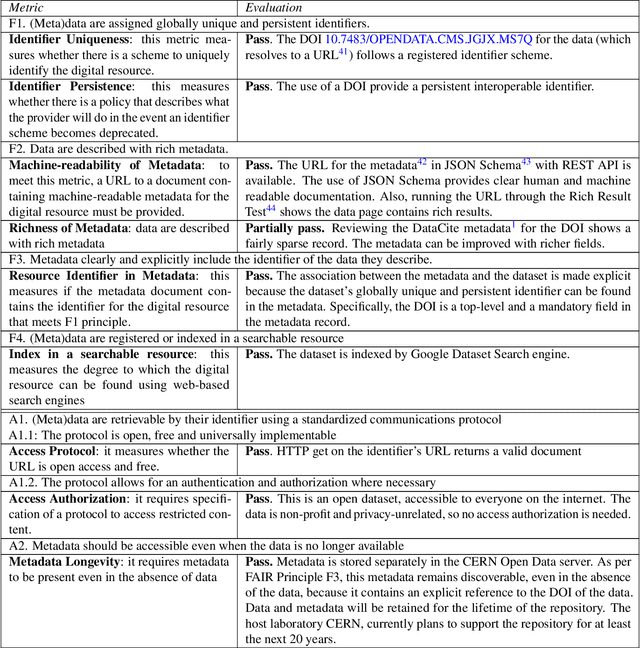
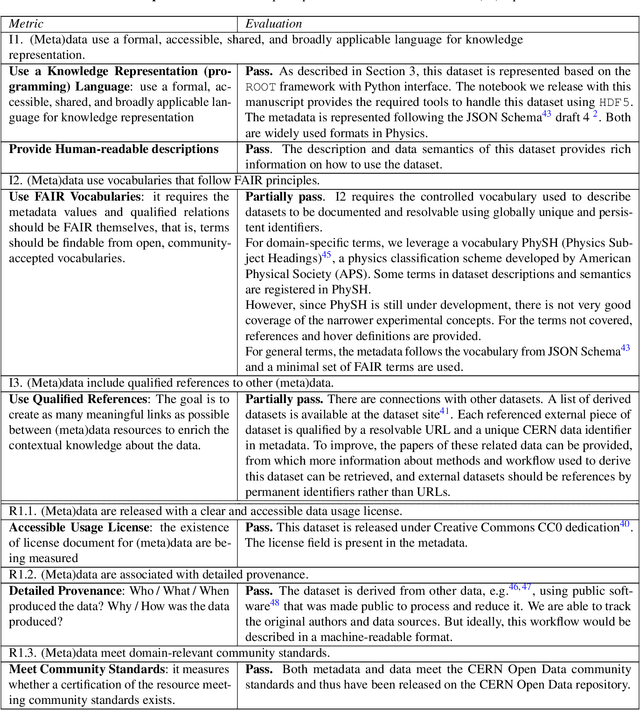
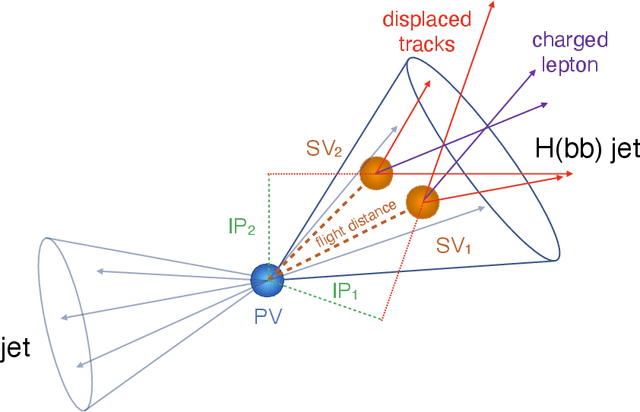
To enable the reusability of massive scientific datasets by humans and machines, researchers aim to create scientific datasets that adhere to the principles of findability, accessibility, interoperability, and reusability (FAIR) for data and artificial intelligence (AI) models. This article provides a domain-agnostic, step-by-step assessment guide to evaluate whether or not a given dataset meets each FAIR principle. We then demonstrate how to use this guide to evaluate the FAIRness of an open simulated dataset produced by the CMS Collaboration at the CERN Large Hadron Collider. This dataset consists of Higgs boson decays and quark and gluon background, and is available through the CERN Open Data Portal. We also use other available tools to assess the FAIRness of this dataset, and incorporate feedback from members of the FAIR community to validate our results. This article is accompanied by a Jupyter notebook to facilitate an understanding and exploration of the dataset, including visualization of its elements. This study marks the first in a planned series of articles that will guide scientists in the creation and quantification of FAIRness in high energy particle physics datasets and AI models.