 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Embedding: Learning the Embedding of the Manifold of Physics Data
Aug 14, 2022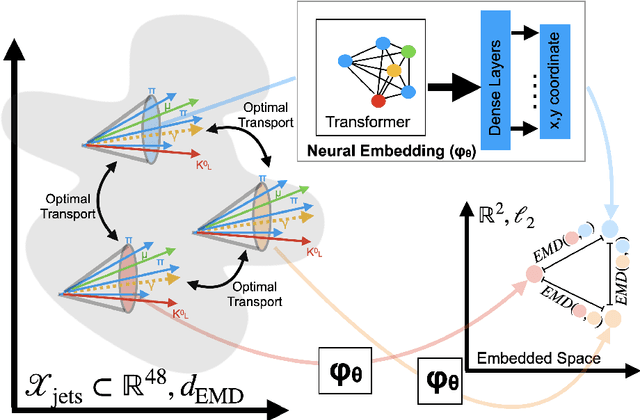

In this paper, we present a method of embedding physics data manifolds with metric structure into lower dimensional spaces with simpler metrics, such as Euclidean and Hyperbolic spaces. We then demonstrate that it can be a powerful step in the data analysis pipeline for many applications. Using progressively more realistic simulated collisions at the Large Hadron Collider, we show that this embedding approach learns the underlying latent structure. With the notion of volume in Euclidean spaces, we provide for the first time a viable solution to quantifying the true search capability of model agnostic search algorithms in collider physics (i.e. anomaly detection). Finally, we discuss how the ideas presented in this paper can be employed to solve many practical challenges that require the extraction of physically meaningful representations from information in complex high dimensional datasets.
Challenges for Unsupervised Anomaly Detection in Particle Physics
Oct 13, 2021
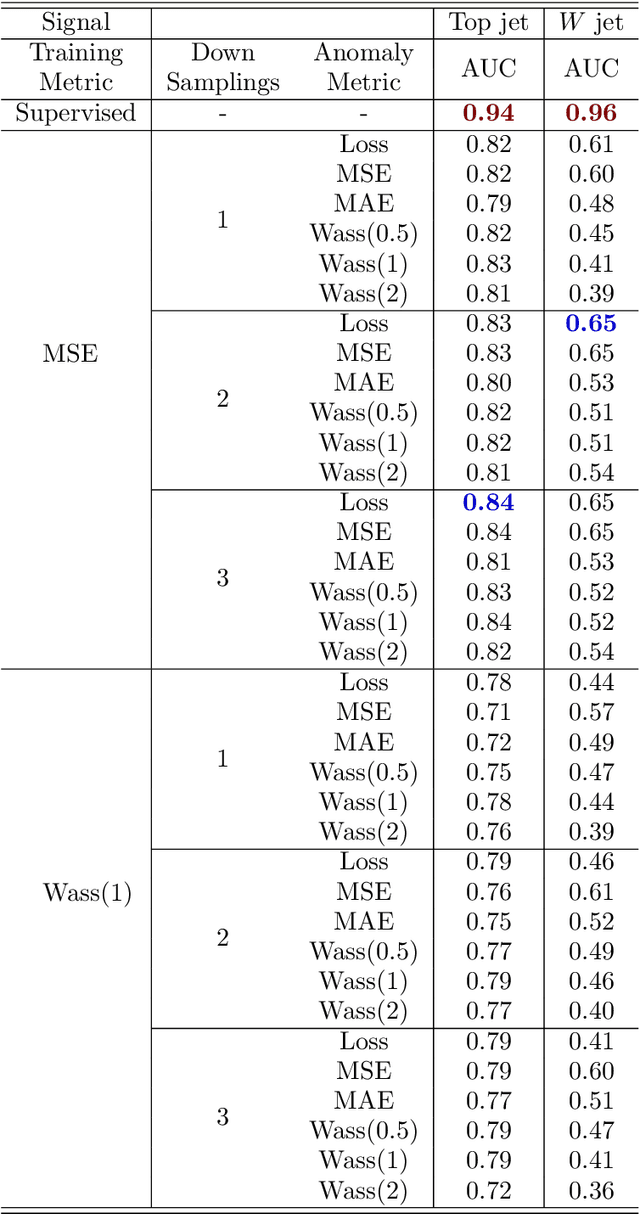
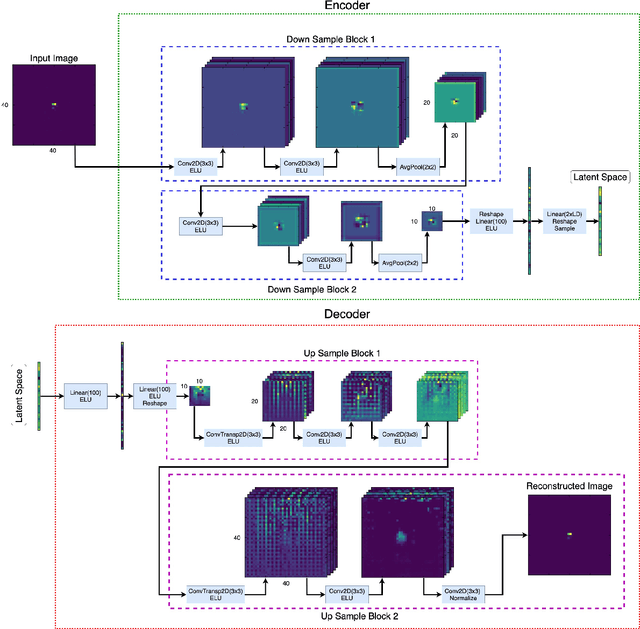
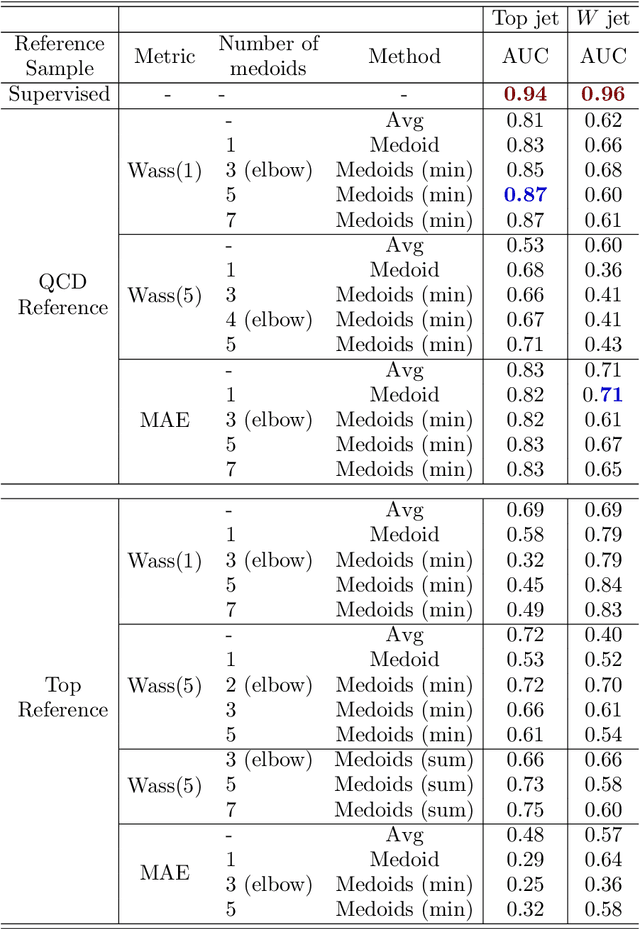
Anomaly detection relies on designing a score to determine whether a particular event is uncharacteristic of a given background distribution. One way to define a score is to use autoencoders, which rely on the ability to reconstruct certain types of data (background) but not others (signals). In this paper, we study some challenges associated with variational autoencoders, such as the dependence on hyperparameters and the metric used, in the context of anomalous signal (top and $W$) jets in a QCD background. We find that the hyperparameter choices strongly affect the network performance and that the optimal parameters for one signal are non-optimal for another. In exploring the networks, we uncover a connection between the latent space of a variational autoencoder trained using mean-squared-error and the optimal transport distances within the dataset. We then show that optimal transport distances to representative events in the background dataset can be used directly for anomaly detection, with performance comparable to the autoencoders. Whether using autoencoders or optimal transport distances for anomaly detection, we find that the choices that best represent the background are not necessarily best for signal identification. These challenges with unsupervised anomaly detection bolster the case for additional exploration of semi-supervised or alternative approaches.
Extracting the Subhalo Mass Function from Strong Lens Images with Image Segmentation
Sep 14, 2020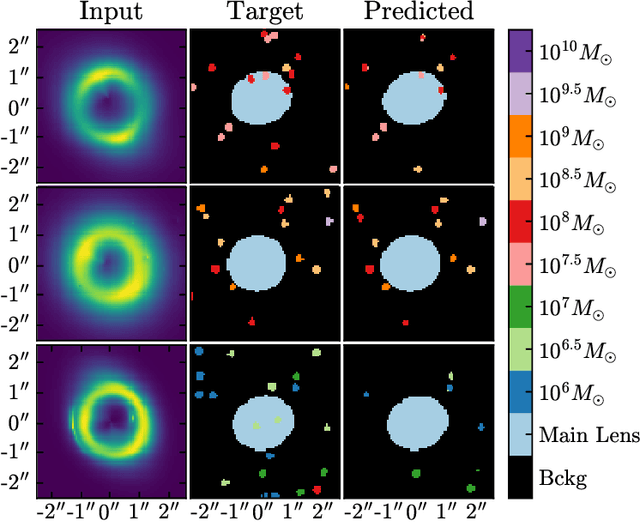
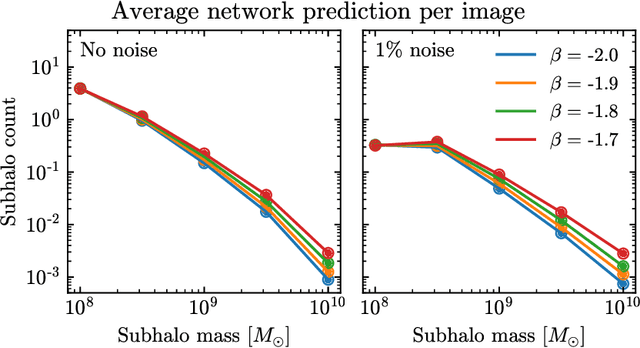
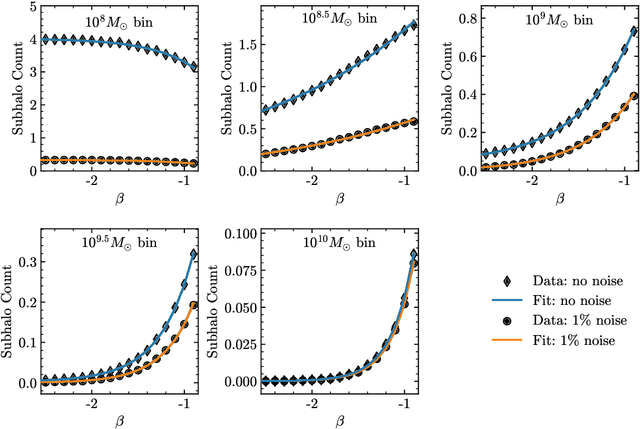
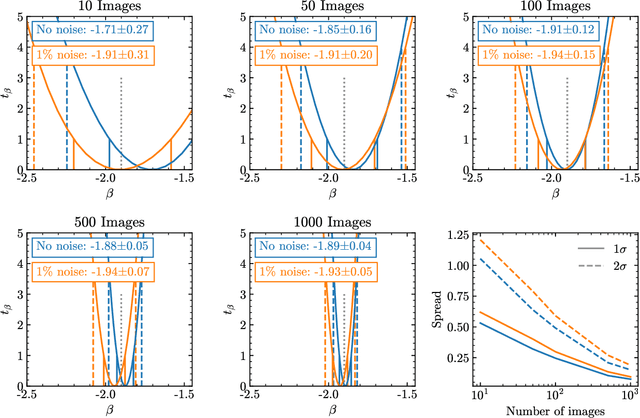
Detecting substructure within strongly lensed images is a promising route to shed light on the nature of dark matter. It is a challenging task, which traditionally requires detailed lens modeling and source reconstruction, taking weeks to analyze each system. We use machine learning to circumvent the need for lens and source modeling and develop a method to both locate subhalos in an image as well as determine their mass using the technique of image segmentation. The network is trained on images with a single subhalo located near the Einstein ring. Training in this way allows the network to learn the gravitational lensing of light and it is then able to accurately detect entire populations of substructure, even far from the Einstein ring. In images with a single subhalo and without noise, the network detects subhalos of mass $10^6 M_{\odot}$ 62% of the time and 78% of these detected subhalos are predicted in the correct mass bin. The detection accuracy increases for heavier masses. When random noise at the level of 1% of the mean brightness of the image is included (which is a realistic approximation HST, for sources brighter than magnitude 20), the network loses sensitivity to the low-mass subhalos; with noise, the $10^{8.5}M_{\odot}$ subhalos are detected 86% of the time, but the $10^8 M_{\odot}$ subhalos are only detected 38% of the time. The false-positive rate is around 2 false subhalos per 100 images with and without noise, coming mostly from masses $\leq10^8 M_{\odot}$. With good accuracy and a low false-positive rate, counting the number of pixels assigned to each subhalo class over multiple images allows for a measurement of the subhalo mass function (SMF). When measured over five mass bins from $10^8 M_{\odot}$ to $10^{10} M_{\odot}$ the SMF slope is recovered with an error of 14.2 (16.3)% for 10 images, and this improves to 2.1 (2.6)% for 1000 images without (with 1%) noise.
Cataloging Accreted Stars within Gaia DR2 using Deep Learning
Jul 15, 2019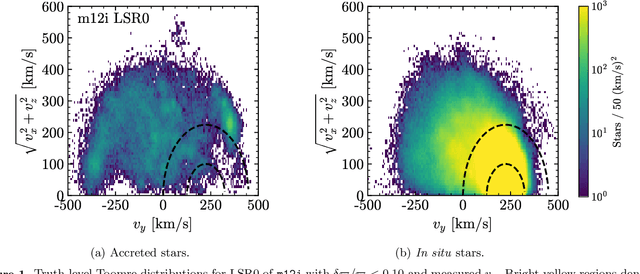
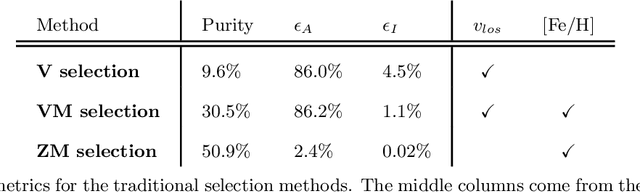
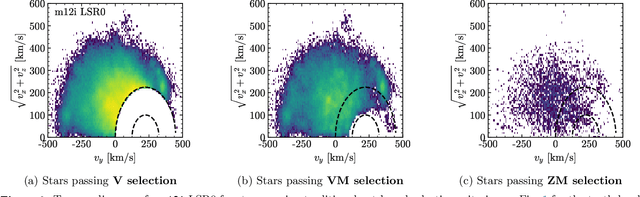
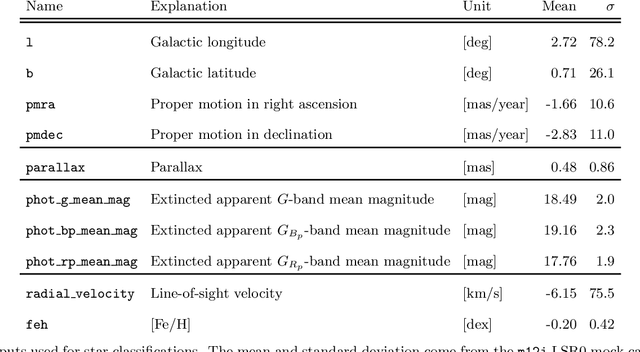
The goal of this paper is to develop a machine learning based approach that utilizes phase space alone to separate the Gaia DR2 stars into two categories: those accreted onto the Milky Way from in situ stars that were born within the Galaxy. Traditional selection methods that have been used to identify accreted stars typically rely on full 3D velocity and/or metallicity information, which significantly reduces the number of classifiable stars. The approach advocated here is applicable to a much larger fraction of Gaia DR2. A method known as transfer learning is shown to be effective through extensive testing on a set of mock Gaia catalogs that are based on the FIRE cosmological zoom-in hydrodynamic simulations of Milky Way-mass galaxies. The machine is first trained on simulated data using only 5D kinematics as inputs, and is then further trained on a cross-matched Gaia/RAVE data set, which improves sensitivity to properties of the real Milky Way. The result is a catalog that identifies ~650,000 accreted stars within Gaia DR2. This catalog can yield empirical insights into the merger history of the Milky Way, and could be used to infer properties of the dark matter distribution.
What is the Machine Learning?
Mar 28, 2018
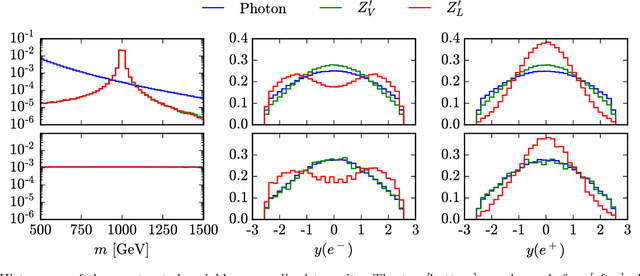
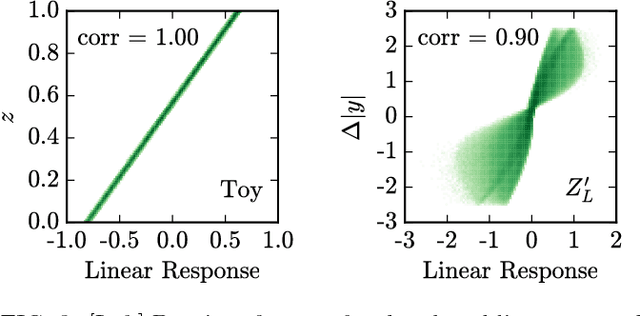
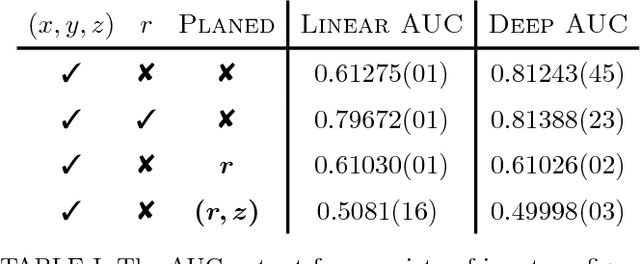
Applications of machine learning tools to problems of physical interest are often criticized for producing sensitivity at the expense of transparency. To address this concern, we explore a data planing procedure for identifying combinations of variables -- aided by physical intuition -- that can discriminate signal from background. Weights are introduced to smooth away the features in a given variable(s). New networks are then trained on this modified data. Observed decreases in sensitivity diagnose the variable's discriminating power. Planing also allows the investigation of the linear versus non-linear nature of the boundaries between signal and background. We demonstrate the efficacy of this approach using a toy example, followed by an application to an idealized heavy resonance scenario at the Large Hadron Collider. By unpacking the information being utilized by these algorithms, this method puts in context what it means for a machine to learn.
* 6 pages, 3 figures. Version published in PRD, discussion added
(Machine) Learning to Do More with Less
Mar 28, 2018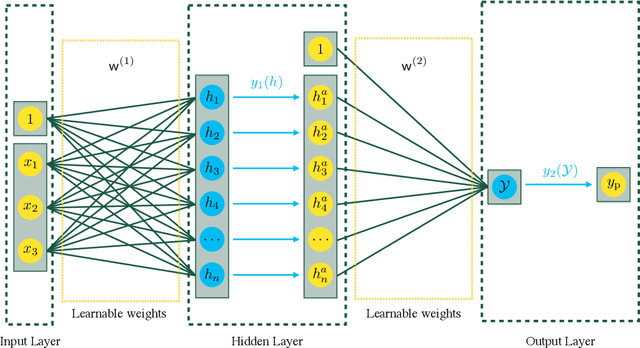
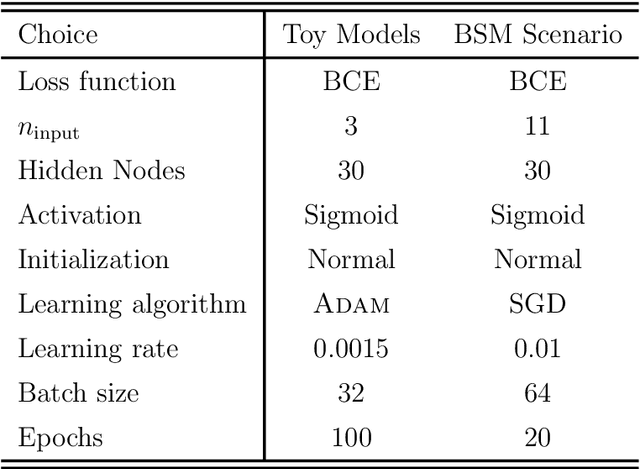
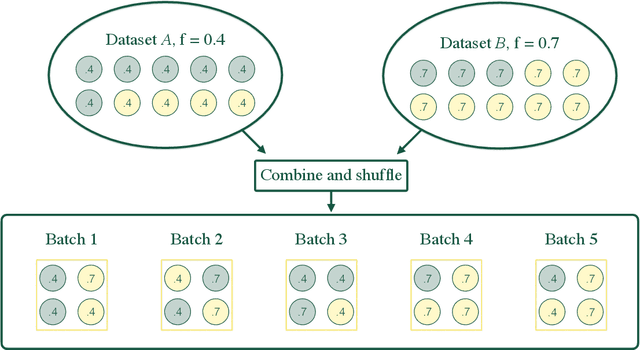
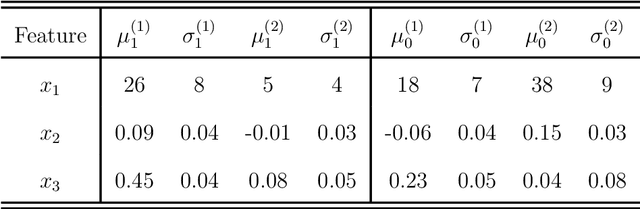
Determining the best method for training a machine learning algorithm is critical to maximizing its ability to classify data. In this paper, we compare the standard "fully supervised" approach (that relies on knowledge of event-by-event truth-level labels) with a recent proposal that instead utilizes class ratios as the only discriminating information provided during training. This so-called "weakly supervised" technique has access to less information than the fully supervised method and yet is still able to yield impressive discriminating power. In addition, weak supervision seems particularly well suited to particle physics since quantum mechanics is incompatible with the notion of mapping an individual event onto any single Feynman diagram. We examine the technique in detail -- both analytically and numerically -- with a focus on the robustness to issues of mischaracterizing the training samples. Weakly supervised networks turn out to be remarkably insensitive to systematic mismodeling. Furthermore, we demonstrate that the event level outputs for weakly versus fully supervised networks are probing different kinematics, even though the numerical quality metrics are essentially identical. This implies that it should be possible to improve the overall classification ability by combining the output from the two types of networks. For concreteness, we apply this technology to a signature of beyond the Standard Model physics to demonstrate that all these impressive features continue to hold in a scenario of relevance to the LHC.