 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCataloging Accreted Stars within Gaia DR2 using Deep Learning
Jul 15, 2019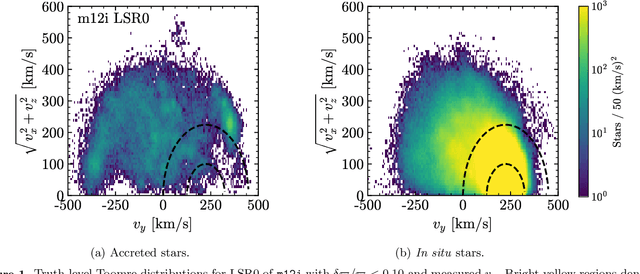
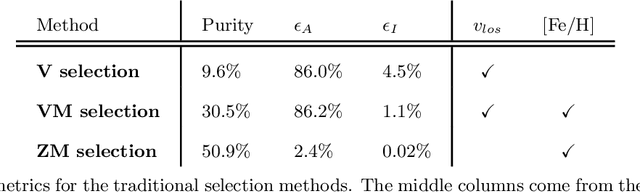
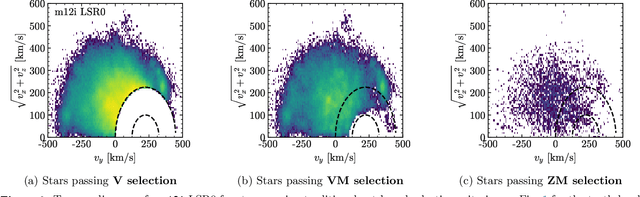
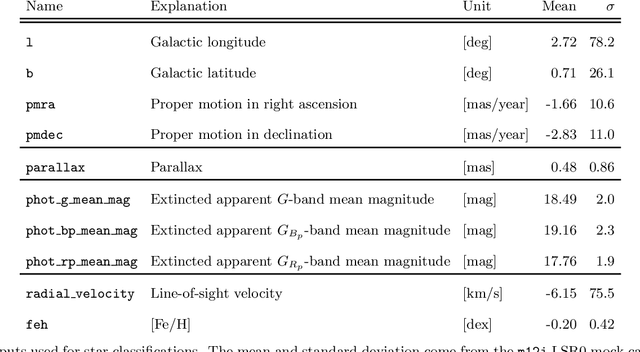
The goal of this paper is to develop a machine learning based approach that utilizes phase space alone to separate the Gaia DR2 stars into two categories: those accreted onto the Milky Way from in situ stars that were born within the Galaxy. Traditional selection methods that have been used to identify accreted stars typically rely on full 3D velocity and/or metallicity information, which significantly reduces the number of classifiable stars. The approach advocated here is applicable to a much larger fraction of Gaia DR2. A method known as transfer learning is shown to be effective through extensive testing on a set of mock Gaia catalogs that are based on the FIRE cosmological zoom-in hydrodynamic simulations of Milky Way-mass galaxies. The machine is first trained on simulated data using only 5D kinematics as inputs, and is then further trained on a cross-matched Gaia/RAVE data set, which improves sensitivity to properties of the real Milky Way. The result is a catalog that identifies ~650,000 accreted stars within Gaia DR2. This catalog can yield empirical insights into the merger history of the Milky Way, and could be used to infer properties of the dark matter distribution.
What is the Machine Learning?
Mar 28, 2018
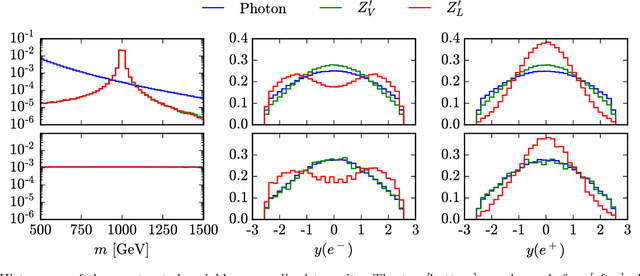
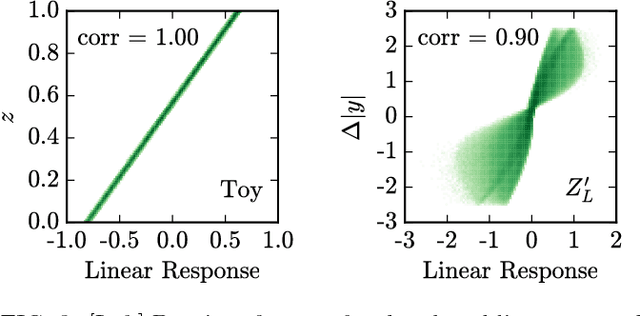
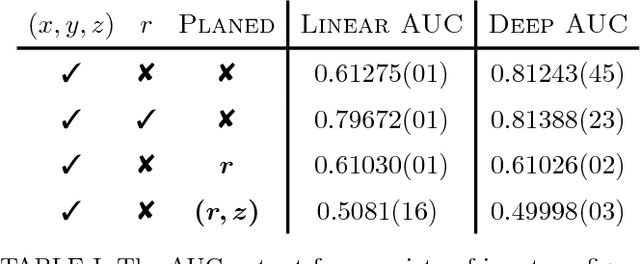
Applications of machine learning tools to problems of physical interest are often criticized for producing sensitivity at the expense of transparency. To address this concern, we explore a data planing procedure for identifying combinations of variables -- aided by physical intuition -- that can discriminate signal from background. Weights are introduced to smooth away the features in a given variable(s). New networks are then trained on this modified data. Observed decreases in sensitivity diagnose the variable's discriminating power. Planing also allows the investigation of the linear versus non-linear nature of the boundaries between signal and background. We demonstrate the efficacy of this approach using a toy example, followed by an application to an idealized heavy resonance scenario at the Large Hadron Collider. By unpacking the information being utilized by these algorithms, this method puts in context what it means for a machine to learn.
* 6 pages, 3 figures. Version published in PRD, discussion added
(Machine) Learning to Do More with Less
Mar 28, 2018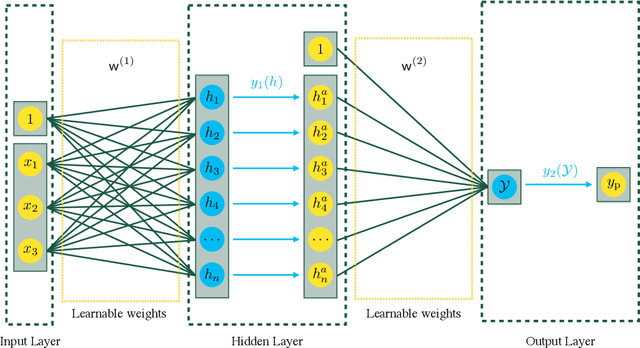
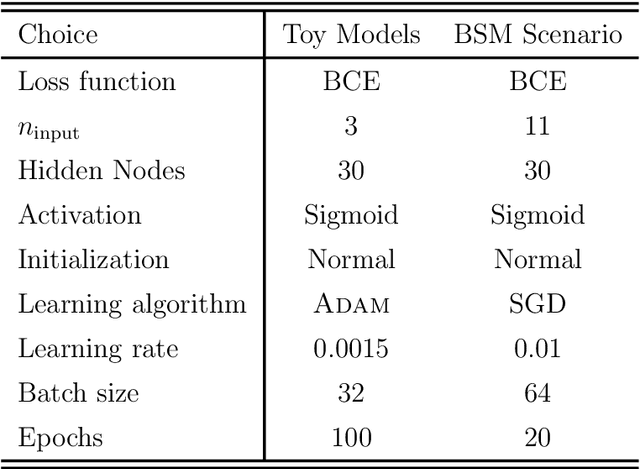
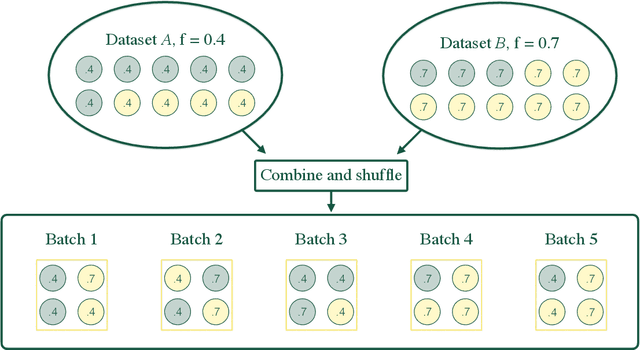
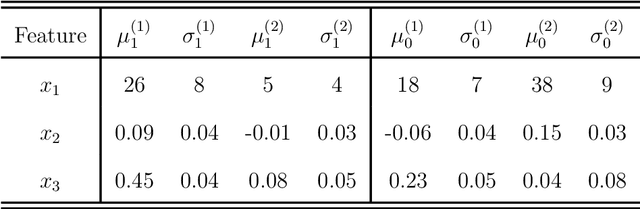
Determining the best method for training a machine learning algorithm is critical to maximizing its ability to classify data. In this paper, we compare the standard "fully supervised" approach (that relies on knowledge of event-by-event truth-level labels) with a recent proposal that instead utilizes class ratios as the only discriminating information provided during training. This so-called "weakly supervised" technique has access to less information than the fully supervised method and yet is still able to yield impressive discriminating power. In addition, weak supervision seems particularly well suited to particle physics since quantum mechanics is incompatible with the notion of mapping an individual event onto any single Feynman diagram. We examine the technique in detail -- both analytically and numerically -- with a focus on the robustness to issues of mischaracterizing the training samples. Weakly supervised networks turn out to be remarkably insensitive to systematic mismodeling. Furthermore, we demonstrate that the event level outputs for weakly versus fully supervised networks are probing different kinematics, even though the numerical quality metrics are essentially identical. This implies that it should be possible to improve the overall classification ability by combining the output from the two types of networks. For concreteness, we apply this technology to a signature of beyond the Standard Model physics to demonstrate that all these impressive features continue to hold in a scenario of relevance to the LHC.