 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of probabilistic modeling and automated machine learning framework for high-dimensional stress field
Mar 15, 2023



Modern computational methods, involving highly sophisticated mathematical formulations, enable several tasks like modeling complex physical phenomenon, predicting key properties and design optimization. The higher fidelity in these computer models makes it computationally intensive to query them hundreds of times for optimization and one usually relies on a simplified model albeit at the cost of losing predictive accuracy and precision. Towards this, data-driven surrogate modeling methods have shown a lot of promise in emulating the behavior of the expensive computer models. However, a major bottleneck in such methods is the inability to deal with high input dimensionality and the need for relatively large datasets. With such problems, the input and output quantity of interest are tensors of high dimensionality. Commonly used surrogate modeling methods for such problems, suffer from requirements like high number of computational evaluations that precludes one from performing other numerical tasks like uncertainty quantification and statistical analysis. In this work, we propose an end-to-end approach that maps a high-dimensional image like input to an output of high dimensionality or its key statistics. Our approach uses two main framework that perform three steps: a) reduce the input and output from a high-dimensional space to a reduced or low-dimensional space, b) model the input-output relationship in the low-dimensional space, and c) enable the incorporation of domain-specific physical constraints as masks. In order to accomplish the task of reducing input dimensionality we leverage principal component analysis, that is coupled with two surrogate modeling methods namely: a) Bayesian hybrid modeling, and b) DeepHyper's deep neural networks. We demonstrate the applicability of the approach on a problem of a linear elastic stress field data.
Distilling Governing Laws and Source Input for Dynamical Systems from Videos
May 03, 2022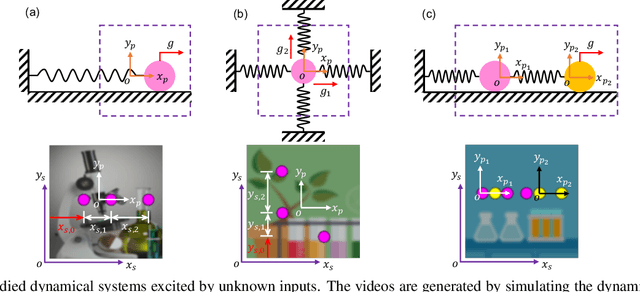
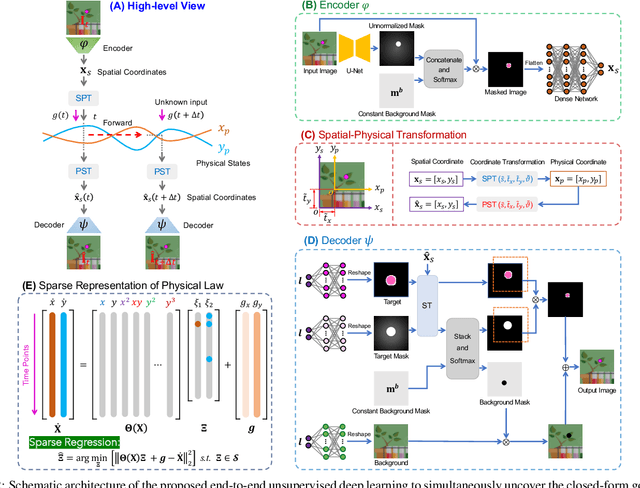
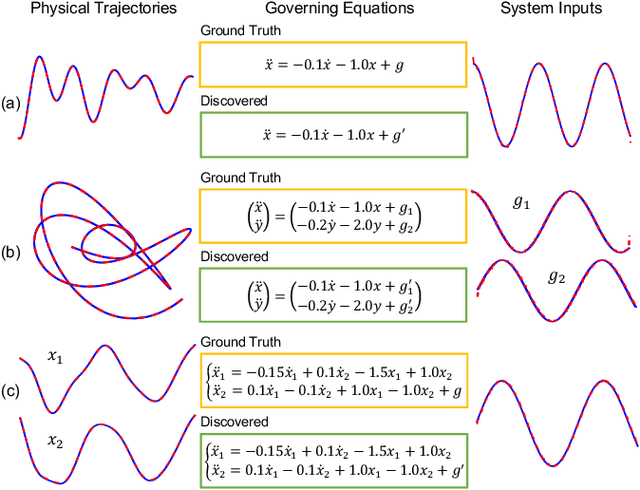
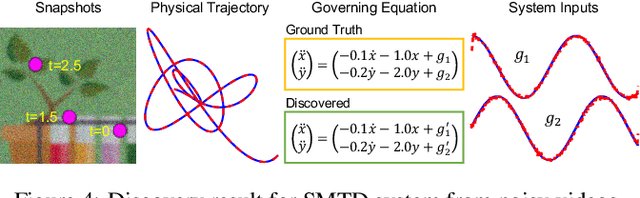
Distilling interpretable physical laws from videos has led to expanded interest in the computer vision community recently thanks to the advances in deep learning, but still remains a great challenge. This paper introduces an end-to-end unsupervised deep learning framework to uncover the explicit governing equations of dynamics presented by moving object(s), based on recorded videos. Instead in the pixel (spatial) coordinate system of image space, the physical law is modeled in a regressed underlying physical coordinate system where the physical states follow potential explicit governing equations. A numerical integrator-based sparse regression module is designed and serves as a physical constraint to the autoencoder and coordinate system regression, and, in the meanwhile, uncover the parsimonious closed-form governing equations from the learned physical states. Experiments on simulated dynamical scenes show that the proposed method is able to distill closed-form governing equations and simultaneously identify unknown excitation input for several dynamical systems recorded by videos, which fills in the gap in literature where no existing methods are available and applicable for solving this type of problem.
* 7 pages, 6 figures, IJCAI-2022. arXiv admin note: text overlap with arXiv:2106.04776
Uncovering Closed-form Governing Equations of Nonlinear Dynamics from Videos
Jun 09, 2021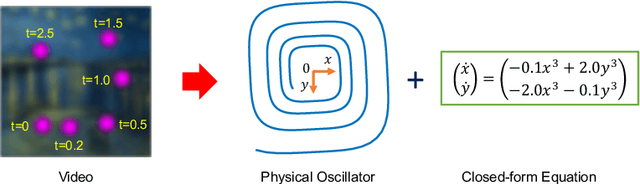
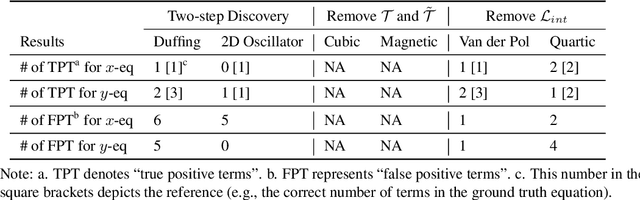
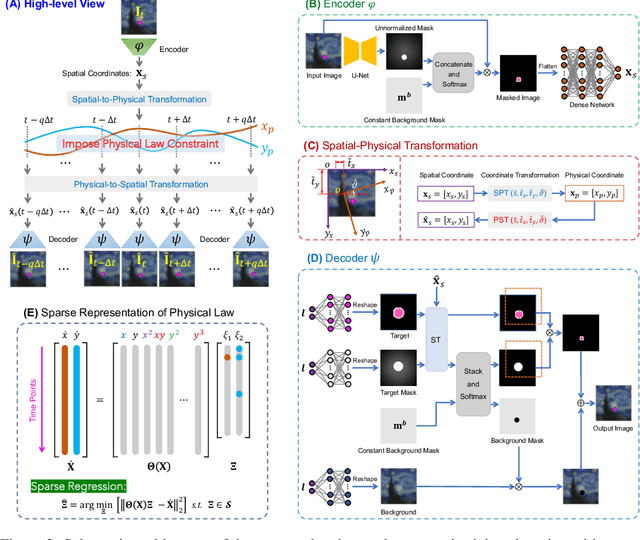
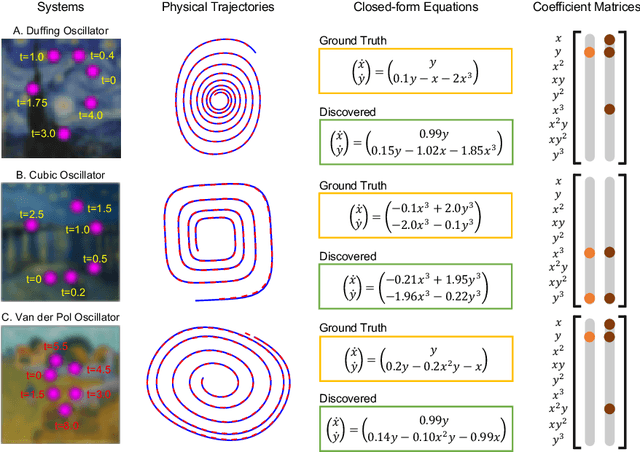
Distilling analytical models from data has the potential to advance our understanding and prediction of nonlinear dynamics. Although discovery of governing equations based on observed system states (e.g., trajectory time series) has revealed success in a wide range of nonlinear dynamics, uncovering the closed-form equations directly from raw videos still remains an open challenge. To this end, we introduce a novel end-to-end unsupervised deep learning framework to uncover the mathematical structure of equations that governs the dynamics of moving objects in videos. Such an architecture consists of (1) an encoder-decoder network that learns low-dimensional spatial/pixel coordinates of the moving object, (2) a learnable Spatial-Physical Transformation component that creates mapping between the extracted spatial/pixel coordinates and the latent physical states of dynamics, and (3) a numerical integrator-based sparse regression module that uncovers the parsimonious closed-form governing equations of learned physical states and, meanwhile, serves as a constraint to the autoencoder. The efficacy of the proposed method is demonstrated by uncovering the governing equations of a variety of nonlinear dynamical systems depicted by moving objects in videos. The resulting computational framework enables discovery of parsimonious interpretable model in a flexible and accessible sensing environment where only videos are available.
Extracting full-field subpixel structural displacements from videos via deep learning
Sep 03, 2020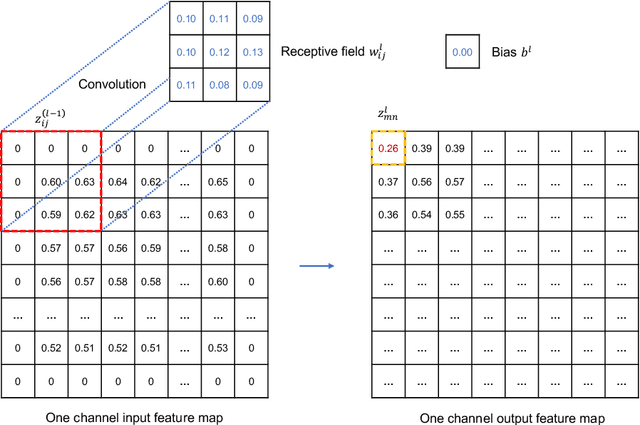
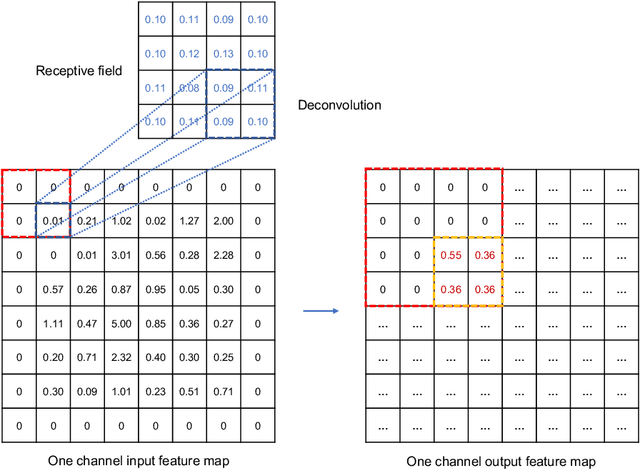

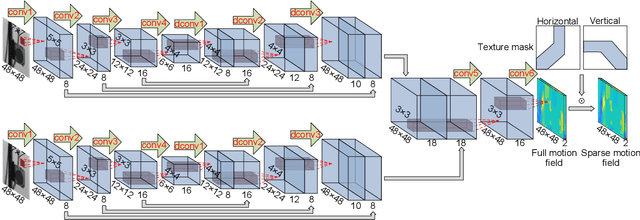
This paper develops a deep learning framework based on convolutional neural networks (CNNs) that enable real-time extraction of full-field subpixel structural displacements from videos. In particular, two new CNN architectures are designed and trained on a dataset generated by the phase-based motion extraction method from a single lab-recorded high-speed video of a dynamic structure. As displacement is only reliable in the regions with sufficient texture contrast, the sparsity of motion field induced by the texture mask is considered via the network architecture design and loss function definition. Results show that, with the supervision of full and sparse motion field, the trained network is capable of identifying the pixels with sufficient texture contrast as well as their subpixel motions. The performance of the trained networks is tested on various videos of other structures to extract the full-field motion (e.g., displacement time histories), which indicates that the trained networks have generalizability to accurately extract full-field subtle displacements for pixels with sufficient texture contrast.