 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageNet-Think-250K: A Large-Scale Synthetic Dataset for Multimodal Reasoning for Vision Language Models
Oct 02, 2025We develop ImageNet-Think, a multimodal reasoning dataset designed to aid the development of Vision Language Models (VLMs) with explicit reasoning capabilities. Our dataset is built on 250,000 images from ImageNet21k dataset, providing structured thinking tokens and corresponding answers. Our synthetic dataset is generated by two state-of-the-art VLMs: GLM-4.1V-9B-Thinking and Kimi-VL-A3B-Thinking-2506. Each image is accompanied by two pairs of thinking-answer sequences, creating a resource for training and evaluating multimodal reasoning models. We capture the step-by-step reasoning process of VLMs and the final descriptive answers. Our goal with this dataset is to enable the development of more robust VLMs while contributing to the broader understanding of multimodal reasoning mechanisms. The dataset and evaluation benchmarks will be publicly available to aid research in reasoning/thinking multimodal VLMs.
PagedEviction: Structured Block-wise KV Cache Pruning for Efficient Large Language Model Inference
Sep 04, 2025KV caching significantly improves the efficiency of Large Language Model (LLM) inference by storing attention states from previously processed tokens, enabling faster generation of subsequent tokens. However, as sequence length increases, the KV cache quickly becomes a major memory bottleneck. To address this, we propose PagedEviction, a novel fine-grained, structured KV cache pruning strategy that enhances the memory efficiency of vLLM's PagedAttention. Unlike existing approaches that rely on attention-based token importance or evict tokens across different vLLM pages, PagedEviction introduces an efficient block-wise eviction algorithm tailored for paged memory layouts. Our method integrates seamlessly with PagedAttention without requiring any modifications to its CUDA attention kernels. We evaluate PagedEviction across Llama-3.1-8B-Instruct, Llama-3.2-1B-Instruct, and Llama-3.2-3B-Instruct models on the LongBench benchmark suite, demonstrating improved memory usage with better accuracy than baselines on long context tasks.
MoE-Inference-Bench: Performance Evaluation of Mixture of Expert Large Language and Vision Models
Aug 24, 2025Mixture of Experts (MoE) models have enabled the scaling of Large Language Models (LLMs) and Vision Language Models (VLMs) by achieving massive parameter counts while maintaining computational efficiency. However, MoEs introduce several inference-time challenges, including load imbalance across experts and the additional routing computational overhead. To address these challenges and fully harness the benefits of MoE, a systematic evaluation of hardware acceleration techniques is essential. We present MoE-Inference-Bench, a comprehensive study to evaluate MoE performance across diverse scenarios. We analyze the impact of batch size, sequence length, and critical MoE hyperparameters such as FFN dimensions and number of experts on throughput. We evaluate several optimization techniques on Nvidia H100 GPUs, including pruning, Fused MoE operations, speculative decoding, quantization, and various parallelization strategies. Our evaluation includes MoEs from the Mixtral, DeepSeek, OLMoE and Qwen families. The results reveal performance differences across configurations and provide insights for the efficient deployment of MoEs.
LangVision-LoRA-NAS: Neural Architecture Search for Variable LoRA Rank in Vision Language Models
Aug 17, 2025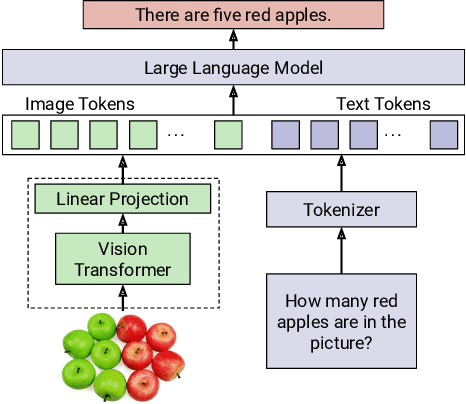
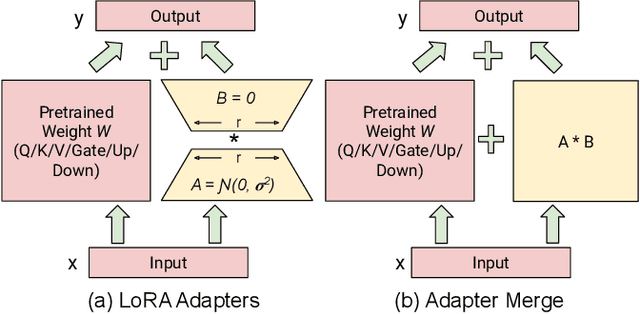
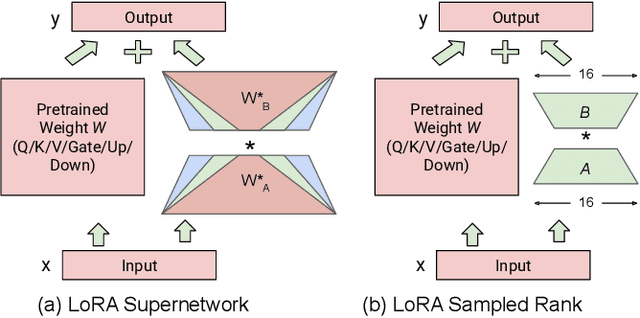
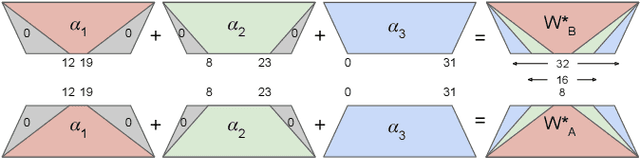
Vision Language Models (VLMs) integrate visual and text modalities to enable multimodal understanding and generation. These models typically combine a Vision Transformer (ViT) as an image encoder and a Large Language Model (LLM) for text generation. LoRA (Low-Rank Adaptation) is an efficient fine-tuning method to adapt pre-trained models to new tasks by introducing low-rank updates to their weights. While LoRA has emerged as a powerful technique for fine-tuning large models by introducing low-rank updates, current implementations assume a fixed rank, potentially limiting flexibility and efficiency across diverse tasks. This paper introduces \textit{LangVision-LoRA-NAS}, a novel framework that integrates Neural Architecture Search (NAS) with LoRA to optimize VLMs for variable-rank adaptation. Our approach leverages NAS to dynamically search for the optimal LoRA rank configuration tailored to specific multimodal tasks, balancing performance and computational efficiency. Through extensive experiments using the LLaMA-3.2-11B model on several datasets, LangVision-LoRA-NAS demonstrates notable improvement in model performance while reducing fine-tuning costs. Our Base and searched fine-tuned models on LLaMA-3.2-11B-Vision-Instruct can be found \href{https://huggingface.co/collections/krishnateja95/llama-32-11b-vision-instruct-langvision-lora-nas-6786cac480357a6a6fcc59ee}{\textcolor{blue}{here}} and the code for LangVision-LoRA-NAS can be found \href{https://github.com/krishnateja95/LangVision-NAS}{\textcolor{blue}{here}}.
BaKlaVa -- Budgeted Allocation of KV cache for Long-context Inference
Feb 18, 2025In Large Language Model (LLM) inference, Key-Value (KV) caches (KV-caches) are essential for reducing time complexity. However, they result in a linear increase in GPU memory as the context length grows. While recent work explores KV-cache eviction and compression policies to reduce memory usage, they often consider uniform KV-caches across all attention heads, leading to suboptimal performance. We introduce BaKlaVa, a method to allocate optimal memory for individual KV-caches across the model by estimating the importance of each KV-cache. Our empirical analysis demonstrates that not all KV-caches are equally critical for LLM performance. Using a one-time profiling approach, BaKlaVa assigns optimal memory budgets to each KV-cache. We evaluated our method on LLaMA-3-8B, and Qwen2.5-7B models, achieving up to a 70\% compression ratio while keeping baseline performance and delivering up to an order-of-magnitude accuracy improvement at higher compression levels.
LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Accelerators
Oct 31, 2024



Large Language Models (LLMs) have propelled groundbreaking advancements across several domains and are commonly used for text generation applications. However, the computational demands of these complex models pose significant challenges, requiring efficient hardware acceleration. Benchmarking the performance of LLMs across diverse hardware platforms is crucial to understanding their scalability and throughput characteristics. We introduce LLM-Inference-Bench, a comprehensive benchmarking suite to evaluate the hardware inference performance of LLMs. We thoroughly analyze diverse hardware platforms, including GPUs from Nvidia and AMD and specialized AI accelerators, Intel Habana and SambaNova. Our evaluation includes several LLM inference frameworks and models from LLaMA, Mistral, and Qwen families with 7B and 70B parameters. Our benchmarking results reveal the strengths and limitations of various models, hardware platforms, and inference frameworks. We provide an interactive dashboard to help identify configurations for optimal performance for a given hardware platform.
A Survey of Techniques for Optimizing Transformer Inference
Jul 16, 2023



Recent years have seen a phenomenal rise in performance and applications of transformer neural networks. The family of transformer networks, including Bidirectional Encoder Representations from Transformer (BERT), Generative Pretrained Transformer (GPT) and Vision Transformer (ViT), have shown their effectiveness across Natural Language Processing (NLP) and Computer Vision (CV) domains. Transformer-based networks such as ChatGPT have impacted the lives of common men. However, the quest for high predictive performance has led to an exponential increase in transformers' memory and compute footprint. Researchers have proposed techniques to optimize transformer inference at all levels of abstraction. This paper presents a comprehensive survey of techniques for optimizing the inference phase of transformer networks. We survey techniques such as knowledge distillation, pruning, quantization, neural architecture search and lightweight network design at the algorithmic level. We further review hardware-level optimization techniques and the design of novel hardware accelerators for transformers. We summarize the quantitative results on the number of parameters/FLOPs and accuracy of several models/techniques to showcase the tradeoff exercised by them. We also outline future directions in this rapidly evolving field of research. We believe that this survey will educate both novice and seasoned researchers and also spark a plethora of research efforts in this field.