 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Aware Low-Rank Adaptation: Mitigating Catastrophic Inheritance of Large Language Models
Paper and Code
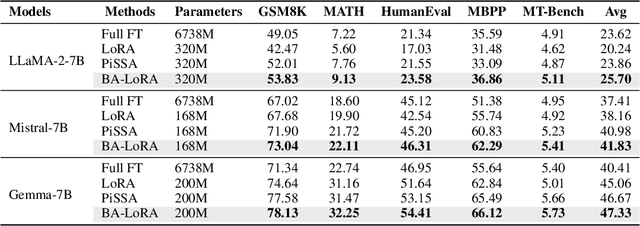
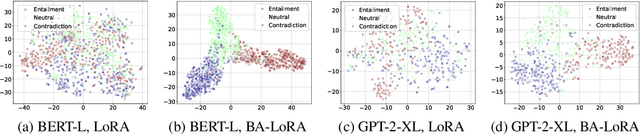
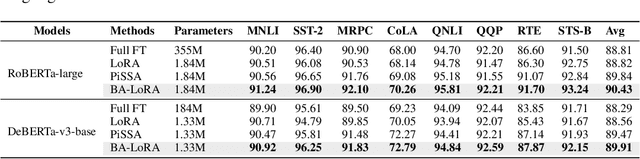
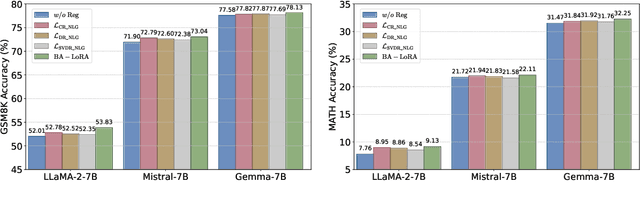
Large language models (LLMs) have exhibited remarkable proficiency across a diverse array of natural language processing (NLP) tasks. However, adapting LLMs to downstream applications typically necessitates computationally intensive and memory-demanding fine-tuning procedures. To mitigate these burdens, parameter-efficient fine-tuning (PEFT) techniques have emerged as a promising approach to tailor LLMs with minimal computational overhead. While PEFT methods offer substantial advantages, they do not fully address the pervasive issue of bias propagation from pre-training data. In this work, we introduce Bias-Aware Low-Rank Adaptation (BA-LoRA), a novel PEFT method designed to counteract bias inheritance. BA-LoRA incorporates three distinct regularization terms: (1) consistency regularizer, (2) diversity regularizer, and (3) singular vector decomposition regularizer. These regularizers collectively aim to improve the generative models' consistency, diversity, and generalization capabilities during the fine-tuning process. Through extensive experiments on a variety of natural language understanding (NLU) and natural language generation (NLG) tasks, employing prominent LLMs such as LLaMA, Mistral, and Gemma, we demonstrate that BA-LoRA surpasses the performance of LoRA and its state-of-the-art variants. Moreover, our method effectively mitigates the deleterious effects of pre-training bias, leading to more reliable and robust model outputs. The code is available at https://github.com/cyp-jlu-ai/BA-LoRA.