 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Planning for Autonomous Driving in Unstructured Scenarios Based on Graph Neural Network and Numerical Optimization
Jun 13, 2024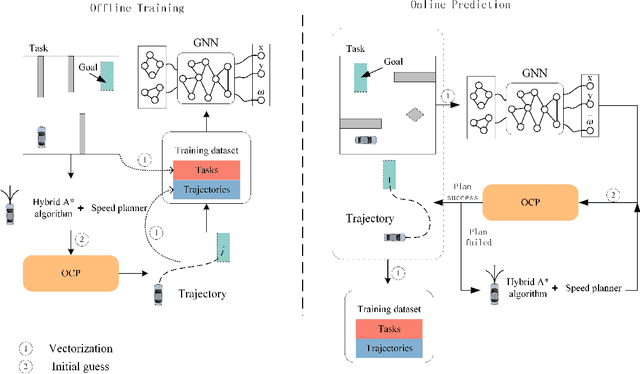
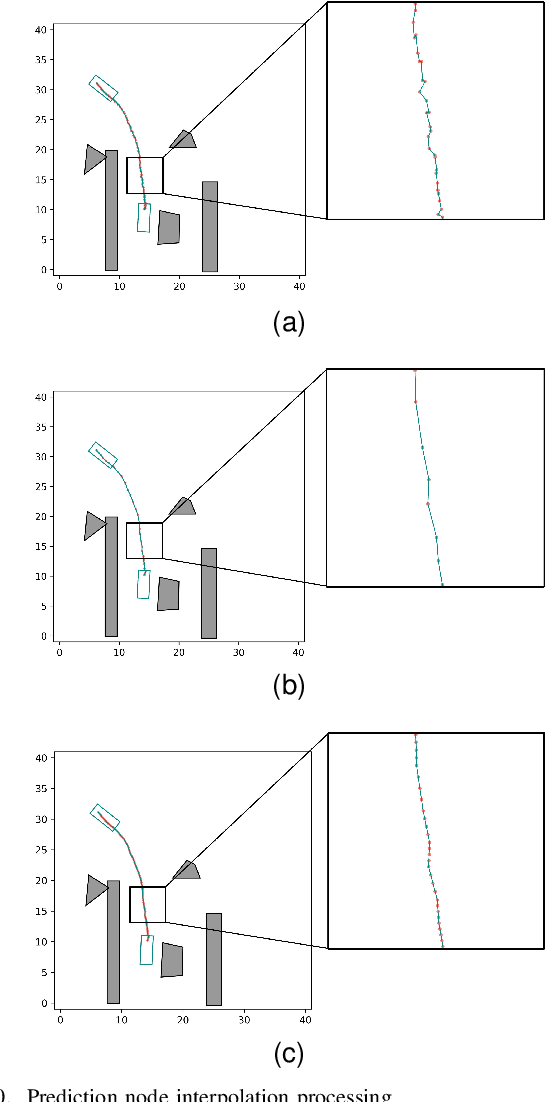
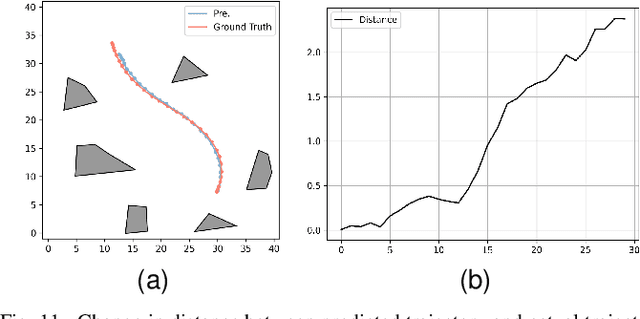
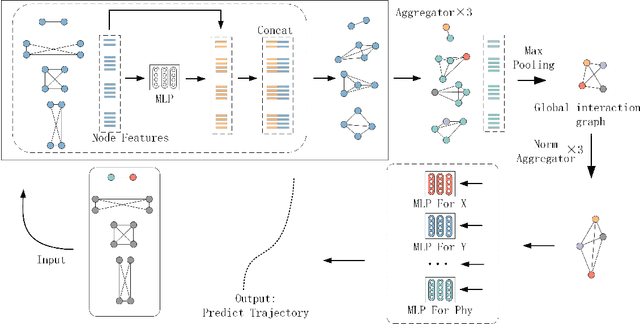
In unstructured environments, obstacles are diverse and lack lane markings, making trajectory planning for intelligent vehicles a challenging task. Traditional trajectory planning methods typically involve multiple stages, including path planning, speed planning, and trajectory optimization. These methods require the manual design of numerous parameters for each stage, resulting in significant workload and computational burden. While end-to-end trajectory planning methods are simple and efficient, they often fail to ensure that the trajectory meets vehicle dynamics and obstacle avoidance constraints in unstructured scenarios. Therefore, this paper proposes a novel trajectory planning method based on Graph Neural Networks (GNN) and numerical optimization. The proposed method consists of two stages: (1) initial trajectory prediction using the GNN, (2) trajectory optimization using numerical optimization. First, the graph neural network processes the environment information and predicts a rough trajectory, replacing traditional path and speed planning. This predicted trajectory serves as the initial solution for the numerical optimization stage, which optimizes the trajectory to ensure compliance with vehicle dynamics and obstacle avoidance constraints. We conducted simulation experiments to validate the feasibility of the proposed algorithm and compared it with other mainstream planning algorithms. The results demonstrate that the proposed method simplifies the trajectory planning process and significantly improves planning efficiency.
Decentralized Multi-Agent Reinforcement Learning: An Off-Policy Method
Oct 31, 2021

We discuss the problem of decentralized multi-agent reinforcement learning (MARL) in this work. In our setting, the global state, action, and reward are assumed to be fully observable, while the local policy is protected as privacy by each agent, and thus cannot be shared with others. There is a communication graph, among which the agents can exchange information with their neighbors. The agents make individual decisions and cooperate to reach a higher accumulated reward. Towards this end, we first propose a decentralized actor-critic (AC) setting. Then, the policy evaluation and policy improvement algorithms are designed for discrete and continuous state-action-space Markov Decision Process (MDP) respectively. Furthermore, convergence analysis is given under the discrete-space case, which guarantees that the policy will be reinforced by alternating between the processes of policy evaluation and policy improvement. In order to validate the effectiveness of algorithms, we design experiments and compare them with previous algorithms, e.g., Q-learning \cite{watkins1992q} and MADDPG \cite{lowe2017multi}. The results show that our algorithms perform better from the aspects of both learning speed and final performance. Moreover, the algorithms can be executed in an off-policy manner, which greatly improves the data efficiency compared with on-policy algorithms.
An Actor-Critic Method for Simulation-Based Optimization
Oct 31, 2021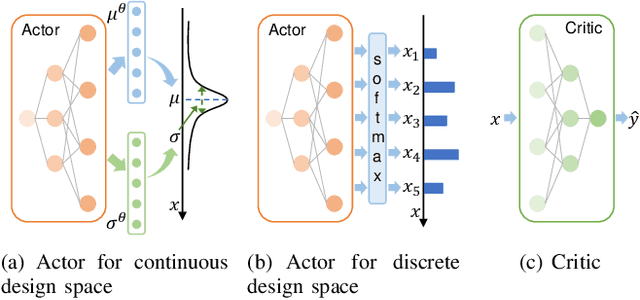
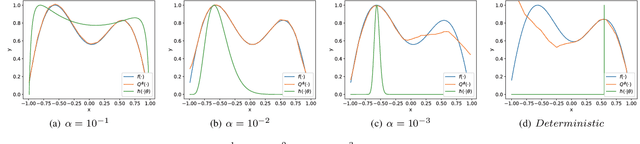
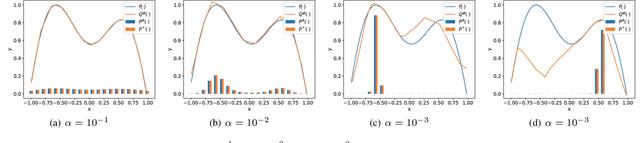
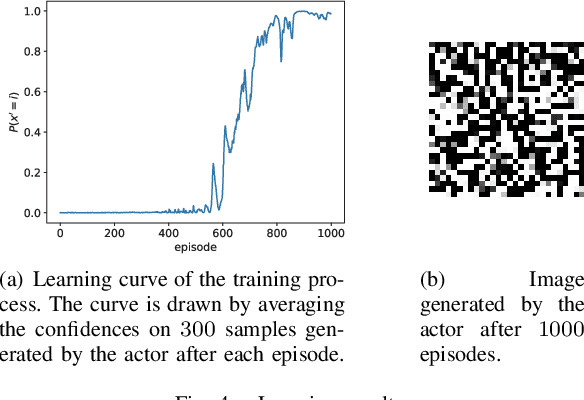
We focus on a simulation-based optimization problem of choosing the best design from the feasible space. Although the simulation model can be queried with finite samples, its internal processing rule cannot be utilized in the optimization process. We formulate the sampling process as a policy searching problem and give a solution from the perspective of Reinforcement Learning (RL). Concretely, Actor-Critic (AC) framework is applied, where the Actor serves as a surrogate model to predict the performance on unknown designs, whereas the actor encodes the sampling policy to be optimized. We design the updating rule and propose two algorithms for the cases where the feasible spaces are continuous and discrete respectively. Some experiments are designed to validate the effectiveness of proposed algorithms, including two toy examples, which intuitively explain the algorithms, and two more complex tasks, i.e., adversarial attack task and RL task, which validate the effectiveness in large-scale problems. The results show that the proposed algorithms can successfully deal with these problems. Especially note that in the RL task, our methods give a new perspective to robot control by treating the task as a simulation model and solving it by optimizing the policy generating process, while existing works commonly optimize the policy itself directly.