 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Actor-Critic Method for Simulation-Based Optimization
Paper and Code
Oct 31, 2021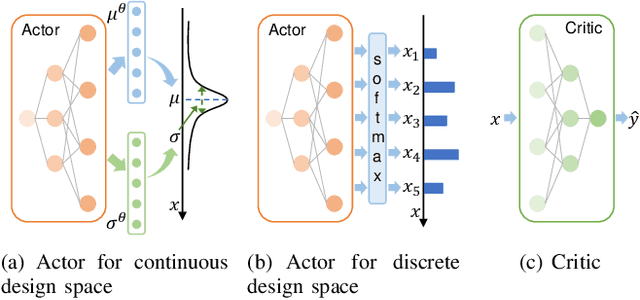
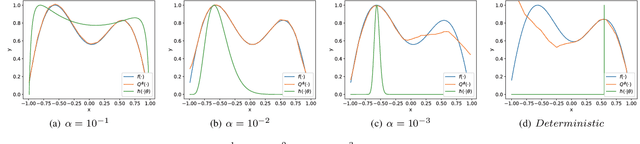
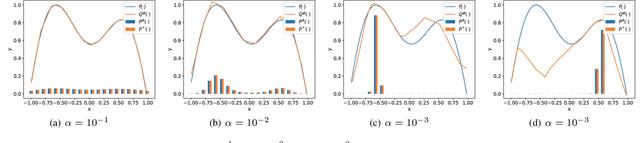
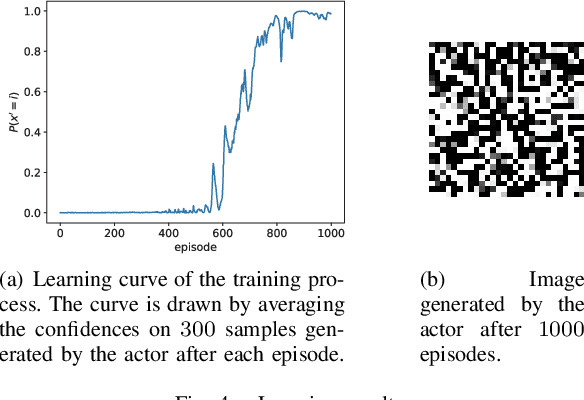
We focus on a simulation-based optimization problem of choosing the best design from the feasible space. Although the simulation model can be queried with finite samples, its internal processing rule cannot be utilized in the optimization process. We formulate the sampling process as a policy searching problem and give a solution from the perspective of Reinforcement Learning (RL). Concretely, Actor-Critic (AC) framework is applied, where the Actor serves as a surrogate model to predict the performance on unknown designs, whereas the actor encodes the sampling policy to be optimized. We design the updating rule and propose two algorithms for the cases where the feasible spaces are continuous and discrete respectively. Some experiments are designed to validate the effectiveness of proposed algorithms, including two toy examples, which intuitively explain the algorithms, and two more complex tasks, i.e., adversarial attack task and RL task, which validate the effectiveness in large-scale problems. The results show that the proposed algorithms can successfully deal with these problems. Especially note that in the RL task, our methods give a new perspective to robot control by treating the task as a simulation model and solving it by optimizing the policy generating process, while existing works commonly optimize the policy itself directly.