 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftVR: Real-Time One-Step Generative Video Restoration
Jun 08, 2026Real-time video restoration (VR) for live streams requires high-resolution outputs under strict per-frame latency constraints. Existing one-step diffusion-based VR models remain difficult to deploy on consumer-grade GPUs due to two main bottlenecks: quadratic spatial attention at high resolutions and the latency-memory overhead of large video autoencoders. We present SwiftVR, a streaming one-step generative VR framework that reduces both bottlenecks under a causal chunk-wise protocol. For attention, mask-free shifted-window self-attention gathers each spatial window into a dense tensor via deterministic indexing, keeping all attention calls on the dense scaled dot-product attention path without masks, cyclic shifts, padding, or hardware-specific sparse kernels. Because SwiftVR uses only standard dense SDPA calls, the trained model transfers to consumer GPUs without retraining or custom kernels. For autoencoding, a lightweight Restoration-aware Autoencoder enables fast chunk-wise decoding while preserving reconstruction quality. On a single H100, SwiftVR sustains 31~FPS at 2560x1440 and 14~FPS at 3840x2160, whereas all compared diffusion-based VR baselines exceed the memory limit at 4K. On a consumer RTX~5090, SwiftVR reaches 26~FPS at 1920x1080. To our knowledge, SwiftVR is the first generative VR model to achieve real-time 1080p streaming on a consumer-grade GPU, while attaining strong no-reference perceptual quality with lower inference cost. Project is available at https://h-oliday.github.io/SwiftVR.
Meta-Learning for Rapid Adaptation in Reference Tracking of Uncertain Nonlinear Systems
May 21, 2026In this paper, we address the problem of reference tracking for uncertain nonlinear systems. Since collecting data from the target system (i.e., the system of interest) is often challenging, our objective is to design optimal controllers using limited target system data. Meta-learning provides a promising paradigm by leveraging offline data from source systems (systems sharing structural similarities with the target system) to accelerate training and enhance control performance. Motivated by this idea, we propose a meta-learning-based control framework that tailors the implicit model-agnostic meta-learning (iMAML) algorithm to the control setting. The framework operates in two phases: an (offline) meta-training phase, where an aggregated representation is learned from source data to capture the shared system dynamics among similar systems, and an (online) meta-adaptation phase, where this representation is fine-tuned on the target system using only a few data samples and limited adaptation steps. We formulate this framework as a bi-level optimization problem and provide an efficient solution with reduced storage complexity and few approximations. The proposed framework is general, allowing various learning algorithms to be integrated. To demonstrate this flexibility, we propose two specific learning algorithms that can be incorporated into our framework based on a neural state-space model and a deep Q-network, respectively. The primary distinction between these approaches is whether explicit system identification is required. Numerical simulations and hardware experiments demonstrate that the proposed methods enhance control performance and consistently outperform baseline approaches.
Integrated cooperative localization of heterogeneous measurement swarm: A unified data-driven method
Mar 05, 2026The cooperative localization (CL) problem in heterogeneous robotic systems with different measurement capabilities is investigated in this work. In practice, heterogeneous sensors lead to directed and sparse measurement topologies, whereas most existing CL approaches rely on multilateral localization with restrictive multi-neighbor geometric requirements. To overcome this limitation, we enable pairwise relative localization (RL) between neighboring robots using only mutual measurement and odometry information. A unified data-driven adaptive RL estimator is first developed to handle heterogeneous and unidirectional measurements. Based on the convergent RL estimates, a distributed pose-coupling CL strategy is then designed, which guarantees CL under a weakly connected directed measurement topology, representing the least restrictive condition among existing results. The proposed method is independent of specific control tasks and is validated through a formation control application and real-world experiments.
Know Your Intent: An Autonomous Multi-Perspective LLM Agent Framework for DeFi User Transaction Intent Mining
Nov 19, 2025
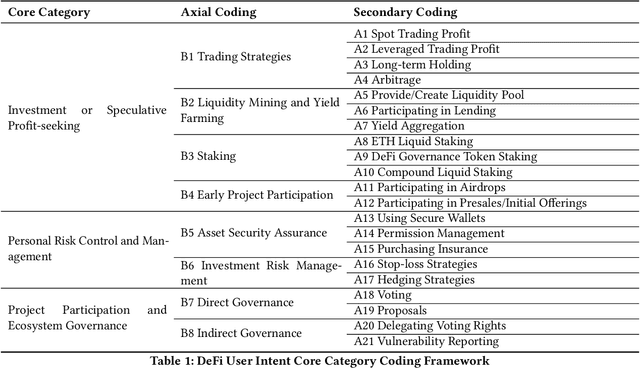
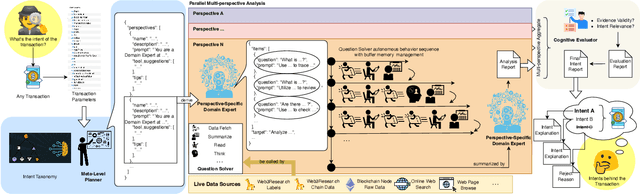
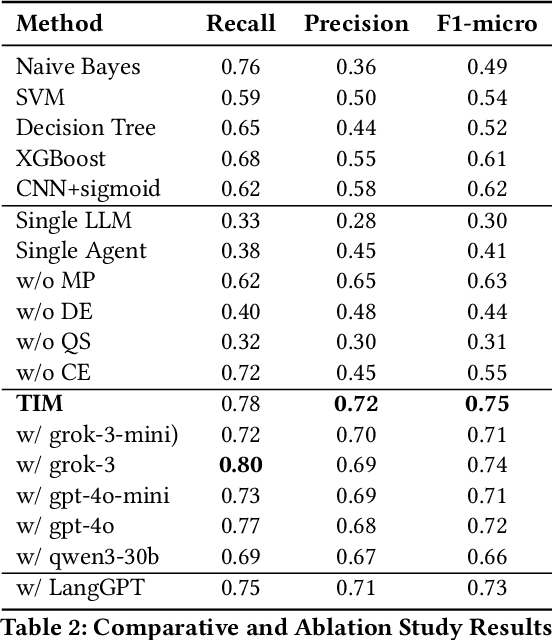
As Decentralized Finance (DeFi) develops, understanding user intent behind DeFi transactions is crucial yet challenging due to complex smart contract interactions, multifaceted on-/off-chain factors, and opaque hex logs. Existing methods lack deep semantic insight. To address this, we propose the Transaction Intent Mining (TIM) framework. TIM leverages a DeFi intent taxonomy built on grounded theory and a multi-agent Large Language Model (LLM) system to robustly infer user intents. A Meta-Level Planner dynamically coordinates domain experts to decompose multiple perspective-specific intent analyses into solvable subtasks. Question Solvers handle the tasks with multi-modal on/off-chain data. While a Cognitive Evaluator mitigates LLM hallucinations and ensures verifiability. Experiments show that TIM significantly outperforms machine learning models, single LLMs, and single Agent baselines. We also analyze core challenges in intent inference. This work helps provide a more reliable understanding of user motivations in DeFi, offering context-aware explanations for complex blockchain activity.
MPC of Uncertain Nonlinear Systems with Meta-Learning for Fast Adaptation of Neural Predictive Models
Apr 18, 2024



In this paper, we consider the problem of reference tracking in uncertain nonlinear systems. A neural State-Space Model (NSSM) is used to approximate the nonlinear system, where a deep encoder network learns the nonlinearity from data, and a state-space component captures the temporal relationship. This transforms the nonlinear system into a linear system in a latent space, enabling the application of model predictive control (MPC) to determine effective control actions. Our objective is to design the optimal controller using limited data from the \textit{target system} (the system of interest). To this end, we employ an implicit model-agnostic meta-learning (iMAML) framework that leverages information from \textit{source systems} (systems that share similarities with the target system) to expedite training in the target system and enhance its control performance. The framework consists of two phases: the (offine) meta-training phase learns a aggregated NSSM using data from source systems, and the (online) meta-inference phase quickly adapts this aggregated model to the target system using only a few data points and few online training iterations, based on local loss function gradients. The iMAML algorithm exploits the implicit function theorem to exactly compute the gradient during training, without relying on the entire optimization path. By focusing solely on the optimal solution, rather than the path, we can meta-train with less storage complexity and fewer approximations than other contemporary meta-learning algorithms. We demonstrate through numerical examples that our proposed method can yield accurate predictive models by adaptation, resulting in a downstream MPC that outperforms several baselines.
LitE-SNN: Designing Lightweight and Efficient Spiking Neural Network through Spatial-Temporal Compressive Network Search and Joint Optimization
Jan 26, 2024Spiking Neural Networks (SNNs) mimic the information-processing mechanisms of the human brain and are highly energy-efficient, making them well-suited for low-power edge devices. However, the pursuit of accuracy in current studies leads to large, long-timestep SNNs, conflicting with the resource constraints of these devices. In order to design lightweight and efficient SNNs, we propose a new approach named LitESNN that incorporates both spatial and temporal compression into the automated network design process. Spatially, we present a novel Compressive Convolution block (CompConv) to expand the search space to support pruning and mixed-precision quantization while utilizing the shared weights and pruning mask to reduce the computation. Temporally, we are the first to propose a compressive timestep search to identify the optimal number of timesteps under specific computation cost constraints. Finally, we formulate a joint optimization to simultaneously learn the architecture parameters and spatial-temporal compression strategies to achieve high performance while minimizing memory and computation costs. Experimental results on CIFAR10, CIFAR100, and Google Speech Command datasets demonstrate our proposed LitESNNs can achieve competitive or even higher accuracy with remarkably smaller model sizes and fewer computation costs. Furthermore, we validate the effectiveness of our LitESNN on the trade-off between accuracy and resource cost and show the superiority of our joint optimization. Additionally, we conduct energy analysis to further confirm the energy efficiency of LitESNN
Distributed Parameter Estimation with Gaussian Observation Noises in Time-varying Digraphs
Nov 08, 2023In this paper, we consider the problem of distributed parameter estimation in sensor networks. Each sensor makes successive observations of an unknown $d$-dimensional parameter, which might be subject to Gaussian random noises. The sensors aim to infer the true value of the unknown parameter by cooperating with each other. To this end, we first generalize the so-called dynamic regressor extension and mixing (DREM) algorithm to stochastic systems, with which the problem of estimating a $d$-dimensional vector parameter is transformed to that of $d$ scalar ones: one for each of the unknown parameters. For each of the scalar problem, both combine-then-adapt (CTA) and adapt-then-combine (ATC) diffusion-based estimation algorithms are given, where each sensor performs a combination step to fuse the local estimates in its in-neighborhood, alongside an adaptation step to process its streaming observations. Under weak conditions on network topology and excitation of regressors, we show that the proposed estimators guarantee that each sensor infers the true parameter, even if any individual of them cannot by itself. Specifically, it is required that the union of topologies over an interval with fixed length is strongly connected. Moreover, the sensors must collectively satisfy a cooperative persistent excitation (PE) condition, which relaxes the traditional PE condition. Numerical examples are finally provided to illustrate the established results.
An Actor-Critic Method for Simulation-Based Optimization
Oct 31, 2021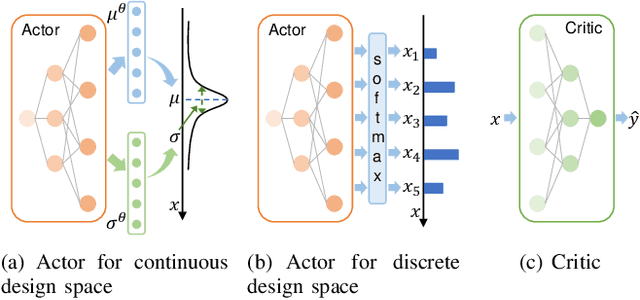
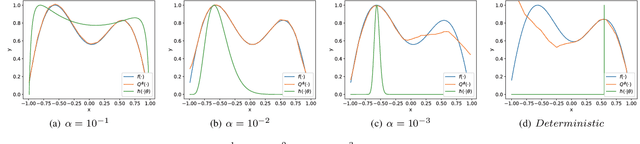
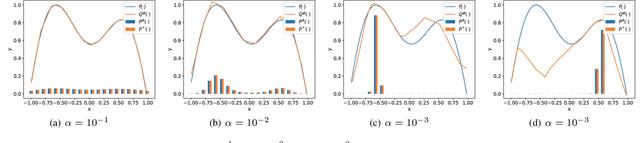
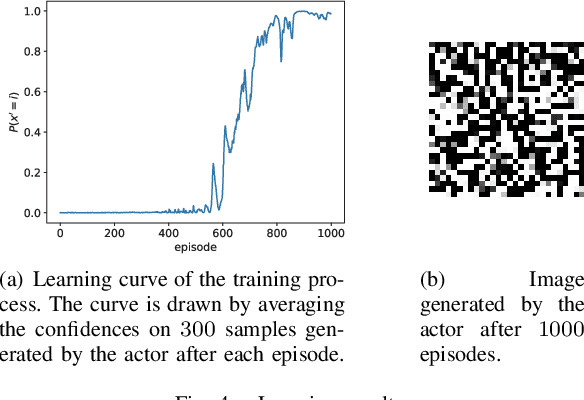
We focus on a simulation-based optimization problem of choosing the best design from the feasible space. Although the simulation model can be queried with finite samples, its internal processing rule cannot be utilized in the optimization process. We formulate the sampling process as a policy searching problem and give a solution from the perspective of Reinforcement Learning (RL). Concretely, Actor-Critic (AC) framework is applied, where the Actor serves as a surrogate model to predict the performance on unknown designs, whereas the actor encodes the sampling policy to be optimized. We design the updating rule and propose two algorithms for the cases where the feasible spaces are continuous and discrete respectively. Some experiments are designed to validate the effectiveness of proposed algorithms, including two toy examples, which intuitively explain the algorithms, and two more complex tasks, i.e., adversarial attack task and RL task, which validate the effectiveness in large-scale problems. The results show that the proposed algorithms can successfully deal with these problems. Especially note that in the RL task, our methods give a new perspective to robot control by treating the task as a simulation model and solving it by optimizing the policy generating process, while existing works commonly optimize the policy itself directly.
Query2Vec: An Evaluation of NLP Techniques for Generalized Workload Analytics
Feb 02, 2018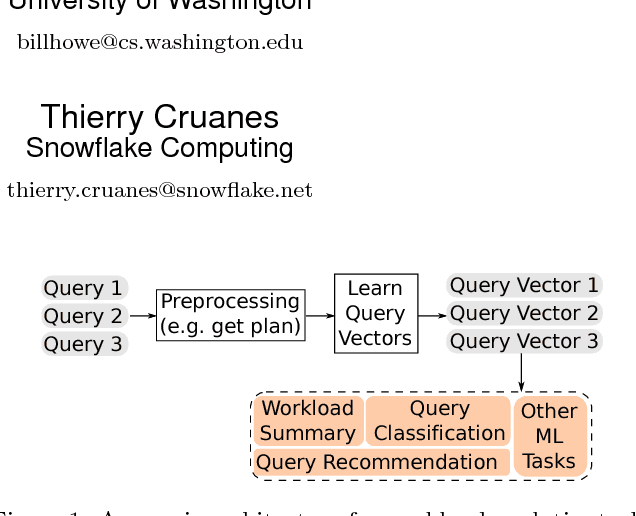

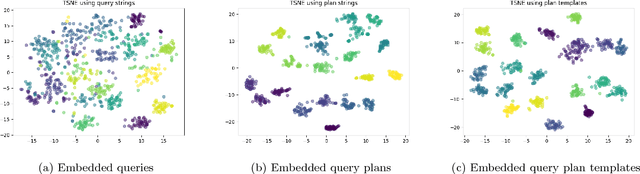
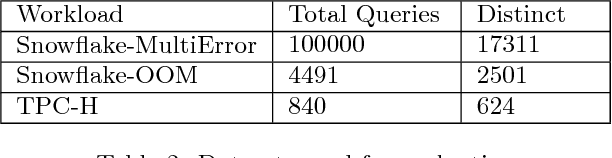
We consider methods for learning vector representations of SQL queries to support generalized workload analytics tasks, including workload summarization for index selection and predicting queries that will trigger memory errors. We consider vector representations of both raw SQL text and optimized query plans, and evaluate these methods on synthetic and real SQL workloads. We find that general algorithms based on vector representations can outperform existing approaches that rely on specialized features. For index recommendation, we cluster the vector representations to compress large workloads with no loss in performance from the recommended index. For error prediction, we train a classifier over learned vectors that can automatically relate subtle syntactic patterns with specific errors raised during query execution. Surprisingly, we also find that these methods enable transfer learning, where a model trained on one SQL corpus can be applied to an unrelated corpus and still enable good performance. We find that these general approaches, when trained on a large corpus of SQL queries, provides a robust foundation for a variety of workload analysis tasks and database features, without requiring application-specific feature engineering.