 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-based Multi-Objective Reinforcement Learning
Jul 18, 2025Multi-objective reinforcement learning (MORL) is a structured approach for optimizing tasks with multiple objectives. However, it often relies on pre-defined reward functions, which can be hard to design for balancing conflicting goals and may lead to oversimplification. Preferences can serve as more flexible and intuitive decision-making guidance, eliminating the need for complicated reward design. This paper introduces preference-based MORL (Pb-MORL), which formalizes the integration of preferences into the MORL framework. We theoretically prove that preferences can derive policies across the entire Pareto frontier. To guide policy optimization using preferences, our method constructs a multi-objective reward model that aligns with the given preferences. We further provide theoretical proof to show that optimizing this reward model is equivalent to training the Pareto optimal policy. Extensive experiments in benchmark multi-objective tasks, a multi-energy management task, and an autonomous driving task on a multi-line highway show that our method performs competitively, surpassing the oracle method, which uses the ground truth reward function. This highlights its potential for practical applications in complex real-world systems.
Towards provable probabilistic safety for scalable embodied AI systems
Jun 05, 2025Embodied AI systems, comprising AI models and physical plants, are increasingly prevalent across various applications. Due to the rarity of system failures, ensuring their safety in complex operating environments remains a major challenge, which severely hinders their large-scale deployment in safety-critical domains, such as autonomous vehicles, medical devices, and robotics. While achieving provable deterministic safety--verifying system safety across all possible scenarios--remains theoretically ideal, the rarity and complexity of corner cases make this approach impractical for scalable embodied AI systems. To address this challenge, we introduce provable probabilistic safety, which aims to ensure that the residual risk of large-scale deployment remains below a predefined threshold. Instead of attempting exhaustive safety proof across all corner cases, this paradigm establishes a probabilistic safety boundary on overall system performance, leveraging statistical methods to enhance feasibility and scalability. A well-defined probabilistic safety boundary enables embodied AI systems to be deployed at scale while allowing for continuous refinement of safety guarantees. Our work focuses on three core questions: what is provable probabilistic safety, how to prove the probabilistic safety, and how to achieve the provable probabilistic safety. By bridging the gap between theoretical safety assurance and practical deployment, our work offers a pathway toward safer, large-scale adoption of embodied AI systems in safety-critical applications.
Feasibility-Aware Pessimistic Estimation: Toward Long-Horizon Safety in Offline RL
May 13, 2025Offline safe reinforcement learning(OSRL) derives constraint-satisfying policies from pre-collected datasets, offers a promising avenue for deploying RL in safety-critical real-world domains such as robotics. However, the majority of existing approaches emphasize only short-term safety, neglecting long-horizon considerations. Consequently, they may violate safety constraints and fail to ensure sustained protection during online deployment. Moreover, the learned policies often struggle to handle states and actions that are not present or out-of-distribution(OOD) from the offline dataset, and exhibit limited sample efficiency. To address these challenges, we propose a novel framework Feasibility-Aware offline Safe Reinforcement Learning with CVAE-based Pessimism (FASP). First, we employ Hamilton-Jacobi (H-J) reachability analysis to generate reliable safety labels, which serve as supervisory signals for training both a conditional variational autoencoder (CVAE) and a safety classifier. This approach not only ensures high sampling efficiency but also provides rigorous long-horizon safety guarantees. Furthermore, we utilize pessimistic estimation methods to estimate the Q-value of reward and cost, which mitigates the extrapolation errors induces by OOD actions, and penalize unsafe actions to enabled the agent to proactively avoid high-risk behaviors. Moreover, we theoretically prove the validity of this pessimistic estimation. Extensive experiments on DSRL benchmarks demonstrate that FASP algorithm achieves competitive performance across multiple experimental tasks, particularly outperforming state-of-the-art algorithms in terms of safety.
Query-Policy Misalignment in Preference-Based Reinforcement Learning
May 27, 2023



Preference-based reinforcement learning (PbRL) provides a natural way to align RL agents' behavior with human desired outcomes, but is often restrained by costly human feedback. To improve feedback efficiency, most existing PbRL methods focus on selecting queries to maximally improve the overall quality of the reward model, but counter-intuitively, we find that this may not necessarily lead to improved performance. To unravel this mystery, we identify a long-neglected issue in the query selection schemes of existing PbRL studies: Query-Policy Misalignment. We show that the seemingly informative queries selected to improve the overall quality of reward model actually may not align with RL agents' interests, thus offering little help on policy learning and eventually resulting in poor feedback efficiency. We show that this issue can be effectively addressed via near on-policy query and a specially designed hybrid experience replay, which together enforce the bidirectional query-policy alignment. Simple yet elegant, our method can be easily incorporated into existing approaches by changing only a few lines of code. We showcase in comprehensive experiments that our method achieves substantial gains in both human feedback and RL sample efficiency, demonstrating the importance of addressing query-policy misalignment in PbRL tasks.
Mind the Gap: Offline Policy Optimization for Imperfect Rewards
Feb 03, 2023



Reward function is essential in reinforcement learning (RL), serving as the guiding signal to incentivize agents to solve given tasks, however, is also notoriously difficult to design. In many cases, only imperfect rewards are available, which inflicts substantial performance loss for RL agents. In this study, we propose a unified offline policy optimization approach, \textit{RGM (Reward Gap Minimization)}, which can smartly handle diverse types of imperfect rewards. RGM is formulated as a bi-level optimization problem: the upper layer optimizes a reward correction term that performs visitation distribution matching w.r.t. some expert data; the lower layer solves a pessimistic RL problem with the corrected rewards. By exploiting the duality of the lower layer, we derive a tractable algorithm that enables sampled-based learning without any online interactions. Comprehensive experiments demonstrate that RGM achieves superior performance to existing methods under diverse settings of imperfect rewards. Further, RGM can effectively correct wrong or inconsistent rewards against expert preference and retrieve useful information from biased rewards.
Decentralized Multi-Agent Reinforcement Learning: An Off-Policy Method
Oct 31, 2021

We discuss the problem of decentralized multi-agent reinforcement learning (MARL) in this work. In our setting, the global state, action, and reward are assumed to be fully observable, while the local policy is protected as privacy by each agent, and thus cannot be shared with others. There is a communication graph, among which the agents can exchange information with their neighbors. The agents make individual decisions and cooperate to reach a higher accumulated reward. Towards this end, we first propose a decentralized actor-critic (AC) setting. Then, the policy evaluation and policy improvement algorithms are designed for discrete and continuous state-action-space Markov Decision Process (MDP) respectively. Furthermore, convergence analysis is given under the discrete-space case, which guarantees that the policy will be reinforced by alternating between the processes of policy evaluation and policy improvement. In order to validate the effectiveness of algorithms, we design experiments and compare them with previous algorithms, e.g., Q-learning \cite{watkins1992q} and MADDPG \cite{lowe2017multi}. The results show that our algorithms perform better from the aspects of both learning speed and final performance. Moreover, the algorithms can be executed in an off-policy manner, which greatly improves the data efficiency compared with on-policy algorithms.
An Actor-Critic Method for Simulation-Based Optimization
Oct 31, 2021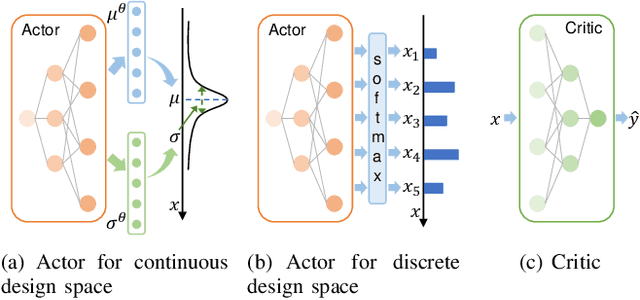
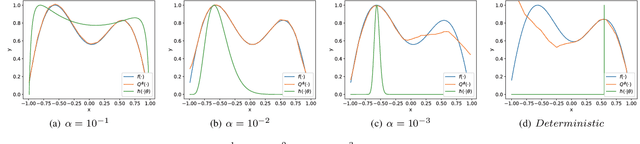
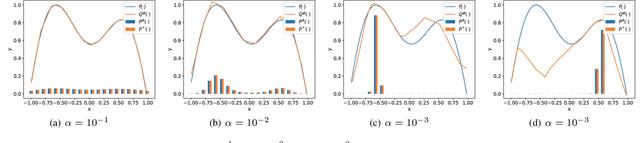
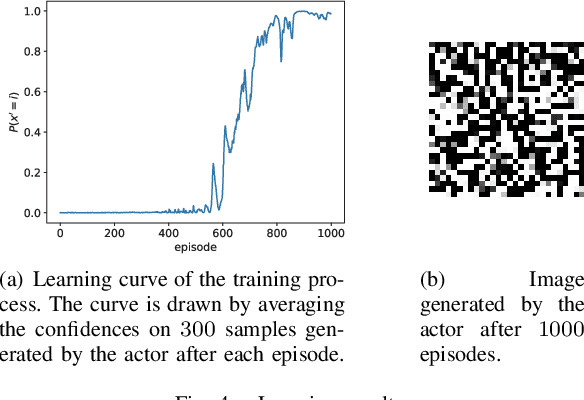
We focus on a simulation-based optimization problem of choosing the best design from the feasible space. Although the simulation model can be queried with finite samples, its internal processing rule cannot be utilized in the optimization process. We formulate the sampling process as a policy searching problem and give a solution from the perspective of Reinforcement Learning (RL). Concretely, Actor-Critic (AC) framework is applied, where the Actor serves as a surrogate model to predict the performance on unknown designs, whereas the actor encodes the sampling policy to be optimized. We design the updating rule and propose two algorithms for the cases where the feasible spaces are continuous and discrete respectively. Some experiments are designed to validate the effectiveness of proposed algorithms, including two toy examples, which intuitively explain the algorithms, and two more complex tasks, i.e., adversarial attack task and RL task, which validate the effectiveness in large-scale problems. The results show that the proposed algorithms can successfully deal with these problems. Especially note that in the RL task, our methods give a new perspective to robot control by treating the task as a simulation model and solving it by optimizing the policy generating process, while existing works commonly optimize the policy itself directly.