 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVPR 2023 Text Guided Video Editing Competition
Oct 24, 2023Humans watch more than a billion hours of video per day. Most of this video was edited manually, which is a tedious process. However, AI-enabled video-generation and video-editing is on the rise. Building on text-to-image models like Stable Diffusion and Imagen, generative AI has improved dramatically on video tasks. But it's hard to evaluate progress in these video tasks because there is no standard benchmark. So, we propose a new dataset for text-guided video editing (TGVE), and we run a competition at CVPR to evaluate models on our TGVE dataset. In this paper we present a retrospective on the competition and describe the winning method. The competition dataset is available at https://sites.google.com/view/loveucvpr23/track4.
MAE-GEBD:Winning the CVPR'2023 LOVEU-GEBD Challenge
Jun 27, 2023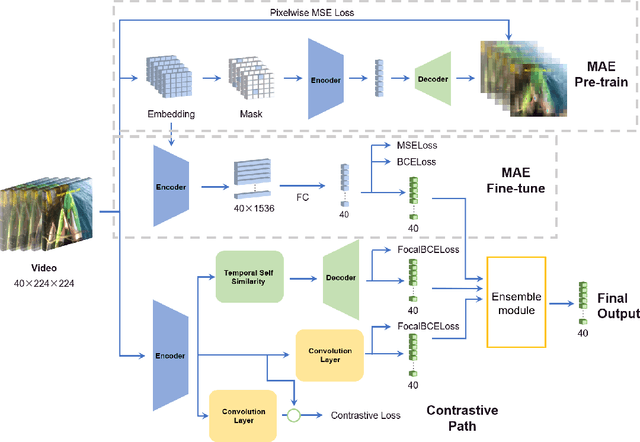
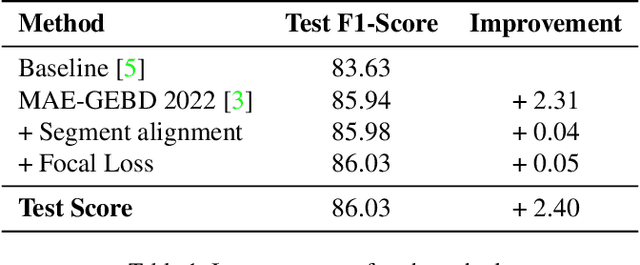
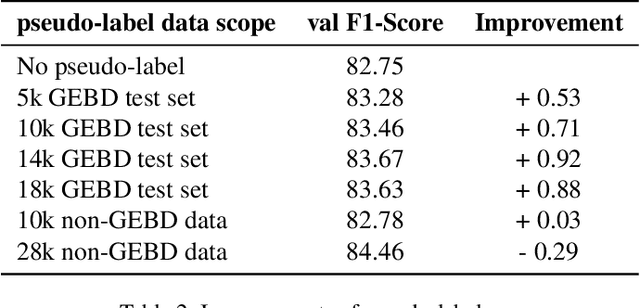
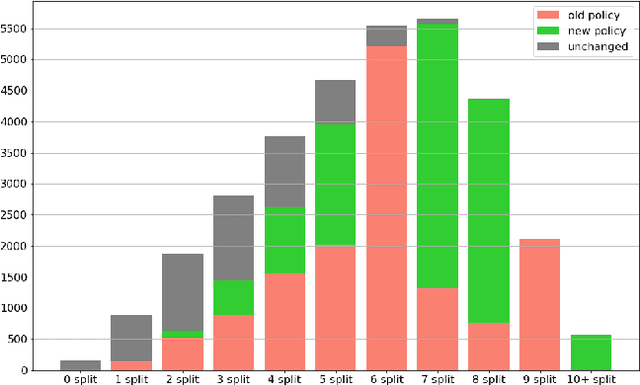
The Generic Event Boundary Detection (GEBD) task aims to build a model for segmenting videos into segments by detecting general event boundaries applicable to various classes. In this paper, based on last year's MAE-GEBD method, we have improved our model performance on the GEBD task by adjusting the data processing strategy and loss function. Based on last year's approach, we extended the application of pseudo-label to a larger dataset and made many experimental attempts. In addition, we applied focal loss to concentrate more on difficult samples and improved our model performance. Finally, we improved the segmentation alignment strategy used last year, and dynamically adjusted the segmentation alignment method according to the boundary density and duration of the video, so that our model can be more flexible and fully applicable in different situations. With our method, we achieve an F1 score of 86.03% on the Kinetics-GEBD test set, which is a 0.09% improvement in the F1 score compared to our 2022 Kinetics-GEBD method.
Masked Autoencoders for Generic Event Boundary Detection CVPR'2022 Kinetics-GEBD Challenge
Jun 17, 2022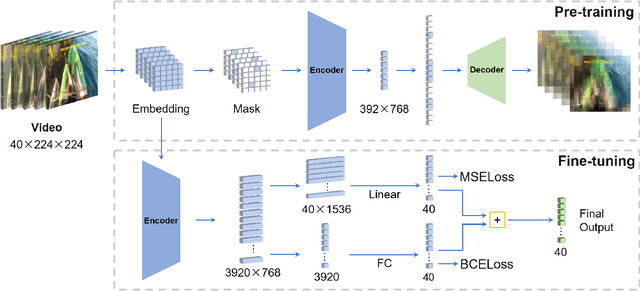
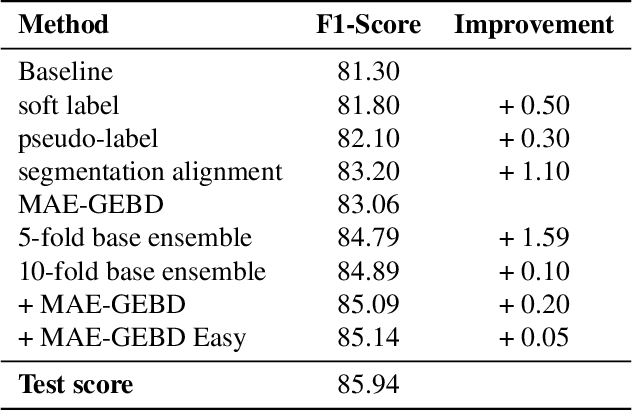
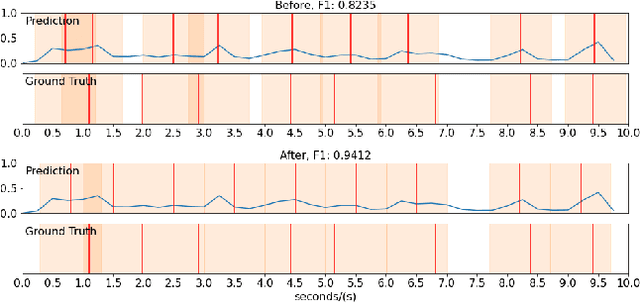
Generic Event Boundary Detection (GEBD) tasks aim at detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. In this paper, we apply Masked Autoencoders to improve algorithm performance on the GEBD tasks. Our approach mainly adopted the ensemble of Masked Autoencoders fine-tuned on the GEBD task as a self-supervised learner with other base models. Moreover, we also use a semi-supervised pseudo-label method to take full advantage of the abundant unlabeled Kinetics-400 data while training. In addition, we propose a soft-label method to partially balance the positive and negative samples and alleviate the problem of ambiguous labeling in this task. Lastly, a tricky segmentation alignment policy is implemented to refine boundaries predicted by our models to more accurate locations. With our approach, we achieved 85.94% on the F1-score on the Kinetics-GEBD test set, which improved the F1-score by 2.31% compared to the winner of the 2021 Kinetics-GEBD Challenge. Our code is available at https://github.com/ContentAndMaterialPortrait/MAE-GEBD.