 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models can be Guided to Evade AI-Generated Text Detection
Paper and Code


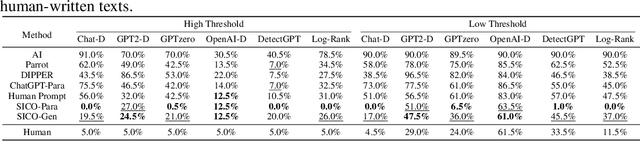

Large Language Models (LLMs) have demonstrated exceptional performance in a variety of tasks, including essay writing and question answering. However, it is crucial to address the potential misuse of these models, which can lead to detrimental outcomes such as plagiarism and spamming. Recently, several detectors have been proposed, including fine-tuned classifiers and various statistical methods. In this study, we reveal that with the aid of carefully crafted prompts, LLMs can effectively evade these detection systems. We propose a novel Substitution-based In-Context example Optimization method (SICO) to automatically generate such prompts. On three real-world tasks where LLMs can be misused, SICO successfully enables ChatGPT to evade six existing detectors, causing a significant 0.54 AUC drop on average. Surprisingly, in most cases these detectors perform even worse than random classifiers. These results firmly reveal the vulnerability of existing detectors. Finally, the strong performance of SICO suggests itself as a reliable evaluation protocol for any new detector in this field.