 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep vs. Deep Bayesian: Reinforcement Learning on a Multi-Robot Competitive Experiment
Paper and Code
Jul 21, 2020
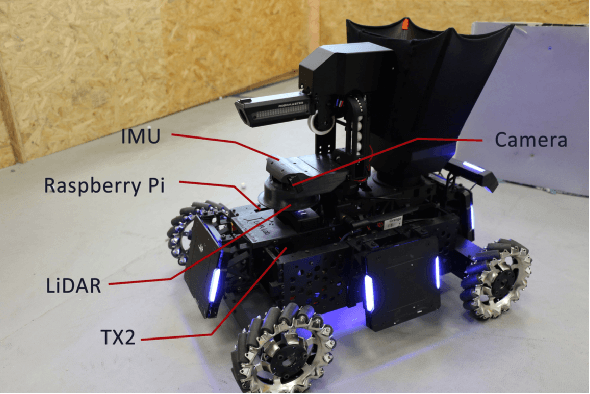
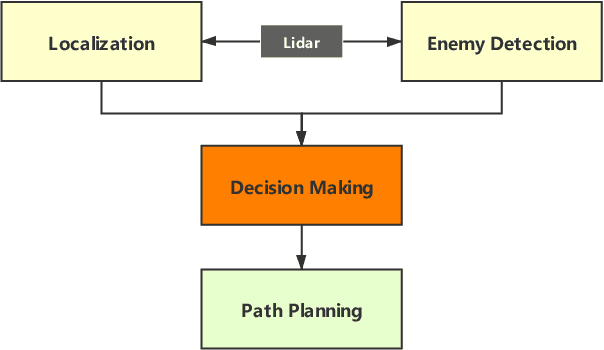
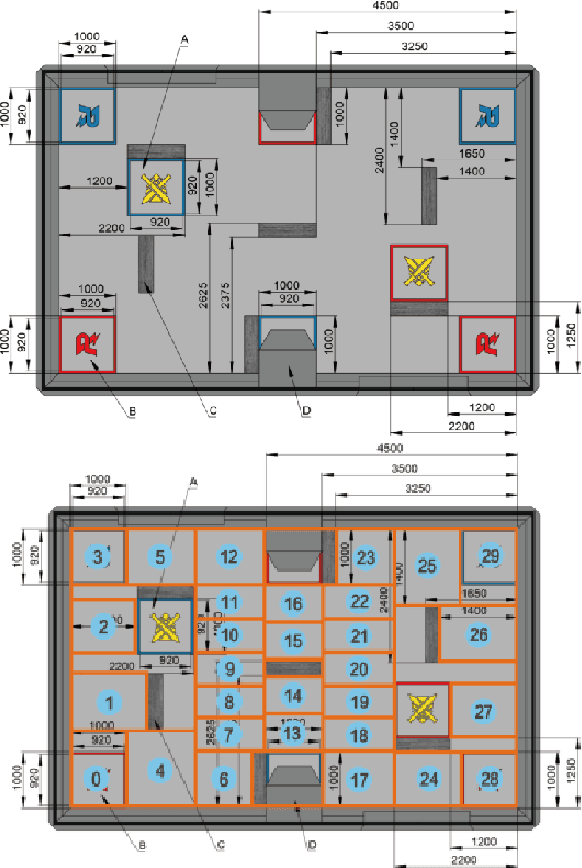
Deep Reinforcement Learning (RL) experiments are commonly performed in simulated environment, due to the tremendous training sample demand from deep neural networks. However, model-based Deep Bayesian RL, such as Deep PILCO, allows a robot to learn good policies within few trials in the real world. Although Deep PILCO has been applied on many single-robot tasks, in here we propose, for the first time, an application of Deep PILCO on a multi-robot confrontation game, and compare the algorithm with a model-free Deep RL algorithm, Deep Q-Learning. Our experiments show that Deep PILCO significantly outperforms Deep Q-Learning in learning efficiency and scalability. We conclude that sample-efficient Deep Bayesian learning algorithms have great prospects on competitive games where the agent aims to win the opponents in the real world, as opposed to simulated applications.