 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetis: A Generalizable and Efficient World-Action Model for Autonomous Driving and Urban Navigation
Jun 14, 2026World action models~(WAMs) have shown great promise for autonomous driving and urban navigation. Built upon Vision-Language-Action models or video generation models, existing approaches suffer key limitations: (1) High inference latency due to future observation prediction at test time, and (2) tightly coupled video and action modeling leading to representational mismatch and degraded generalization. To address both issues, we propose Metis, an end-to-end WAM framework that decouples video generation and action prediction. Specifically, Metis employs a Mixture-of-Transformers architecture with dedicated experts for video generation and action prediction, preserving the intrinsic distributional properties of each task. To enhance efficiency, we introduce an asymmetric attention mask that enables joint training of both experts while allowing the action model to bypass explicit video generation during inference. This design ensures training-inference consistency and significantly reduces computational costs without compromising planning performance. Extensive experiments demonstrate state-of-the-art performance on the NAVSIM navhard and navtest benchmarks and the CityWalker navigation benchmark, validating both the generalizability and efficiency across diverse tasks. Real-robot deployments further confirm the practical feasibility of our approach.
TokenFLEX: Unified VLM Training for Flexible Visual Tokens Inference
Apr 04, 2025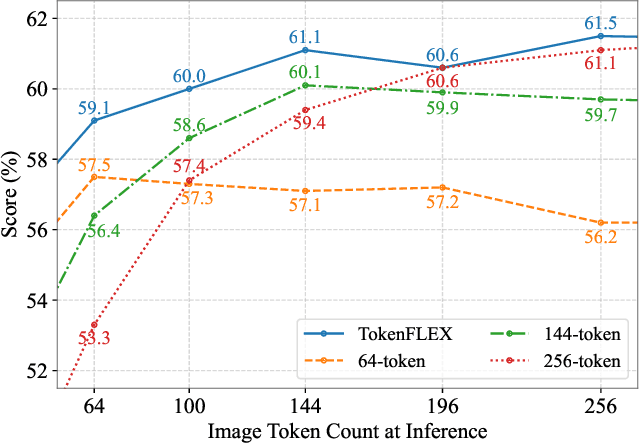
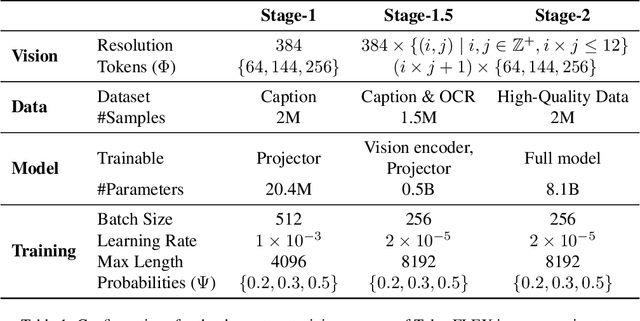
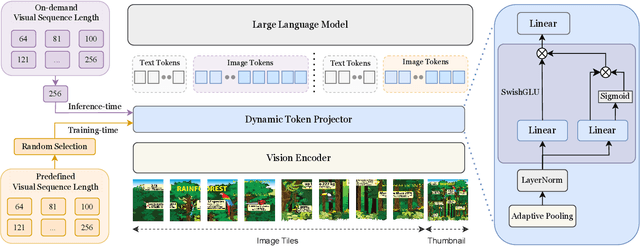
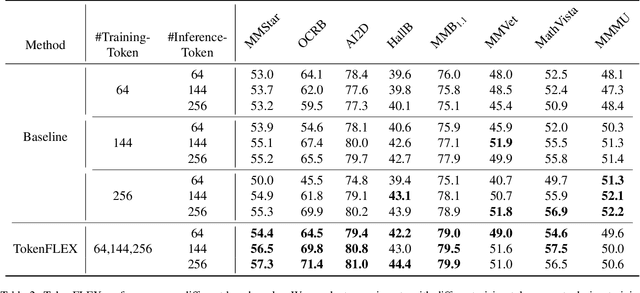
Conventional Vision-Language Models(VLMs) typically utilize a fixed number of vision tokens, regardless of task complexity. This one-size-fits-all strategy introduces notable inefficiencies: using excessive tokens leads to unnecessary computational overhead in simpler tasks, whereas insufficient tokens compromise fine-grained visual comprehension in more complex contexts. To overcome these limitations, we present TokenFLEX, an innovative and adaptable vision-language framework that encodes images into a variable number of tokens for efficient integration with a Large Language Model (LLM). Our approach is underpinned by two pivotal innovations. Firstly, we present a novel training paradigm that enhances performance across varying numbers of vision tokens by stochastically modulating token counts during training. Secondly, we design a lightweight vision token projector incorporating an adaptive pooling layer and SwiGLU, allowing for flexible downsampling of vision tokens and adaptive selection of features tailored to specific token counts. Comprehensive experiments reveal that TokenFLEX consistently outperforms its fixed-token counterparts, achieving notable performance gains across various token counts enhancements of 1.6%, 1.0%, and 0.4% with 64, 144, and 256 tokens, respectively averaged over eight vision-language benchmarks. These results underscore TokenFLEX's remarkable flexibility while maintaining high-performance vision-language understanding.
Label-guided Attention Distillation for Lane Segmentation
Apr 04, 2023



Contemporary segmentation methods are usually based on deep fully convolutional networks (FCNs). However, the layer-by-layer convolutions with a growing receptive field is not good at capturing long-range contexts such as lane markers in the scene. In this paper, we address this issue by designing a distillation method that exploits label structure when training segmentation network. The intuition is that the ground-truth lane annotations themselves exhibit internal structure. We broadcast the structure hints throughout a teacher network, i.e., we train a teacher network that consumes a lane label map as input and attempts to replicate it as output. Then, the attention maps of the teacher network are adopted as supervisors of the student segmentation network. The teacher network, with label structure information embedded, knows distinctly where the convolution layers should pay visual attention into. The proposed method is named as Label-guided Attention Distillation (LGAD). It turns out that the student network learns significantly better with LGAD than when learning alone. As the teacher network is deprecated after training, our method do not increase the inference time. Note that LGAD can be easily incorporated in any lane segmentation network.
* Accepted to Neurocomputing 2021
SimpleNet: A Simple Network for Image Anomaly Detection and Localization
Mar 28, 2023



We propose a simple and application-friendly network (called SimpleNet) for detecting and localizing anomalies. SimpleNet consists of four components: (1) a pre-trained Feature Extractor that generates local features, (2) a shallow Feature Adapter that transfers local features towards target domain, (3) a simple Anomaly Feature Generator that counterfeits anomaly features by adding Gaussian noise to normal features, and (4) a binary Anomaly Discriminator that distinguishes anomaly features from normal features. During inference, the Anomaly Feature Generator would be discarded. Our approach is based on three intuitions. First, transforming pre-trained features to target-oriented features helps avoid domain bias. Second, generating synthetic anomalies in feature space is more effective, as defects may not have much commonality in the image space. Third, a simple discriminator is much efficient and practical. In spite of simplicity, SimpleNet outperforms previous methods quantitatively and qualitatively. On the MVTec AD benchmark, SimpleNet achieves an anomaly detection AUROC of 99.6%, reducing the error by 55.5% compared to the next best performing model. Furthermore, SimpleNet is faster than existing methods, with a high frame rate of 77 FPS on a 3080ti GPU. Additionally, SimpleNet demonstrates significant improvements in performance on the One-Class Novelty Detection task. Code: https://github.com/DonaldRR/SimpleNet.
Rearranging the Environment to Maximize Energy with a Robotic Circuit Drawing
Nov 15, 2021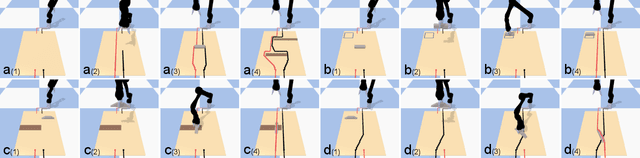
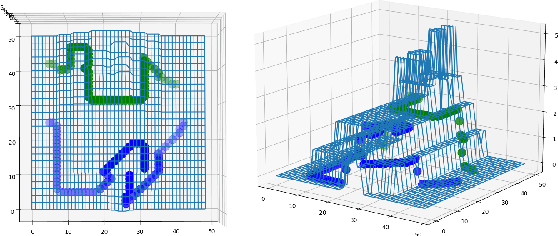

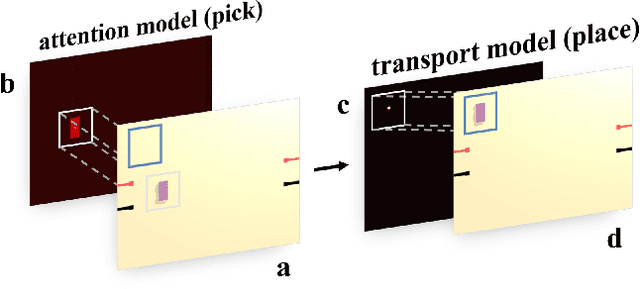
Robots with the ability to actively acquire power from surroundings will be greatly beneficial for long-term autonomy and to survive in uncertain environments. In this work, we present a robot capable of drawing circuits with conductive ink while also rearranging the visual world to receive maximum energy from a power source. A range of circuit drawing tasks is designed to simulate real-world scenarios, including avoiding physical obstacles and regions that would discontinue drawn circuits. We adopt the state-of-the-art Transporter networks for pick-and-place manipulation from visual observation. We conduct experiments in both simulation and real-world settings, and our results show that, with a small number of demonstrations, the robot learns to rearrange the placement of objects (removing obstacles and bridging areas unsuitable for drawing) and to connect a power source with a minimum amount of conductive ink. As autonomous robots become more present, in our houses and other planets, our proposed method brings a novel way for machines to keep themselves functional by rearranging their surroundings to create their own electric circuits.