 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenFLEX: Unified VLM Training for Flexible Visual Tokens Inference
Apr 04, 2025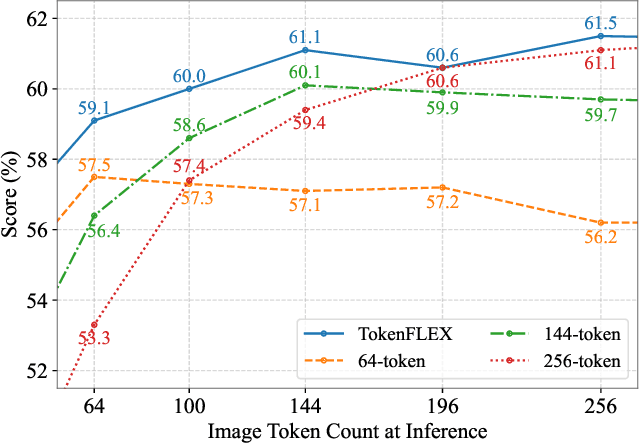
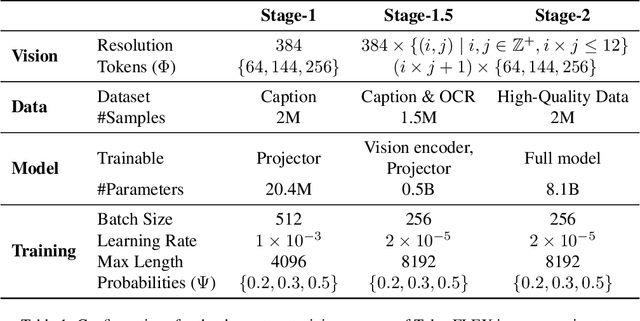
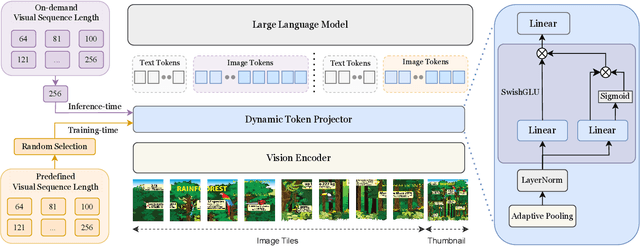
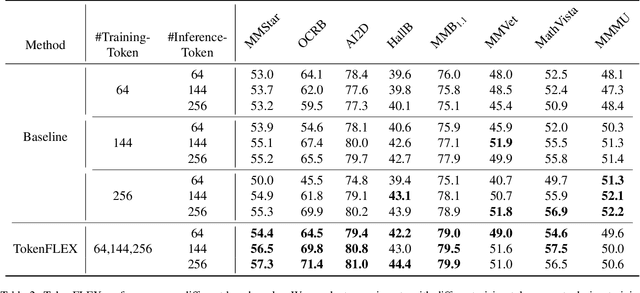
Conventional Vision-Language Models(VLMs) typically utilize a fixed number of vision tokens, regardless of task complexity. This one-size-fits-all strategy introduces notable inefficiencies: using excessive tokens leads to unnecessary computational overhead in simpler tasks, whereas insufficient tokens compromise fine-grained visual comprehension in more complex contexts. To overcome these limitations, we present TokenFLEX, an innovative and adaptable vision-language framework that encodes images into a variable number of tokens for efficient integration with a Large Language Model (LLM). Our approach is underpinned by two pivotal innovations. Firstly, we present a novel training paradigm that enhances performance across varying numbers of vision tokens by stochastically modulating token counts during training. Secondly, we design a lightweight vision token projector incorporating an adaptive pooling layer and SwiGLU, allowing for flexible downsampling of vision tokens and adaptive selection of features tailored to specific token counts. Comprehensive experiments reveal that TokenFLEX consistently outperforms its fixed-token counterparts, achieving notable performance gains across various token counts enhancements of 1.6%, 1.0%, and 0.4% with 64, 144, and 256 tokens, respectively averaged over eight vision-language benchmarks. These results underscore TokenFLEX's remarkable flexibility while maintaining high-performance vision-language understanding.
Balancing Risk and Reward: An Automated Phased Release Strategy
May 16, 2023Phased releases are a common strategy in the technology industry for gradually releasing new products or updates through a sequence of A/B tests in which the number of treated units gradually grows until full deployment or deprecation. Performing phased releases in a principled way requires selecting the proportion of units assigned to the new release in a way that balances the risk of an adverse effect with the need to iterate and learn from the experiment rapidly. In this paper, we formalize this problem and propose an algorithm that automatically determines the release percentage at each stage in the schedule, balancing the need to control risk while maximizing ramp-up speed. Our framework models the challenge as a constrained batched bandit problem that ensures that our pre-specified experimental budget is not depleted with high probability. Our proposed algorithm leverages an adaptive Bayesian approach in which the maximal number of units assigned to the treatment is determined by the posterior distribution, ensuring that the probability of depleting the remaining budget is low. Notably, our approach analytically solves the ramp sizes by inverting probability bounds, eliminating the need for challenging rare-event Monte Carlo simulation. It only requires computing means and variances of outcome subsets, making it highly efficient and parallelizable.