 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
Hierarchical Macro Strategy Model for MOBA Game AI
Dec 19, 2018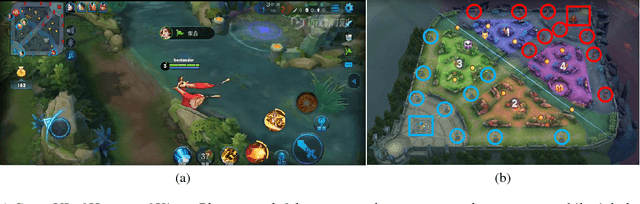

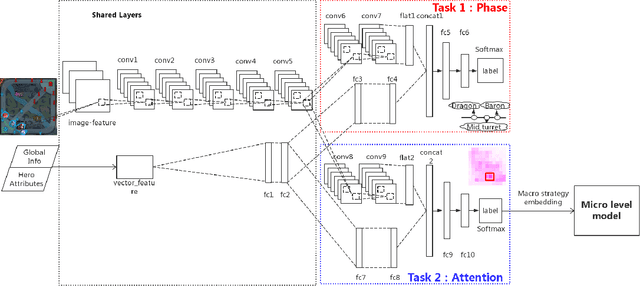
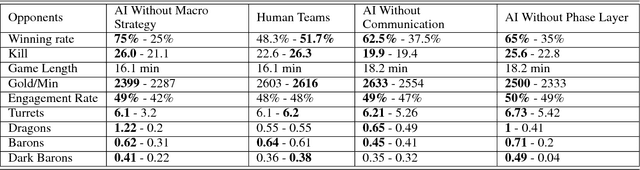
The next challenge of game AI lies in Real Time Strategy (RTS) games. RTS games provide partially observable gaming environments, where agents interact with one another in an action space much larger than that of GO. Mastering RTS games requires both strong macro strategies and delicate micro level execution. Recently, great progress has been made in micro level execution, while complete solutions for macro strategies are still lacking. In this paper, we propose a novel learning-based Hierarchical Macro Strategy model for mastering MOBA games, a sub-genre of RTS games. Trained by the Hierarchical Macro Strategy model, agents explicitly make macro strategy decisions and further guide their micro level execution. Moreover, each of the agents makes independent strategy decisions, while simultaneously communicating with the allies through leveraging a novel imitated cross-agent communication mechanism. We perform comprehensive evaluations on a popular 5v5 Multiplayer Online Battle Arena (MOBA) game. Our 5-AI team achieves a 48% winning rate against human player teams which are ranked top 1% in the player ranking system.
TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game
Nov 02, 2018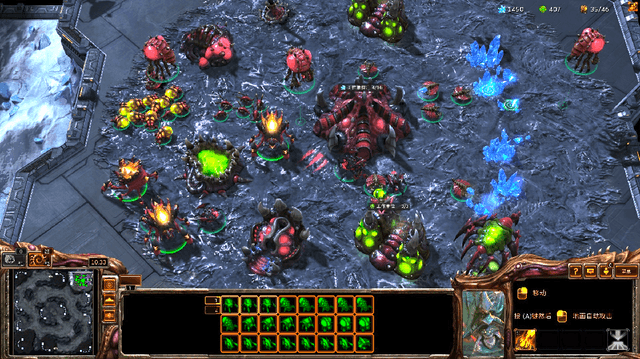

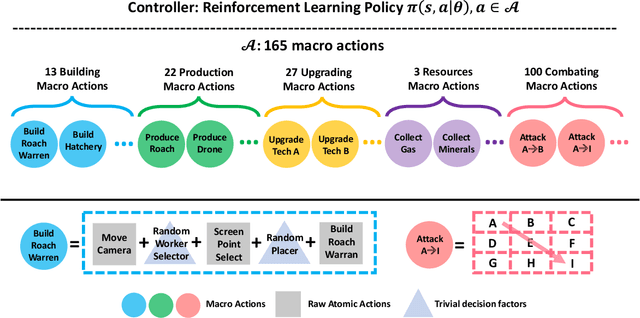

Starcraft II (SC2) is widely considered as the most challenging Real Time Strategy (RTS) game. The underlying challenges include a large observation space, a huge (continuous and infinite) action space, partial observations, simultaneous move for all players, and long horizon delayed rewards for local decisions. To push the frontier of AI research, Deepmind and Blizzard jointly developed the StarCraft II Learning Environment (SC2LE) as a testbench of complex decision making systems. SC2LE provides a few mini games such as MoveToBeacon, CollectMineralShards, and DefeatRoaches, where some AI agents have achieved the performance level of human professional players. However, for full games, the current AI agents are still far from achieving human professional level performance. To bridge this gap, we present two full game AI agents in this paper - the AI agent TStarBot1 is based on deep reinforcement learning over a flat action structure, and the AI agent TStarBot2 is based on hard-coded rules over a hierarchical action structure. Both TStarBot1 and TStarBot2 are able to defeat the built-in AI agents from level 1 to level 10 in a full game (1v1 Zerg-vs-Zerg game on the AbyssalReef map), noting that level 8, level 9, and level 10 are cheating agents with unfair advantages such as full vision on the whole map and resource harvest boosting. To the best of our knowledge, this is the first public work to investigate AI agents that can defeat the built-in AI in the StarCraft II full game.
Modeling Varying Camera-IMU Time Offset in Optimization-Based Visual-Inertial Odometry
Oct 12, 2018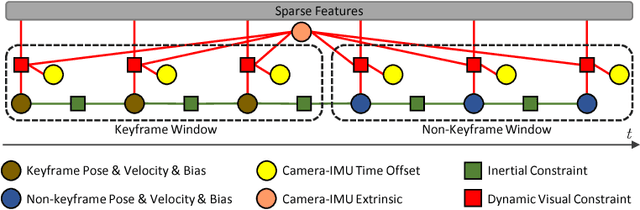
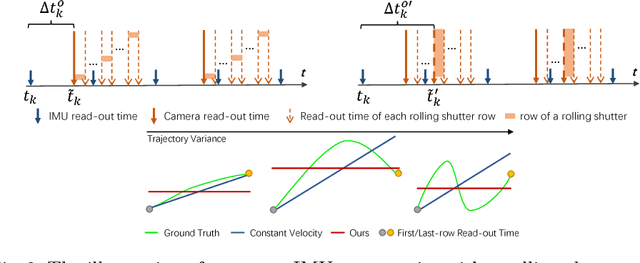
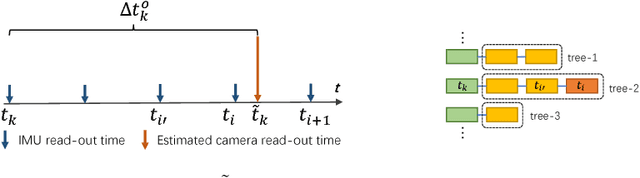
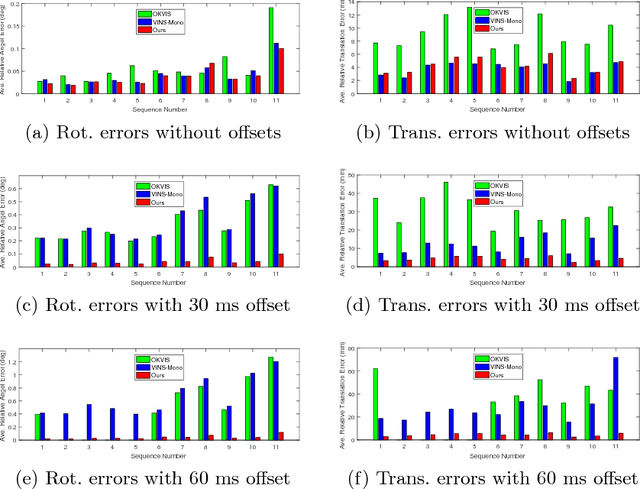
Combining cameras and inertial measurement units (IMUs) has been proven effective in motion tracking, as these two sensing modalities offer complementary characteristics that are suitable for fusion. While most works focus on global-shutter cameras and synchronized sensor measurements, consumer-grade devices are mostly equipped with rolling-shutter cameras and suffer from imperfect sensor synchronization. In this work, we propose a nonlinear optimization-based monocular visual inertial odometry (VIO) with varying camera-IMU time offset modeled as an unknown variable. Our approach is able to handle the rolling-shutter effects and imperfect sensor synchronization in a unified way. Additionally, we introduce an efficient algorithm based on dynamic programming and red-black tree to speed up IMU integration over variable-length time intervals during the optimization. An uncertainty-aware initialization is also presented to launch the VIO robustly. Comparisons with state-of-the-art methods on the Euroc dataset and mobile phone data are shown to validate the effectiveness of our approach.