 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Social to Individuals: a Parsimonious Path of Multi-level Models for Crowdsourced Preference Aggregation
Paper and Code



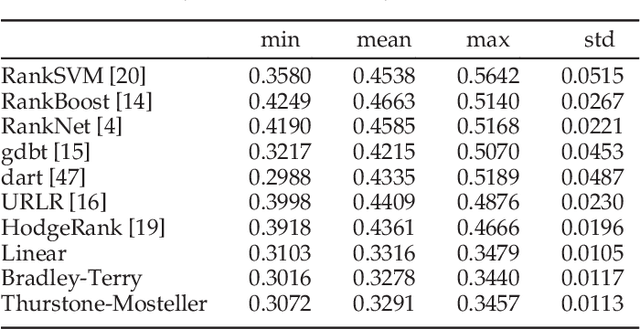
In crowdsourced preference aggregation, it is often assumed that all the annotators are subject to a common preference or social utility function which generates their comparison behaviors in experiments. However, in reality annotators are subject to variations due to multi-criteria, abnormal, or a mixture of such behaviors. In this paper, we propose a parsimonious mixed-effects model, which takes into account both the fixed effect that the majority of annotators follows a common linear utility model, and the random effect that some annotators might deviate from the common significantly and exhibit strongly personalized preferences. The key algorithm in this paper establishes a dynamic path from the social utility to individual variations, with different levels of sparsity on personalization. The algorithm is based on the Linearized Bregman Iterations, which leads to easy parallel implementations to meet the need of large-scale data analysis. In this unified framework, three kinds of random utility models are presented, including the basic linear model with L2 loss, Bradley-Terry model, and Thurstone-Mosteller model. The validity of these multi-level models are supported by experiments with both simulated and real-world datasets, which shows that the parsimonious multi-level models exhibit improvements in both interpretability and predictive precision compared with traditional HodgeRank.