 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real Transfer for Audio-Visual Navigation with Frequency-Adaptive Acoustic Field Prediction
May 05, 2024Sim2real transfer has received increasing attention lately due to the success of learning robotic tasks in simulation end-to-end. While there has been a lot of progress in transferring vision-based navigation policies, the existing sim2real strategy for audio-visual navigation performs data augmentation empirically without measuring the acoustic gap. The sound differs from light in that it spans across much wider frequencies and thus requires a different solution for sim2real. We propose the first treatment of sim2real for audio-visual navigation by disentangling it into acoustic field prediction (AFP) and waypoint navigation. We first validate our design choice in the SoundSpaces simulator and show improvement on the Continuous AudioGoal navigation benchmark. We then collect real-world data to measure the spectral difference between the simulation and the real world by training AFP models that only take a specific frequency subband as input. We further propose a frequency-adaptive strategy that intelligently selects the best frequency band for prediction based on both the measured spectral difference and the energy distribution of the received audio, which improves the performance on the real data. Lastly, we build a real robot platform and show that the transferred policy can successfully navigate to sounding objects. This work demonstrates the potential of building intelligent agents that can see, hear, and act entirely from simulation, and transferring them to the real world.
On the Planning, Search, and Memorization Capabilities of Large Language Models
Sep 05, 2023



The rapid advancement of large language models, such as the Generative Pre-trained Transformer (GPT) series, has had significant implications across various disciplines. In this study, we investigate the potential of the state-of-the-art large language model (GPT-4) for planning tasks. We explore its effectiveness in multiple planning subfields, highlighting both its strengths and limitations. Through a comprehensive examination, we identify areas where large language models excel in solving planning problems and reveal the constraints that limit their applicability. Our empirical analysis focuses on GPT-4's performance in planning domain extraction, graph search path planning, and adversarial planning. We then propose a way of fine-tuning a domain-specific large language model to improve its Chain of Thought (CoT) capabilities for the above-mentioned tasks. The results provide valuable insights into the potential applications of large language models in the planning domain and pave the way for future research to overcome their limitations and expand their capabilities.
How Good is a Video Summary? A New Benchmarking Dataset and Evaluation Framework Towards Realistic Video Summarization
Jan 26, 2021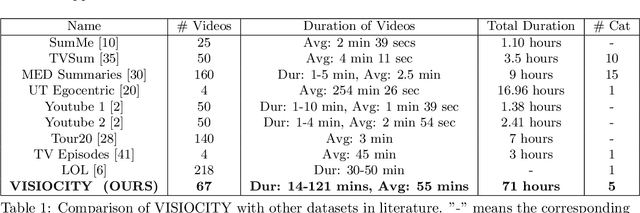
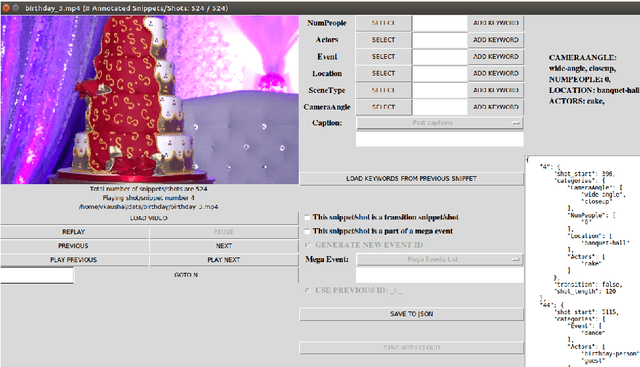
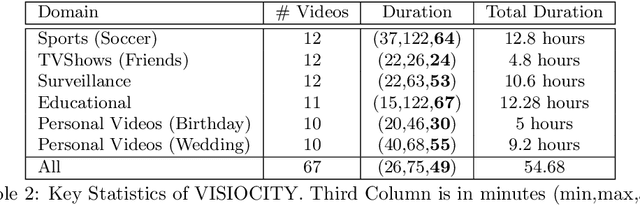
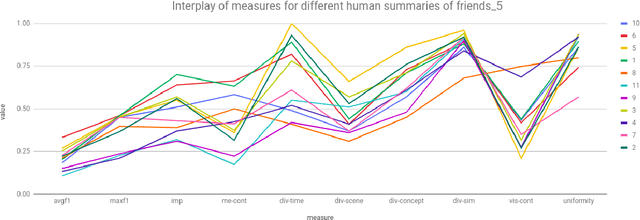
Automatic video summarization is still an unsolved problem due to several challenges. The currently available datasets either have very short videos or have few long videos of only a particular type. We introduce a new benchmarking video dataset called VISIOCITY (VIdeo SummarIzatiOn based on Continuity, Intent and DiversiTY) which comprises of longer videos across six different categories with dense concept annotations capable of supporting different flavors of video summarization and other vision problems. For long videos, human reference summaries necessary for supervised video summarization techniques are difficult to obtain. We explore strategies to automatically generate multiple reference summaries from indirect ground truth present in VISIOCITY. We show that these summaries are at par with human summaries. We also present a study of different desired characteristics of a good summary and demonstrate how it is normal to have two good summaries with different characteristics. Thus we argue that evaluating a summary against one or more human summaries and using a single measure has its shortcomings. We propose an evaluation framework for better quantitative assessment of summary quality which is closer to human judgment. Lastly, we present insights into how a model can be enhanced to yield better summaries. Sepcifically, when multiple diverse ground truth summaries can exist, learning from them individually and using a combination of loss functions measuring different characteristics is better than learning from a single combined (oracle) ground truth summary using a single loss function. We demonstrate the effectiveness of doing so as compared to some of the representative state of the art techniques tested on VISIOCITY. We release VISIOCITY as a benchmarking dataset and invite researchers to test the effectiveness of their video summarization algorithms on VISIOCITY.