 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodular Mutual Information for Targeted Data Subset Selection
Paper and Code
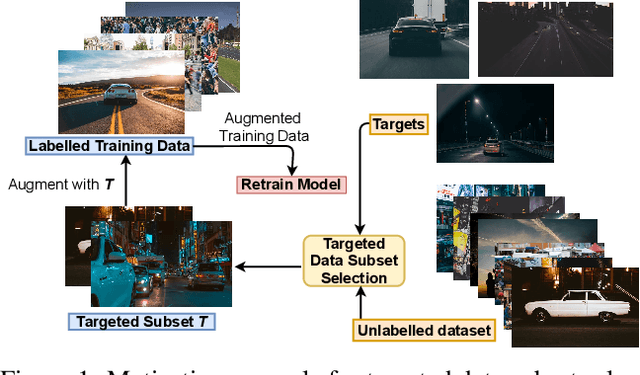
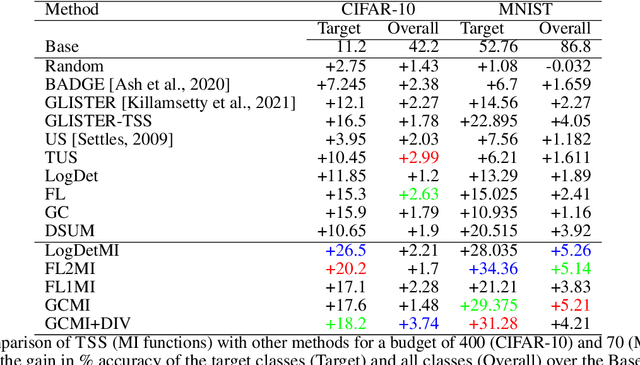
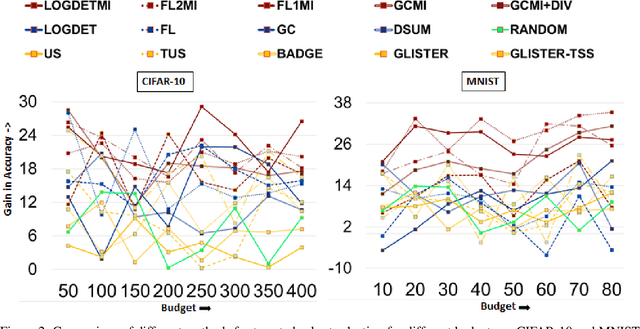
With the rapid growth of data, it is becoming increasingly difficult to train or improve deep learning models with the right subset of data. We show that this problem can be effectively solved at an additional labeling cost by targeted data subset selection(TSS) where a subset of unlabeled data points similar to an auxiliary set are added to the training data. We do so by using a rich class of Submodular Mutual Information (SMI) functions and demonstrate its effectiveness for image classification on CIFAR-10 and MNIST datasets. Lastly, we compare the performance of SMI functions for TSS with other state-of-the-art methods for closely related problems like active learning. Using SMI functions, we observe ~20-30% gain over the model's performance before re-training with added targeted subset; ~12% more than other methods.