 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Gender and Racial Disparities in Image Recognition Models
Paper and Code
Jul 20, 2021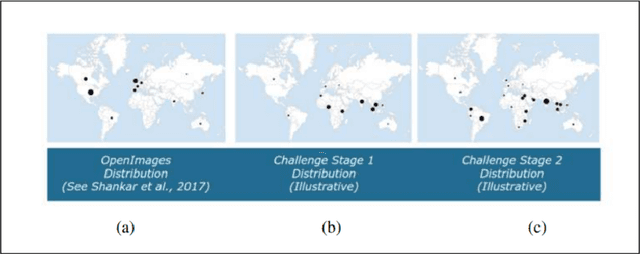
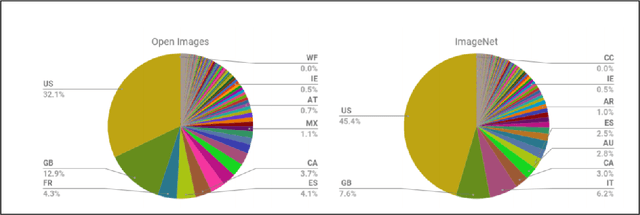


Large scale image classification models trained on top of popular datasets such as Imagenet have shown to have a distributional skew which leads to disparities in prediction accuracies across different subsections of population demographics. A lot of approaches have been made to solve for this distributional skew using methods that alter the model pre, post and during training. We investigate one such approach - which uses a multi-label softmax loss with cross-entropy as the loss function instead of a binary cross-entropy on a multi-label classification problem on the Inclusive Images dataset which is a subset of the OpenImages V6 dataset. We use the MR2 dataset, which contains images of people with self-identified gender and race attributes to evaluate the fairness in the model outcomes and try to interpret the mistakes by looking at model activations and suggest possible fixes.