 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Language Identification Using Convolutional Recurrent Neural Network
May 18, 2017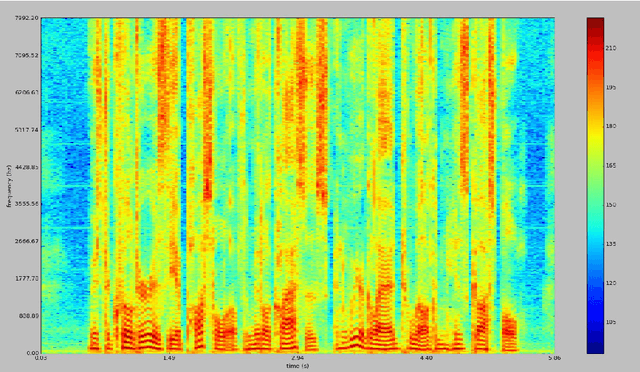
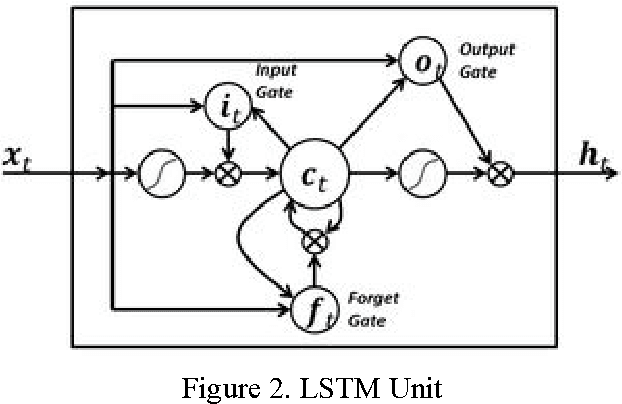
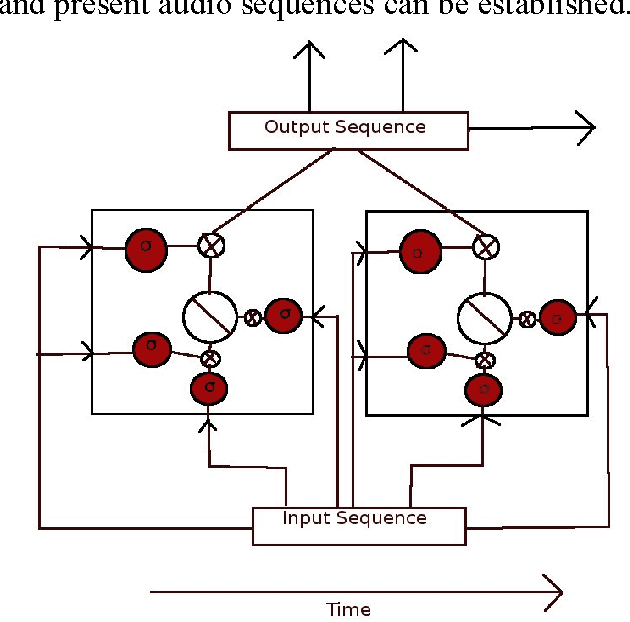
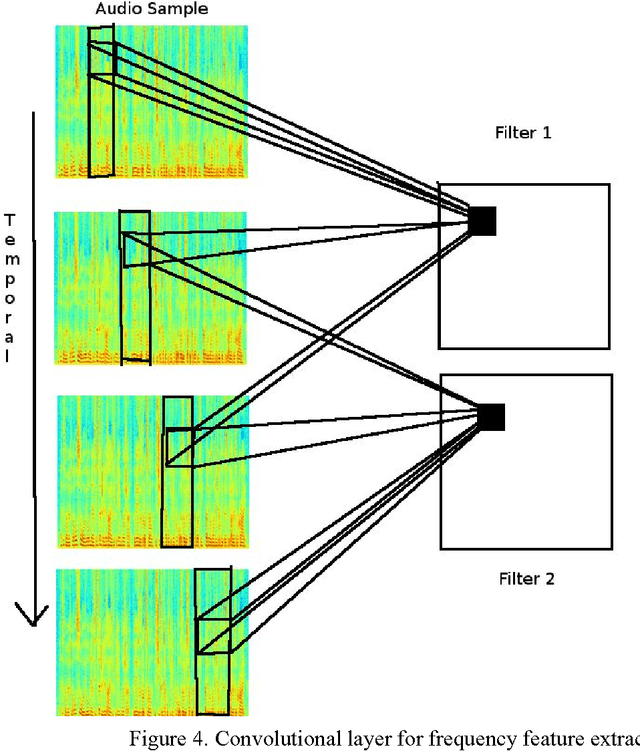
Language Identification, being an important aspect of Automatic Speaker Recognition has had many changes and new approaches to ameliorate performance over the last decade. We compare the performance of using audio spectrum in the log scale and using Polyphonic sound sequences from raw audio samples to train the neural network and to classify speech as either English or Spanish. To achieve this, we use the novel approach of using a Convolutional Recurrent Neural Network using Long Short Term Memory (LSTM) or a Gated Recurrent Unit (GRU) for forward propagation of the neural network. Our hypothesis is that the performance of using polyphonic sound sequence as features and both LSTM and GRU as the gating mechanisms for the neural network outperform the traditional MFCC features using a unidirectional Deep Neural Network.