 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Recognition using Ambient Sound for Supervision
Paper and Code
Dec 25, 2019
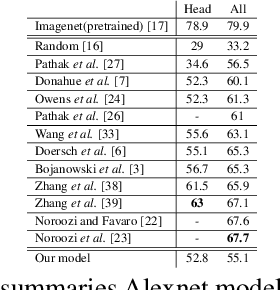

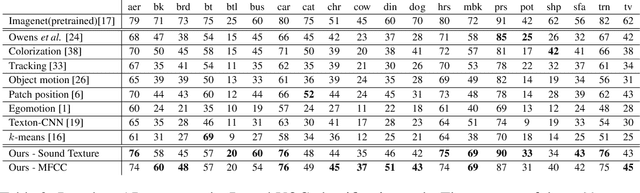
Our brains combine vision and hearing to create a more elaborate interpretation of the world. When the visual input is insufficient, a rich panoply of sounds can be used to describe our surroundings. Since more than 1,000 hours of videos are uploaded to the internet everyday, it is arduous, if not impossible, to manually annotate these videos. Therefore, incorporating audio along with visual data without annotations is crucial for leveraging this explosion of data for recognizing and understanding objects and scenes. Owens,et.al suggest that a rich representation of the physical world can be learned by using a convolutional neural network to predict sound textures associated with a given video frame. We attempt to reproduce the claims from their experiments, of which the code is not publicly available. In addition, we propose improvements in the pretext task that result in better performance in other downstream computer vision tasks.