 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Ranking Utility Tuning in the Ad Recommender System at Pinterest
Sep 05, 2025



The ranking utility function in an ad recommender system, which linearly combines predictions of various business goals, plays a central role in balancing values across the platform, advertisers, and users. Traditional manual tuning, while offering simplicity and interpretability, often yields suboptimal results due to its unprincipled tuning objectives, the vast amount of parameter combinations, and its lack of personalization and adaptability to seasonality. In this work, we propose a general Deep Reinforcement Learning framework for Personalized Utility Tuning (DRL-PUT) to address the challenges of multi-objective optimization within ad recommender systems. Our key contributions include: 1) Formulating the problem as a reinforcement learning task: given the state of an ad request, we predict the optimal hyperparameters to maximize a pre-defined reward. 2) Developing an approach to directly learn an optimal policy model using online serving logs, avoiding the need to estimate a value function, which is inherently challenging due to the high variance and unbalanced distribution of immediate rewards. We evaluated DRL-PUT through an online A/B experiment in Pinterest's ad recommender system. Compared to the baseline manual utility tuning approach, DRL-PUT improved the click-through rate by 9.7% and the long click-through rate by 7.7% on the treated segment. We conducted a detailed ablation study on the impact of different reward definitions and analyzed the personalization aspect of the learned policy model.
Taming the One-Epoch Phenomenon in Online Recommendation System by Two-stage Contrastive ID Pre-training
Aug 26, 2025



ID-based embeddings are widely used in web-scale online recommendation systems. However, their susceptibility to overfitting, particularly due to the long-tail nature of data distributions, often limits training to a single epoch, a phenomenon known as the "one-epoch problem." This challenge has driven research efforts to optimize performance within the first epoch by enhancing convergence speed or feature sparsity. In this study, we introduce a novel two-stage training strategy that incorporates a pre-training phase using a minimal model with contrastive loss, enabling broader data coverage for the embedding system. Our offline experiments demonstrate that multi-epoch training during the pre-training phase does not lead to overfitting, and the resulting embeddings improve online generalization when fine-tuned for more complex downstream recommendation tasks. We deployed the proposed system in live traffic at Pinterest, achieving significant site-wide engagement gains.
* Published at RecSys'24, see https://dl.acm.org/doi/10.1145/3640457.3688053
RecoMind: A Reinforcement Learning Framework for Optimizing In-Session User Satisfaction in Recommendation Systems
Jul 31, 2025Existing web-scale recommendation systems commonly use supervised learning methods that prioritize immediate user feedback. Although reinforcement learning (RL) offers a solution to optimize longer-term goals, such as in-session engagement, applying it at web scale is challenging due to the extremely large action space and engineering complexity. In this paper, we introduce RecoMind, a simulator-based RL framework designed for the effective optimization of session-based goals at web-scale. RecoMind leverages existing recommendation models to establish a simulation environment and to bootstrap the RL policy to optimize immediate user interactions from the outset. This method integrates well with existing industry pipelines, simplifying the training and deployment of RL policies. Additionally, RecoMind introduces a custom exploration strategy to efficiently explore web-scale action spaces with hundreds of millions of items. We evaluated RecoMind through extensive offline simulations and online A/B testing on a video streaming platform. Both methods showed that the RL policy trained using RecoMind significantly outperforms traditional supervised learning recommendation approaches in in-session user satisfaction. In online A/B tests, the RL policy increased videos watched for more than 10 seconds by 15.81\% and improved session depth by 4.71\% for sessions with at least 10 interactions. As a result, RecoMind presents a systematic and scalable approach for embedding RL into web-scale recommendation systems, showing great promise for optimizing session-based user satisfaction.
Privacy Preserving Conversion Modeling in Data Clean Room
May 20, 2025



In the realm of online advertising, accurately predicting the conversion rate (CVR) is crucial for enhancing advertising efficiency and user satisfaction. This paper addresses the challenge of CVR prediction while adhering to user privacy preferences and advertiser requirements. Traditional methods face obstacles such as the reluctance of advertisers to share sensitive conversion data and the limitations of model training in secure environments like data clean rooms. We propose a novel model training framework that enables collaborative model training without sharing sample-level gradients with the advertising platform. Our approach introduces several innovative components: (1) utilizing batch-level aggregated gradients instead of sample-level gradients to minimize privacy risks; (2) applying adapter-based parameter-efficient fine-tuning and gradient compression to reduce communication costs; and (3) employing de-biasing techniques to train the model under label differential privacy, thereby maintaining accuracy despite privacy-enhanced label perturbations. Our experimental results, conducted on industrial datasets, demonstrate that our method achieves competitive ROCAUC performance while significantly decreasing communication overhead and complying with both advertiser privacy requirements and user privacy choices. This framework establishes a new standard for privacy-preserving, high-performance CVR prediction in the digital advertising landscape.
OmniSage: Large Scale, Multi-Entity Heterogeneous Graph Representation Learning
May 01, 2025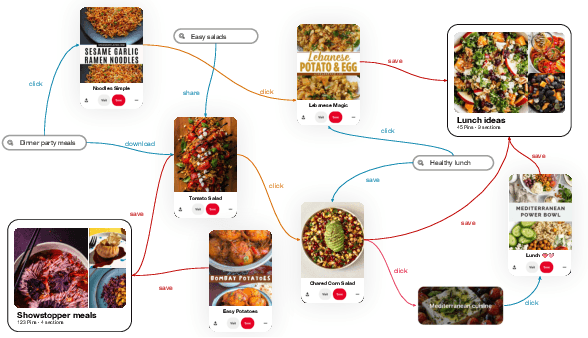
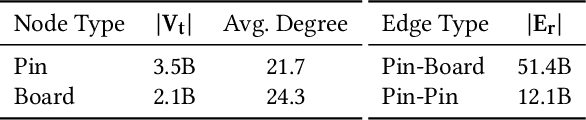
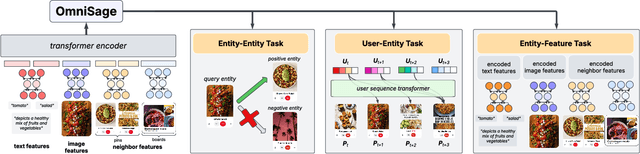

Representation learning, a task of learning latent vectors to represent entities, is a key task in improving search and recommender systems in web applications. Various representation learning methods have been developed, including graph-based approaches for relationships among entities, sequence-based methods for capturing the temporal evolution of user activities, and content-based models for leveraging text and visual content. However, the development of a unifying framework that integrates these diverse techniques to support multiple applications remains a significant challenge. This paper presents OmniSage, a large-scale representation framework that learns universal representations for a variety of applications at Pinterest. OmniSage integrates graph neural networks with content-based models and user sequence models by employing multiple contrastive learning tasks to effectively process graph data, user sequence data, and content signals. To support the training and inference of OmniSage, we developed an efficient infrastructure capable of supporting Pinterest graphs with billions of nodes. The universal representations generated by OmniSage have significantly enhanced user experiences on Pinterest, leading to an approximate 2.5% increase in sitewide repins (saves) across five applications. This paper highlights the impact of unifying representation learning methods, and we will open source the OmniSage code by the time of publication.
PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems
Apr 09, 2025Generative retrieval methods utilize generative sequential modeling techniques, such as transformers, to generate candidate items for recommender systems. These methods have demonstrated promising results in academic benchmarks, surpassing traditional retrieval models like two-tower architectures. However, current generative retrieval methods lack the scalability required for industrial recommender systems, and they are insufficiently flexible to satisfy the multiple metric requirements of modern systems. This paper introduces PinRec, a novel generative retrieval model developed for applications at Pinterest. PinRec utilizes outcome-conditioned generation, enabling modelers to specify how to balance various outcome metrics, such as the number of saves and clicks, to effectively align with business goals and user exploration. Additionally, PinRec incorporates multi-token generation to enhance output diversity while optimizing generation. Our experiments demonstrate that PinRec can successfully balance performance, diversity, and efficiency, delivering a significant positive impact to users using generative models. This paper marks a significant milestone in generative retrieval, as it presents, to our knowledge, the first rigorous study on implementing generative retrieval at the scale of Pinterest.
Hybrid Preference Optimization: Augmenting Direct Preference Optimization with Auxiliary Objectives
May 29, 2024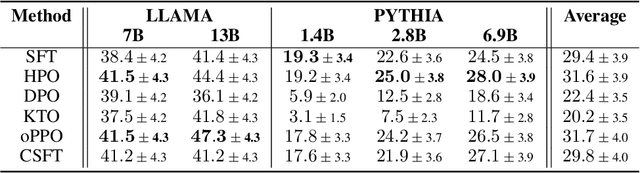
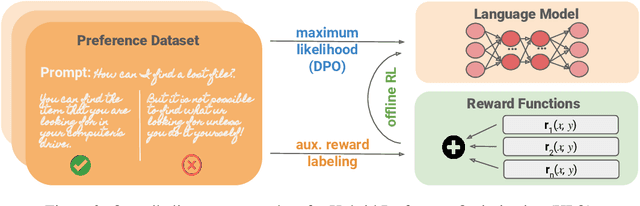

For aligning large language models (LLMs), prior work has leveraged reinforcement learning via human feedback (RLHF) or variations of direct preference optimization (DPO). While DPO offers a simpler framework based on maximum likelihood estimation, it compromises on the ability to tune language models to easily maximize non-differentiable and non-binary objectives according to the LLM designer's preferences (e.g., using simpler language or minimizing specific kinds of harmful content). These may neither align with user preferences nor even be able to be captured tractably by binary preference data. To leverage the simplicity and performance of DPO with the generalizability of RL, we propose a hybrid approach between DPO and RLHF. With a simple augmentation to the implicit reward decomposition of DPO, we allow for tuning LLMs to maximize a set of arbitrary auxiliary rewards using offline RL. The proposed method, Hybrid Preference Optimization (HPO), shows the ability to effectively generalize to both user preferences and auxiliary designer objectives, while preserving alignment performance across a range of challenging benchmarks and model sizes.
OmniSearchSage: Multi-Task Multi-Entity Embeddings for Pinterest Search
Apr 25, 2024



In this paper, we present OmniSearchSage, a versatile and scalable system for understanding search queries, pins, and products for Pinterest search. We jointly learn a unified query embedding coupled with pin and product embeddings, leading to an improvement of $>8\%$ relevance, $>7\%$ engagement, and $>5\%$ ads CTR in Pinterest's production search system. The main contributors to these gains are improved content understanding, better multi-task learning, and real-time serving. We enrich our entity representations using diverse text derived from image captions from a generative LLM, historical engagement, and user-curated boards. Our multitask learning setup produces a single search query embedding in the same space as pin and product embeddings and compatible with pre-existing pin and product embeddings. We show the value of each feature through ablation studies, and show the effectiveness of a unified model compared to standalone counterparts. Finally, we share how these embeddings have been deployed across the Pinterest search stack, from retrieval to ranking, scaling to serve $300k$ requests per second at low latency. Our implementation of this work is available at https://github.com/pinterest/atg-research/tree/main/omnisearchsage.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach
Sep 18, 2022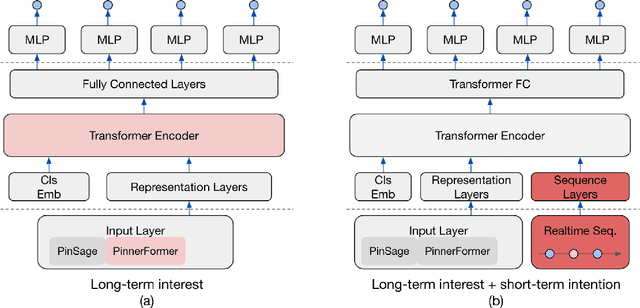
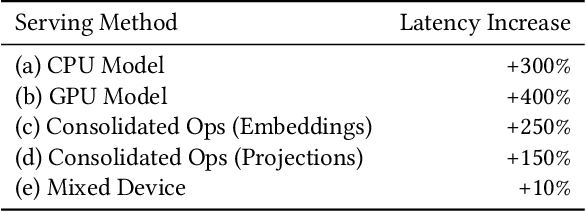
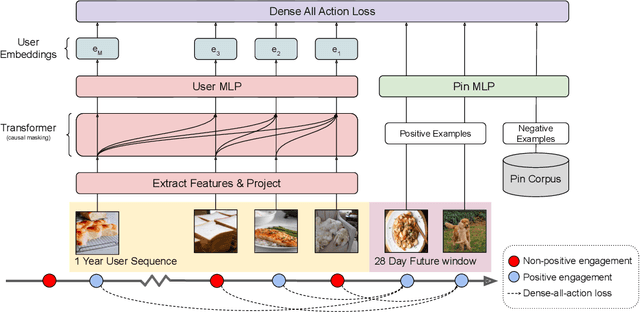

In this work, we present our journey to revolutionize the personalized recommendation engine through end-to-end learning from raw user actions. We encode user's long-term interest in Pinner- Former, a user embedding optimized for long-term future actions via a new dense all-action loss, and capture user's short-term intention by directly learning from the real-time action sequences. We conducted both offline and online experiments to validate the performance of the new model architecture, and also address the challenge of serving such a complex model using mixed CPU/GPU setup in production. The proposed system has been deployed in production at Pinterest and has delivered significant online gains across organic and Ads applications.
Evolution of a Web-Scale Near Duplicate Image Detection System
Sep 18, 2022
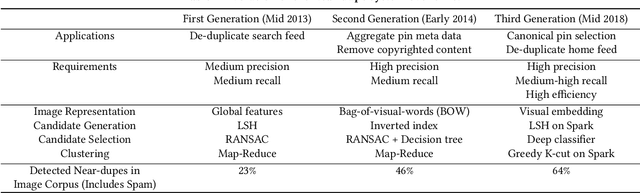


Detecting near duplicate images is fundamental to the content ecosystem of photo sharing web applications. However, such a task is challenging when involving a web-scale image corpus containing billions of images. In this paper, we present an efficient system for detecting near duplicate images across 8 billion images. Our system consists of three stages: candidate generation, candidate selection, and clustering. We also demonstrate that this system can be used to greatly improve the quality of recommendations and search results across a number of real-world applications. In addition, we include the evolution of the system over the course of six years, bringing out experiences and lessons on how new systems are designed to accommodate organic content growth as well as the latest technology. Finally, we are releasing a human-labeled dataset of ~53,000 pairs of images introduced in this paper.