 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution of a Web-Scale Near Duplicate Image Detection System
Paper and Code
Sep 18, 2022
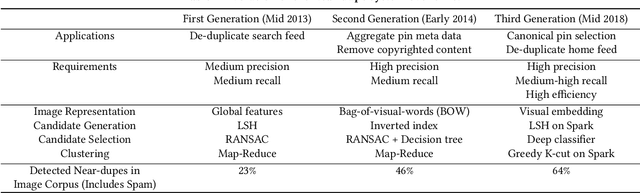


Detecting near duplicate images is fundamental to the content ecosystem of photo sharing web applications. However, such a task is challenging when involving a web-scale image corpus containing billions of images. In this paper, we present an efficient system for detecting near duplicate images across 8 billion images. Our system consists of three stages: candidate generation, candidate selection, and clustering. We also demonstrate that this system can be used to greatly improve the quality of recommendations and search results across a number of real-world applications. In addition, we include the evolution of the system over the course of six years, bringing out experiences and lessons on how new systems are designed to accommodate organic content growth as well as the latest technology. Finally, we are releasing a human-labeled dataset of ~53,000 pairs of images introduced in this paper.