 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Classification Competitive for Deep Metric Learning
Paper and Code
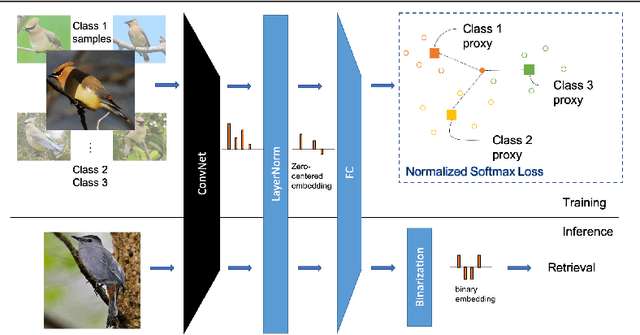
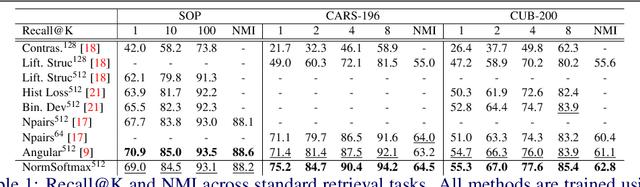
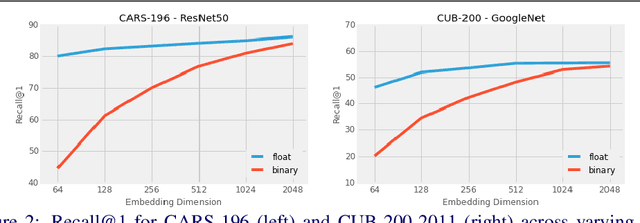

Deep metric learning aims to learn a function mapping image pixels to embedding feature vectors that model the similarity between images. The majority of current approaches are non-parametric, learning the metric space directly through the supervision of similar (pairs) or relatively similar (triplets) sets of images. A difficult challenge for training these approaches is mining informative samples of images as the metric space is learned with only the local context present within a single mini-batch. Alternative approaches use parametric metric learning to eliminate the need for sampling through supervision of images to proxies. Although this simplifies optimization, such proxy-based approaches have lagged behind in performance. In this work, we demonstrate that a standard classification network can be transformed into a variant of proxy-based metric learning that is competitive against non-parametric approaches across a wide variety of image retrieval tasks. We address key challenges in proxy-based metric learning such as performance under extreme classification and describe techniques to stabilize and learn higher dimensional embeddings. We evaluate our approach on the CAR-196, CUB-200-2011, Stanford Online Product, and In-Shop datasets for image retrieval and clustering. Finally, we show that our softmax classification approach can learn high-dimensional binary embeddings that achieve new state-of-the-art performance on all datasets evaluated with a memory footprint that is the same or smaller than competing approaches.