 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic Layouts: Structural Prior for Component Detection in User Interface Designs
Jun 14, 2021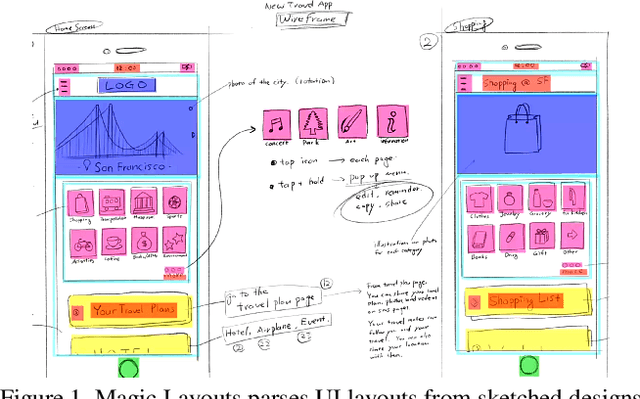



We present Magic Layouts; a method for parsing screenshots or hand-drawn sketches of user interface (UI) layouts. Our core contribution is to extend existing detectors to exploit a learned structural prior for UI designs, enabling robust detection of UI components; buttons, text boxes and similar. Specifically we learn a prior over mobile UI layouts, encoding common spatial co-occurrence relationships between different UI components. Conditioning region proposals using this prior leads to performance gains on UI layout parsing for both hand-drawn UIs and app screenshots, which we demonstrate within the context an interactive application for rapidly acquiring digital prototypes of user experience (UX) designs.
Semantic Granularity Metric Learning for Visual Search
Nov 14, 2019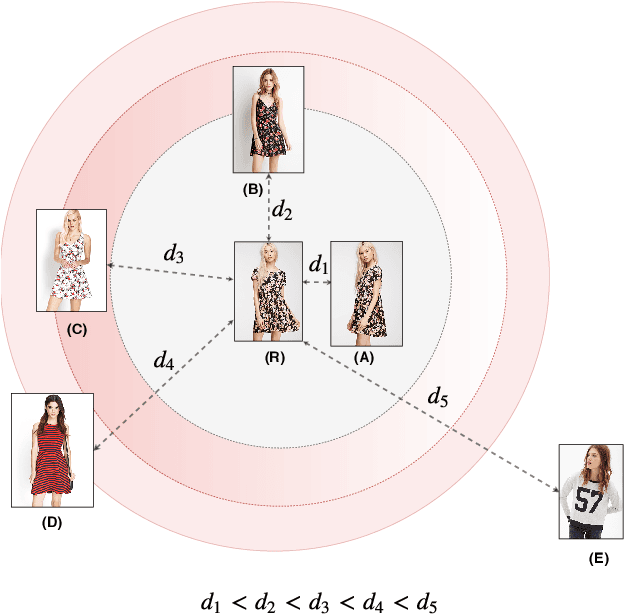

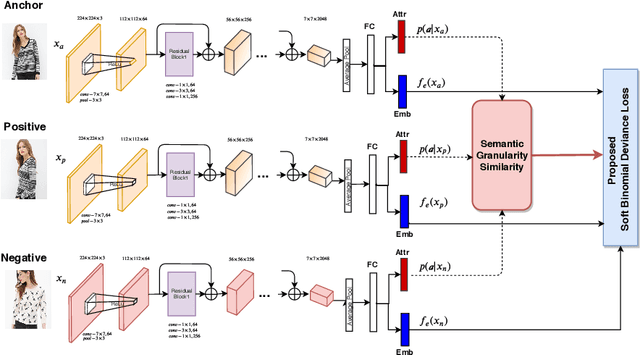
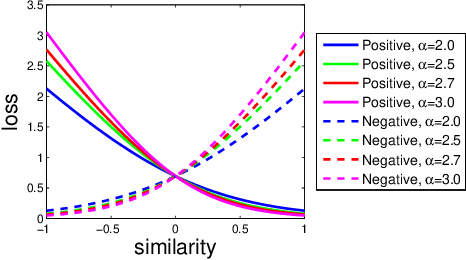
Deep metric learning applied to various applications has shown promising results in identification, retrieval and recognition. Existing methods often do not consider different granularity in visual similarity. However, in many domain applications, images exhibit similarity at multiple granularities with visual semantic concepts, e.g. fashion demonstrates similarity ranging from clothing of the exact same instance to similar looks/design or a common category. Therefore, training image triplets/pairs used for metric learning inherently possess different degree of information. However, the existing methods often treats them with equal importance during training. This hinders capturing the underlying granularities in feature similarity required for effective visual search. In view of this, we propose a new deep semantic granularity metric learning (SGML) that develops a novel idea of leveraging attribute semantic space to capture different granularity of similarity, and then integrate this information into deep metric learning. The proposed method simultaneously learns image attributes and embeddings using multitask CNNs. The two tasks are not only jointly optimized but are further linked by the semantic granularity similarity mappings to leverage the correlations between the tasks. To this end, we propose a new soft-binomial deviance loss that effectively integrates the degree of information in training samples, which helps to capture visual similarity at multiple granularities. Compared to recent ensemble-based methods, our framework is conceptually elegant, computationally simple and provides better performance. We perform extensive experiments on benchmark metric learning datasets and demonstrate that our method outperforms recent state-of-the-art methods, e.g., 1-4.5\% improvement in Recall@1 over the previous state-of-the-arts [1],[2] on DeepFashion In-Shop dataset.