 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising guarantees for optimized sampling schemes in compressed sensing
Apr 01, 2025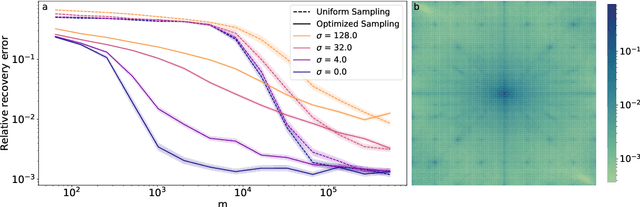
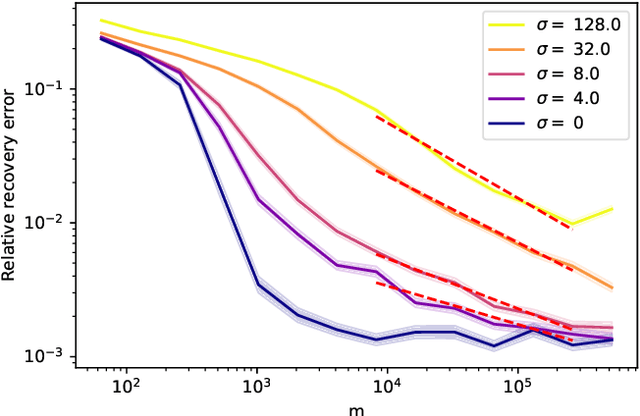

Compressed sensing with subsampled unitary matrices benefits from \emph{optimized} sampling schemes, which feature improved theoretical guarantees and empirical performance relative to uniform subsampling. We provide, in a first of its kind in compressed sensing, theoretical guarantees showing that the error caused by the measurement noise vanishes with an increasing number of measurements for optimized sampling schemes, assuming that the noise is Gaussian. We moreover provide similar guarantees for measurements sampled with-replacement with arbitrary probability weights. All our results hold on prior sets contained in a union of low-dimensional subspaces. Finally, we demonstrate that this denoising behavior appears in empirical experiments with a rate that closely matches our theoretical guarantees when the prior set is the range of a generative ReLU neural network and when it is the set of sparse vectors.
Model-adapted Fourier sampling for generative compressed sensing
Oct 08, 2023



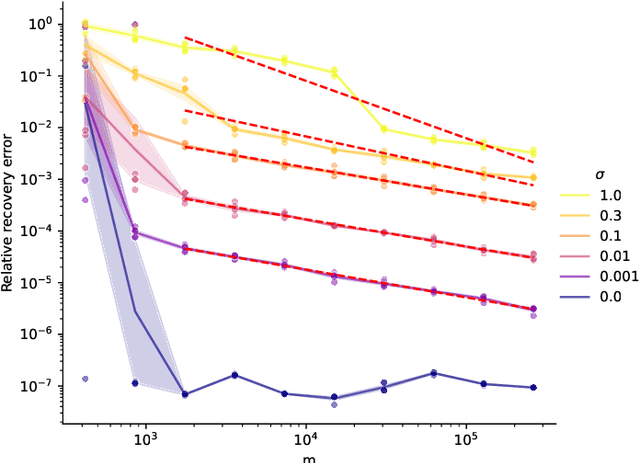
We study generative compressed sensing when the measurement matrix is randomly subsampled from a unitary matrix (with the DFT as an important special case). It was recently shown that $\textit{O}(kdn\| \boldsymbol{\alpha}\|_{\infty}^{2})$ uniformly random Fourier measurements are sufficient to recover signals in the range of a neural network $G:\mathbb{R}^k \to \mathbb{R}^n$ of depth $d$, where each component of the so-called local coherence vector $\boldsymbol{\alpha}$ quantifies the alignment of a corresponding Fourier vector with the range of $G$. We construct a model-adapted sampling strategy with an improved sample complexity of $\textit{O}(kd\| \boldsymbol{\alpha}\|_{2}^{2})$ measurements. This is enabled by: (1) new theoretical recovery guarantees that we develop for nonuniformly random sampling distributions and then (2) optimizing the sampling distribution to minimize the number of measurements needed for these guarantees. This development offers a sample complexity applicable to natural signal classes, which are often almost maximally coherent with low Fourier frequencies. Finally, we consider a surrogate sampling scheme, and validate its performance in recovery experiments using the CelebA dataset.
Artificial intelligence as a gateway to scientific discovery: Uncovering features in retinal fundus images
Jan 17, 2023



Purpose: Convolutional neural networks can be trained to detect various conditions or patient traits based on retinal fundus photographs, some of which, such as the patient sex, are invisible to the expert human eye. Here we propose a methodology for explainable classification of fundus images to uncover the mechanism(s) by which CNNs successfully predict the labels. We used patient sex as a case study to validate our proposed methodology. Approach: First, we used a set of 4746 fundus images, including training, validation and test partitions, to fine-tune a pre-trained CNN on the sex classification task. Next, we utilized deep learning explainability tools to hypothesize possible ways sex differences in the retina manifest. We measured numerous retinal properties relevant to our hypotheses through image segmentation to identify those significantly different between males and females. To tackle the multiple comparisons problem, we shortlisted the parameters by testing them on a set of 100 fundus images distinct from the images used for fine-tuning. Finally, we used an additional 400 images, not included in any previous set, to reveal significant sex differences in the retina. Results: We observed that the peripapillary area is darker in males compared to females ($p=.023, d=.243$). We also observed that males have richer retinal vasculature networks by showing a higher number of branches ($p=.016, d=.272$) and nodes ($p=.014, d=.299$) and a larger total length of branches ($p=.045, d=.206$) in the vessel graph. Also, vessels cover a greater area in the superior temporal quadrant of the retina in males compared to females ($p=0.048, d=.194$). Conclusions: Our methodology reveals retinal features in fundus photographs that allow CNNs to predict traits currently unknown, but meaningful to experts.
Multi-View Product Image Search Using Deep ConvNets Representations
May 01, 2017

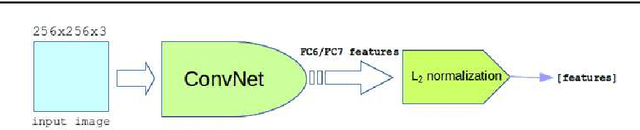
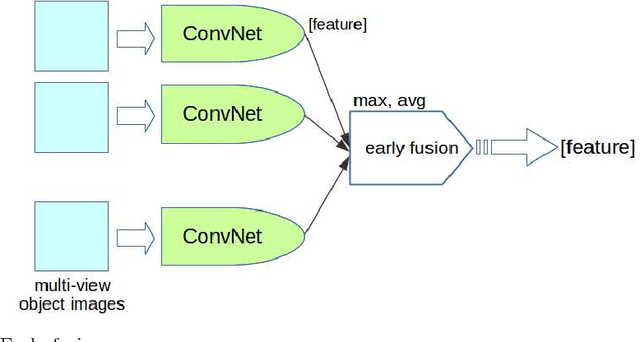
Multi-view product image queries can improve retrieval performance over single view queries significantly. In this paper, we investigated the performance of deep convolutional neural networks (ConvNets) on multi-view product image search. First, we trained a VGG-like network to learn deep ConvNets representations of product images. Then, we computed the deep ConvNets representations of database and query images and performed single view queries, and multi-view queries using several early and late fusion approaches. We performed extensive experiments on the publicly available Multi-View Object Image Dataset (MVOD 5K) with both clean background queries from the Internet and cluttered background queries from a mobile phone. We compared the performance of ConvNets to the classical bag-of-visual-words (BoWs). We concluded that (1) multi-view queries with deep ConvNets representations perform significantly better than single view queries, (2) ConvNets perform much better than BoWs and have room for further improvement, (3) pre-training of ConvNets on a different image dataset with background clutter is needed to obtain good performance on cluttered product image queries obtained with a mobile phone.
U-CATCH: Using Color ATtribute of image patCHes in binary descriptors
Mar 27, 2016
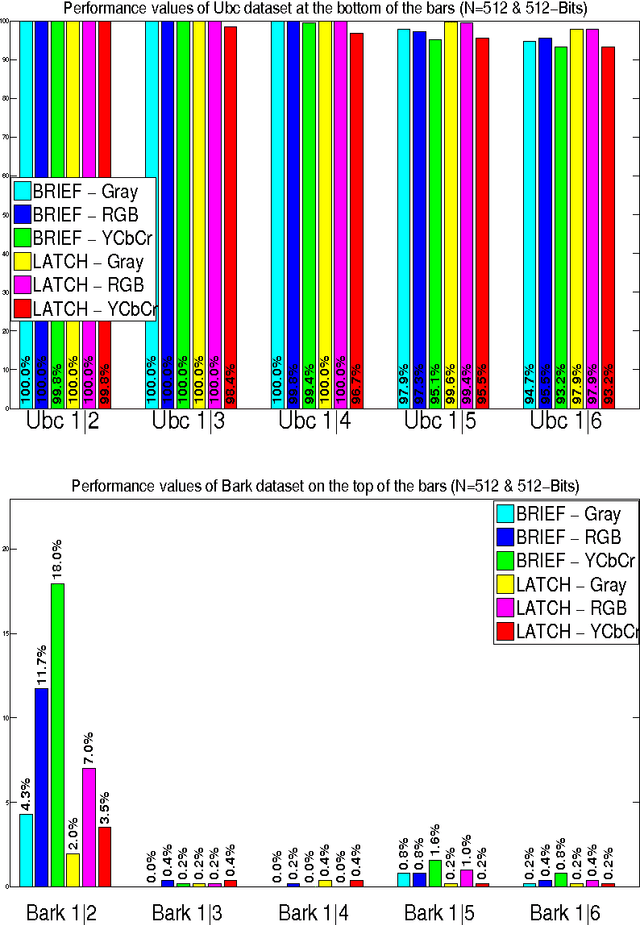


In this study, we propose a simple yet very effective method for extracting color information through binary feature description framework. Our method expands the dimension of binary comparisons into RGB and YCbCr spaces, showing more than 100% matching improve ment compared to non-color binary descriptors for a wide range of hard-to-match cases. The proposed method is general and can be applied to any binary descriptor to make it color sensitive. It is faster than classical binary descriptors for RGB sampling due to the abandonment of grayscale conversion and has almost identical complexity (insignificant compared to smoothing operation) for YCbCr sampling.
Classification of Occluded Objects using Fast Recurrent Processing
May 06, 2015
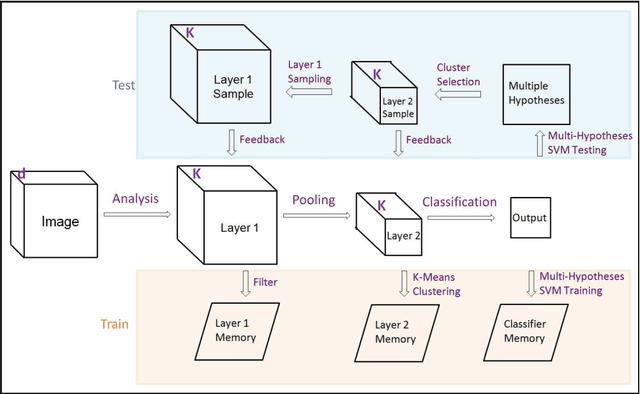

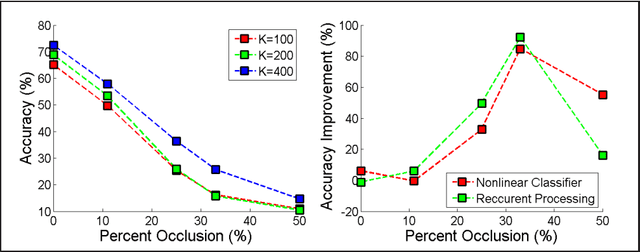
Recurrent neural networks are powerful tools for handling incomplete data problems in computer vision, thanks to their significant generative capabilities. However, the computational demand for these algorithms is too high to work in real time, without specialized hardware or software solutions. In this paper, we propose a framework for augmenting recurrent processing capabilities into a feedforward network without sacrificing much from computational efficiency. We assume a mixture model and generate samples of the last hidden layer according to the class decisions of the output layer, modify the hidden layer activity using the samples, and propagate to lower layers. For visual occlusion problem, the iterative procedure emulates feedforward-feedback loop, filling-in the missing hidden layer activity with meaningful representations. The proposed algorithm is tested on a widely used dataset, and shown to achieve 2$\times$ improvement in classification accuracy for occluded objects. When compared to Restricted Boltzmann Machines, our algorithm shows superior performance for occluded object classification.
Reservoir Computing using Cellular Automata
Oct 01, 2014

We introduce a novel framework of reservoir computing. Cellular automaton is used as the reservoir of dynamical systems. Input is randomly projected onto the initial conditions of automaton cells and nonlinear computation is performed on the input via application of a rule in the automaton for a period of time. The evolution of the automaton creates a space-time volume of the automaton state space, and it is used as the reservoir. The proposed framework is capable of long short-term memory and it requires orders of magnitude less computation compared to Echo State Networks. Also, for additive cellular automaton rules, reservoir features can be combined using Boolean operations, which provides a direct way for concept building and symbolic processing, and it is much more efficient compared to state-of-the-art approaches.