 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Space Mask Prediction for Efficient Vision Transformer Segmentation
May 18, 2026Query-based Vision Transformer segmentation models typically reconstruct dense spatial feature maps to predict masks, inheriting design patterns from convolutional architectures. We show that this explicit image-space reconstruction is not required. We introduce TokenMask, a token-space mask head that computes mask logits directly from query-token affinities and performs interpolation in logit space rather than feature space. This reformulation preserves the original linear scoring mechanism while simplifying the computational structure. Across diverse ViT backbones, datasets and segmentation tasks, TokenMask consistently improves efficiency over prior approaches by reducing computational and memory requirements while maintaining competitive accuracy, leading to tangible speedups on NVIDIA Jetson AGX Orin using TensorRT FP16 inference. Overall, TokenMask yields a simpler and more deployment-friendly design for embedded vision systems.
Multimodal embodiment-aware navigation transformer
Apr 21, 2026Goal-conditioned navigation models for ground robots trained using supervised learning show promising zero-shot transfer, but their collision-avoidance capability nevertheless degrades under distribution shift, i.e. environmental, robot or sensor configuration changes. We propose ViLiNT a multimodal, attention-based policy for goal navigation, trained on heterogeneous data from multiple platforms and environments, which improves robustness with two key features. First, we fuse RGB images, 3D LiDAR point clouds, a goal embedding and a robot's embodiment descriptor with a transformer architecture to capture complementary geometry and appearance cues. The transformer's output is used to condition a diffusion model that generates navigable trajectories. Second, using automatically generated offline labels, we train a path clearance prediction head for scoring and ranking trajectories produced by the diffusion model. The diffusion conditioning as well as the trajectory ranking head depend on a robot's embodiment token that allows our model to generate and select trajectories with respect to the robot's dimensions. Across three simulated environments, ViLiNT improves Success Rate on average by 166\% over equivalent state-of-the-art vision-only baseline (NoMaD). This increase in performance is confirmed through real-world deployments of a rover navigating in obstacle fields. These results highlight that combining multimodal fusion with our collision prediction mechanism leads to improved off-road navigation robustness.
LiPS: Lightweight Panoptic Segmentation for Resource-Constrained Robotics
Apr 01, 2026Panoptic segmentation is a key enabler for robotic perception, as it unifies semantic understanding with object-level reasoning. However, the increasing complexity of state-of-the-art models makes them unsuitable for deployment on resource-constrained platforms such as mobile robots. We propose a novel approach called LiPS that addresses the challenge of efficient-to-compute panoptic segmentation with a lightweight design that retains query-based decoding while introducing a streamlined feature extraction and fusion pathway. It aims at providing a strong panoptic segmentation performance while substantially lowering the computational demands. Evaluations on standard benchmarks demonstrate that LiPS attains accuracy comparable to much heavier baselines, while providing up to 4.5 higher throughput, measured in frames per second, and requiring nearly 6.8 times fewer computations. This efficiency makes LiPS a highly relevant bridge between modern panoptic models and real-world robotic applications.
Is Semantic SLAM Ready for Embedded Systems ? A Comparative Survey
May 18, 2025In embedded systems, robots must perceive and interpret their environment efficiently to operate reliably in real-world conditions. Visual Semantic SLAM (Simultaneous Localization and Mapping) enhances standard SLAM by incorporating semantic information into the map, enabling more informed decision-making. However, implementing such systems on resource-limited hardware involves trade-offs between accuracy, computing efficiency, and power usage. This paper provides a comparative review of recent Semantic Visual SLAM methods with a focus on their applicability to embedded platforms. We analyze three main types of architectures - Geometric SLAM, Neural Radiance Fields (NeRF), and 3D Gaussian Splatting - and evaluate their performance on constrained hardware, specifically the NVIDIA Jetson AGX Orin. We compare their accuracy, segmentation quality, memory usage, and energy consumption. Our results show that methods based on NeRF and Gaussian Splatting achieve high semantic detail but demand substantial computing resources, limiting their use on embedded devices. In contrast, Semantic Geometric SLAM offers a more practical balance between computational cost and accuracy. The review highlights a need for SLAM algorithms that are better adapted to embedded environments, and it discusses key directions for improving their efficiency through algorithm-hardware co-design.
Leg Exoskeleton Odometry using a Limited FOV Depth Sensor
Feb 26, 2025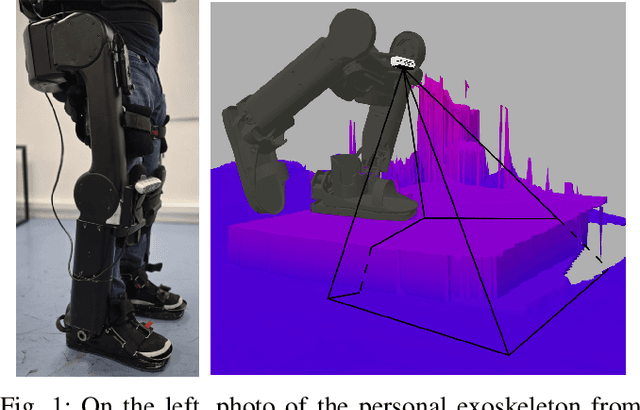
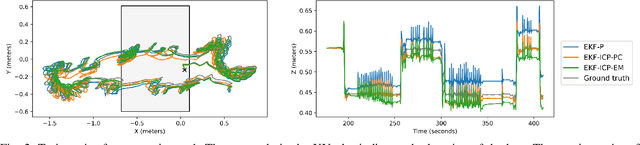
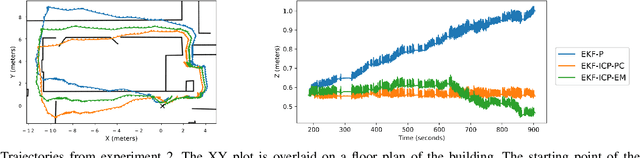

For leg exoskeletons to operate effectively in real-world environments, they must be able to perceive and understand the terrain around them. However, unlike other legged robots, exoskeletons face specific constraints on where depth sensors can be mounted due to the presence of a human user. These constraints lead to a limited Field Of View (FOV) and greater sensor motion, making odometry particularly challenging. To address this, we propose a novel odometry algorithm that integrates proprioceptive data from the exoskeleton with point clouds from a depth camera to produce accurate elevation maps despite these limitations. Our method builds on an extended Kalman filter (EKF) to fuse kinematic and inertial measurements, while incorporating a tailored iterative closest point (ICP) algorithm to register new point clouds with the elevation map. Experimental validation with a leg exoskeleton demonstrates that our approach reduces drift and enhances the quality of elevation maps compared to a purely proprioceptive baseline, while also outperforming a more traditional point cloud map-based variant.
3DLabelProp: Geometric-Driven Domain Generalization for LiDAR Semantic Segmentation in Autonomous Driving
Jan 24, 2025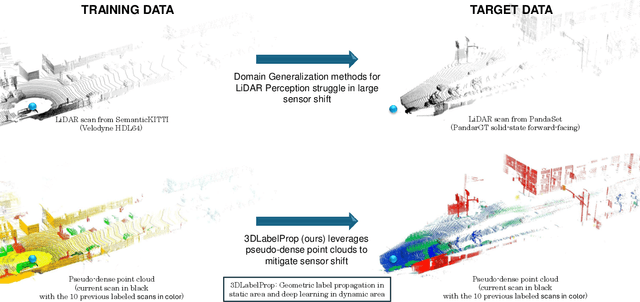

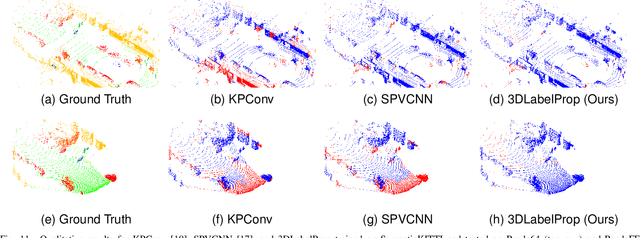

Domain generalization aims to find ways for deep learning models to maintain their performance despite significant domain shifts between training and inference datasets. This is particularly important for models that need to be robust or are costly to train. LiDAR perception in autonomous driving is impacted by both of these concerns, leading to the emergence of various approaches. This work addresses the challenge by proposing a geometry-based approach, leveraging the sequential structure of LiDAR sensors, which sets it apart from the learning-based methods commonly found in the literature. The proposed method, called 3DLabelProp, is applied on the task of LiDAR Semantic Segmentation (LSS). Through extensive experimentation on seven datasets, it is demonstrated to be a state-of-the-art approach, outperforming both naive and other domain generalization methods.
Open-Set 3D object detection in LiDAR data as an Out-of-Distribution problem
Oct 31, 20243D Object Detection from LiDAR data has achieved industry-ready performance in controlled environments through advanced deep learning methods. However, these neural network models are limited by a finite set of inlier object categories. Our work redefines the open-set 3D Object Detection problem in LiDAR data as an Out-Of-Distribution (OOD) problem to detect outlier objects. This approach brings additional information in comparison with traditional object detection. We establish a comparative benchmark and show that two-stage OOD methods, notably autolabelling, show promising results for 3D OOD Object Detection. Our contributions include setting a rigorous evaluation protocol by examining the evaluation of hyperparameters and evaluating strategies for generating additional data to train an OOD-aware 3D object detector. This comprehensive analysis is essential for developing robust 3D object detection systems that can perform reliably in diverse and unpredictable real-world scenarios.
COLA: COarse-LAbel multi-source LiDAR semantic segmentation for autonomous driving
Nov 06, 2023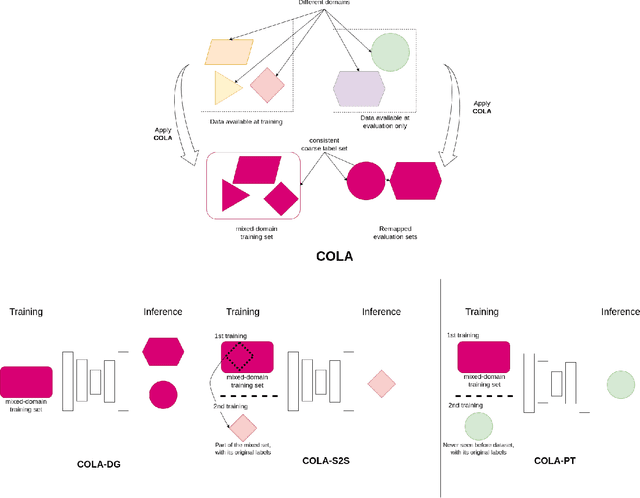
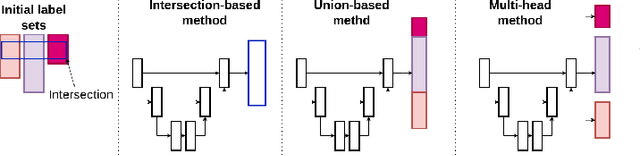
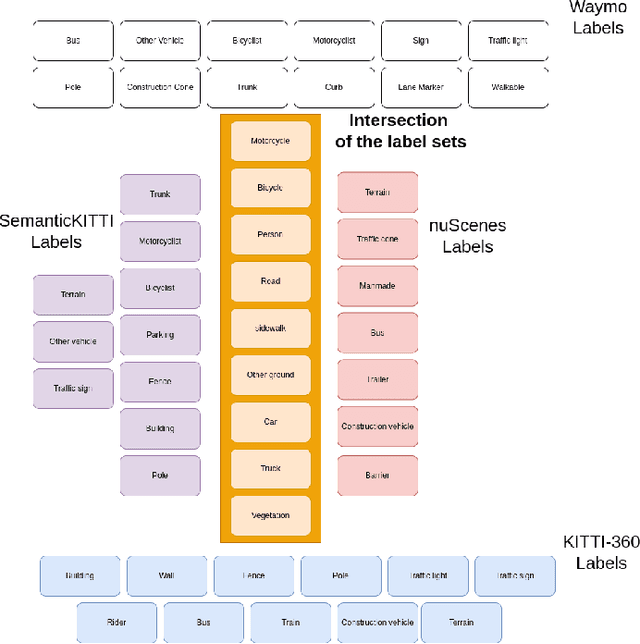
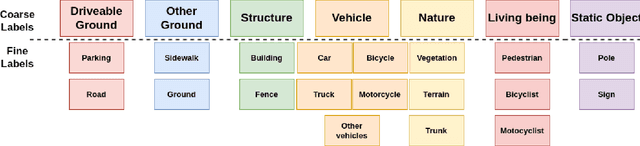
LiDAR semantic segmentation for autonomous driving has been a growing field of interest in the past few years. Datasets and methods have appeared and expanded very quickly, but methods have not been updated to exploit this new availability of data and continue to rely on the same classical datasets. Different ways of performing LIDAR semantic segmentation training and inference can be divided into several subfields, which include the following: domain generalization, the ability to segment data coming from unseen domains ; source-to-source segmentation, the ability to segment data coming from the training domain; and pre-training, the ability to create re-usable geometric primitives. In this work, we aim to improve results in all of these subfields with the novel approach of multi-source training. Multi-source training relies on the availability of various datasets at training time and uses them together rather than relying on only one dataset. To overcome the common obstacles found for multi-source training, we introduce the coarse labels and call the newly created multi-source dataset COLA. We propose three applications of this new dataset that display systematic improvement over single-source strategies: COLA-DG for domain generalization (up to +10%), COLA-S2S for source-to-source segmentation (up to +5.3%), and COLA-PT for pre-training (up to +12%).
MDT3D: Multi-Dataset Training for LiDAR 3D Object Detection Generalization
Aug 02, 2023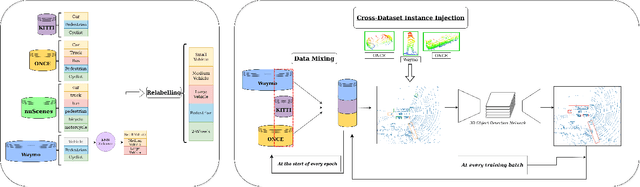
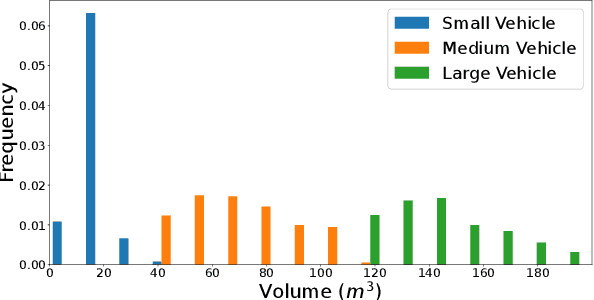


Supervised 3D Object Detection models have been displaying increasingly better performance in single-domain cases where the training data comes from the same environment and sensor as the testing data. However, in real-world scenarios data from the target domain may not be available for finetuning or for domain adaptation methods. Indeed, 3D object detection models trained on a source dataset with a specific point distribution have shown difficulties in generalizing to unseen datasets. Therefore, we decided to leverage the information available from several annotated source datasets with our Multi-Dataset Training for 3D Object Detection (MDT3D) method to increase the robustness of 3D object detection models when tested in a new environment with a different sensor configuration. To tackle the labelling gap between datasets, we used a new label mapping based on coarse labels. Furthermore, we show how we managed the mix of datasets during training and finally introduce a new cross-dataset augmentation method: cross-dataset object injection. We demonstrate that this training paradigm shows improvements for different types of 3D object detection models. The source code and additional results for this research project will be publicly available on GitHub for interested parties to access and utilize: https://github.com/LouisSF/MDT3D
Multi-IMU Proprioceptive State Estimator for Humanoid Robots
Jul 26, 2023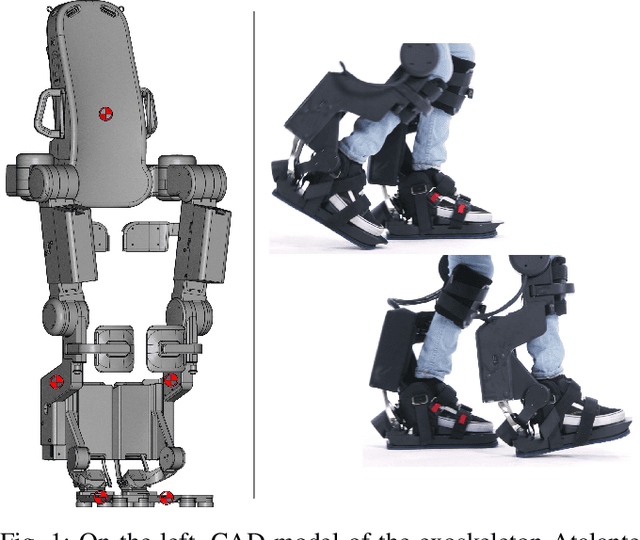
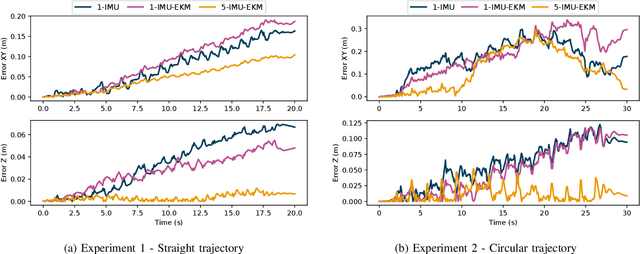
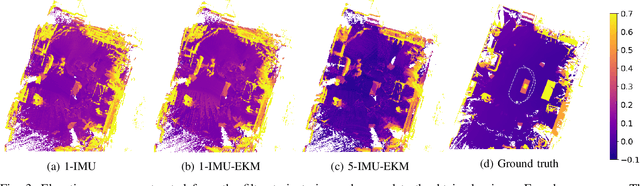

Algorithms for state estimation of humanoid robots usually assume that the feet remain flat and in a constant position while in contact with the ground. However, this hypothesis is easily violated while walking, especially for human-like gaits with heel-toe motion. This reduces the time during which the contact assumption can be used, or requires higher variances to account for errors. In this paper, we present a novel state estimator based on the extended Kalman filter that can properly handle any contact configuration. We consider multiple inertial measurement units (IMUs) distributed throughout the robot's structure, including on both feet, which are used to track multiple bodies of the robot. This multi-IMU instrumentation setup also has the advantage of allowing the deformations in the robot's structure to be estimated, improving the kinematic model used in the filter. The proposed approach is validated experimentally on the exoskeleton Atalante and is shown to present low drift, performing better than similar single-IMU filters. The obtained trajectory estimates are accurate enough to construct elevation maps that have little distortion with respect to the ground truth.