 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARP-NeXt: High-Speed and Accurate Range-Point Fusion Network for 3D LiDAR Semantic Segmentation
Oct 08, 2025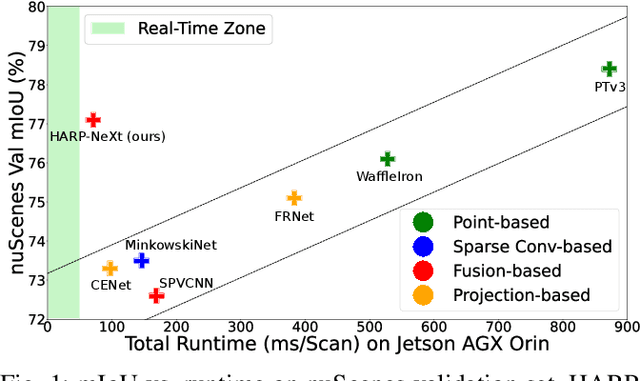
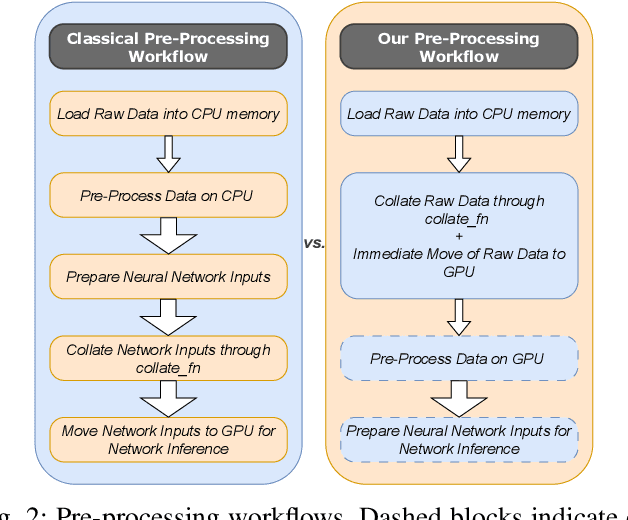
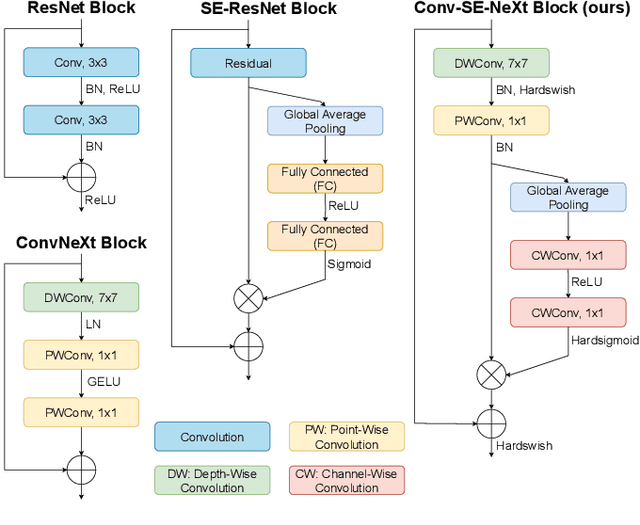
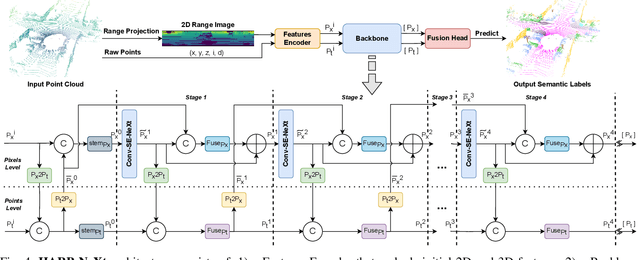
LiDAR semantic segmentation is crucial for autonomous vehicles and mobile robots, requiring high accuracy and real-time processing, especially on resource-constrained embedded systems. Previous state-of-the-art methods often face a trade-off between accuracy and speed. Point-based and sparse convolution-based methods are accurate but slow due to the complexity of neighbor searching and 3D convolutions. Projection-based methods are faster but lose critical geometric information during the 2D projection. Additionally, many recent methods rely on test-time augmentation (TTA) to improve performance, which further slows the inference. Moreover, the pre-processing phase across all methods increases execution time and is demanding on embedded platforms. Therefore, we introduce HARP-NeXt, a high-speed and accurate LiDAR semantic segmentation network. We first propose a novel pre-processing methodology that significantly reduces computational overhead. Then, we design the Conv-SE-NeXt feature extraction block to efficiently capture representations without deep layer stacking per network stage. We also employ a multi-scale range-point fusion backbone that leverages information at multiple abstraction levels to preserve essential geometric details, thereby enhancing accuracy. Experiments on the nuScenes and SemanticKITTI benchmarks show that HARP-NeXt achieves a superior speed-accuracy trade-off compared to all state-of-the-art methods, and, without relying on ensemble models or TTA, is comparable to the top-ranked PTv3, while running 24$\times$ faster. The code is available at https://github.com/SamirAbouHaidar/HARP-NeXt
RayGaussX: Accelerating Gaussian-Based Ray Marching for Real-Time and High-Quality Novel View Synthesis
Sep 09, 2025
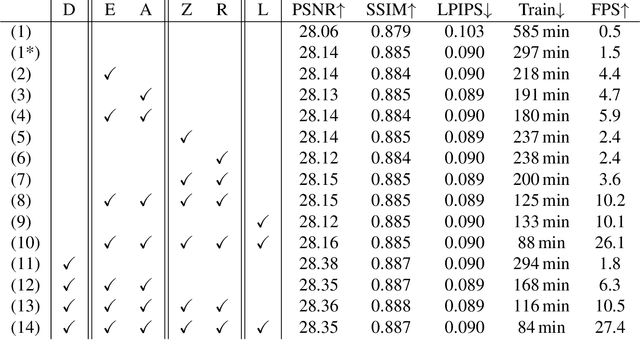


RayGauss has achieved state-of-the-art rendering quality for novel-view synthesis on synthetic and indoor scenes by representing radiance and density fields with irregularly distributed elliptical basis functions, rendered via volume ray casting using a Bounding Volume Hierarchy (BVH). However, its computational cost prevents real-time rendering on real-world scenes. Our approach, RayGaussX, builds on RayGauss by introducing key contributions that accelerate both training and inference. Specifically, we incorporate volumetric rendering acceleration strategies such as empty-space skipping and adaptive sampling, enhance ray coherence, and introduce scale regularization to reduce false-positive intersections. Additionally, we propose a new densification criterion that improves density distribution in distant regions, leading to enhanced graphical quality on larger scenes. As a result, RayGaussX achieves 5x to 12x faster training and 50x to 80x higher rendering speeds (FPS) on real-world datasets while improving visual quality by up to +0.56 dB in PSNR. Project page with videos and code: https://raygaussx.github.io/.
Leg Exoskeleton Odometry using a Limited FOV Depth Sensor
Feb 26, 2025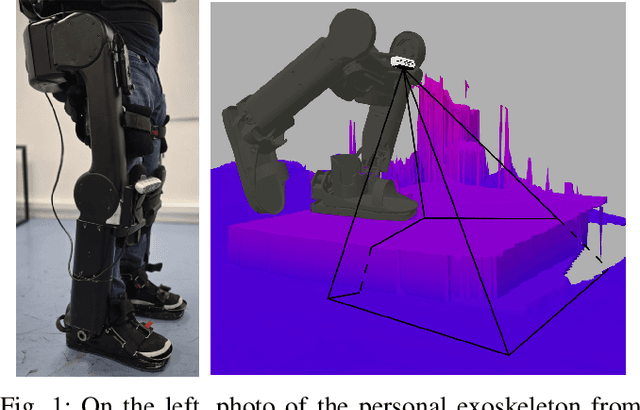
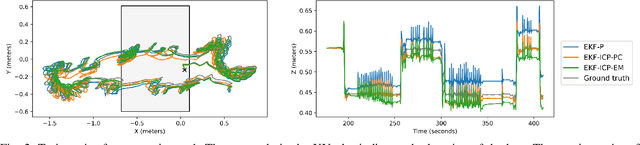
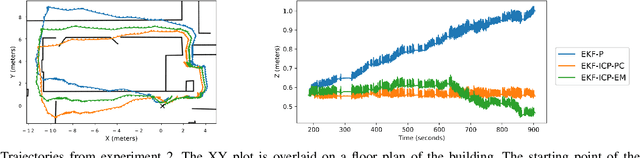

For leg exoskeletons to operate effectively in real-world environments, they must be able to perceive and understand the terrain around them. However, unlike other legged robots, exoskeletons face specific constraints on where depth sensors can be mounted due to the presence of a human user. These constraints lead to a limited Field Of View (FOV) and greater sensor motion, making odometry particularly challenging. To address this, we propose a novel odometry algorithm that integrates proprioceptive data from the exoskeleton with point clouds from a depth camera to produce accurate elevation maps despite these limitations. Our method builds on an extended Kalman filter (EKF) to fuse kinematic and inertial measurements, while incorporating a tailored iterative closest point (ICP) algorithm to register new point clouds with the elevation map. Experimental validation with a leg exoskeleton demonstrates that our approach reduces drift and enhances the quality of elevation maps compared to a purely proprioceptive baseline, while also outperforming a more traditional point cloud map-based variant.
3DLabelProp: Geometric-Driven Domain Generalization for LiDAR Semantic Segmentation in Autonomous Driving
Jan 24, 2025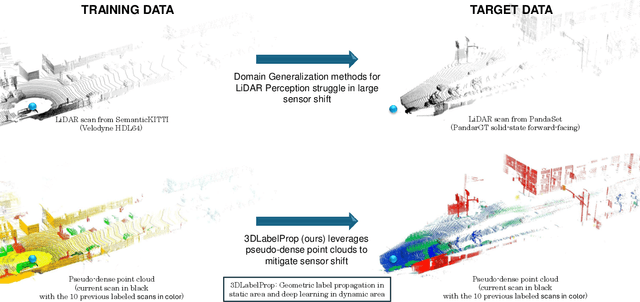


Domain generalization aims to find ways for deep learning models to maintain their performance despite significant domain shifts between training and inference datasets. This is particularly important for models that need to be robust or are costly to train. LiDAR perception in autonomous driving is impacted by both of these concerns, leading to the emergence of various approaches. This work addresses the challenge by proposing a geometry-based approach, leveraging the sequential structure of LiDAR sensors, which sets it apart from the learning-based methods commonly found in the literature. The proposed method, called 3DLabelProp, is applied on the task of LiDAR Semantic Segmentation (LSS). Through extensive experimentation on seven datasets, it is demonstrated to be a state-of-the-art approach, outperforming both naive and other domain generalization methods.
Open-Set 3D object detection in LiDAR data as an Out-of-Distribution problem
Oct 31, 20243D Object Detection from LiDAR data has achieved industry-ready performance in controlled environments through advanced deep learning methods. However, these neural network models are limited by a finite set of inlier object categories. Our work redefines the open-set 3D Object Detection problem in LiDAR data as an Out-Of-Distribution (OOD) problem to detect outlier objects. This approach brings additional information in comparison with traditional object detection. We establish a comparative benchmark and show that two-stage OOD methods, notably autolabelling, show promising results for 3D OOD Object Detection. Our contributions include setting a rigorous evaluation protocol by examining the evaluation of hyperparameters and evaluating strategies for generating additional data to train an OOD-aware 3D object detector. This comprehensive analysis is essential for developing robust 3D object detection systems that can perform reliably in diverse and unpredictable real-world scenarios.
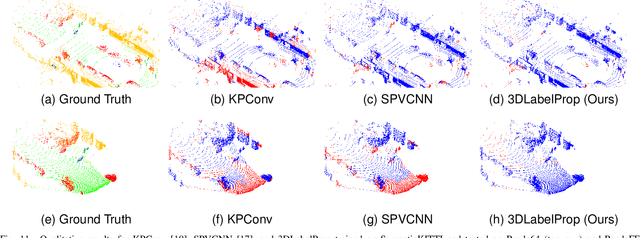
Are We Ready for Real-Time LiDAR Semantic Segmentation in Autonomous Driving?
Oct 10, 2024
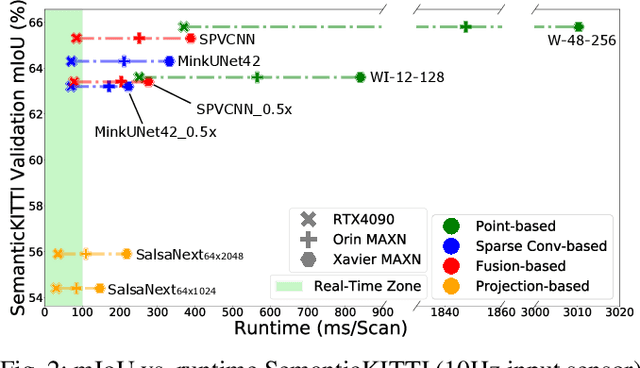
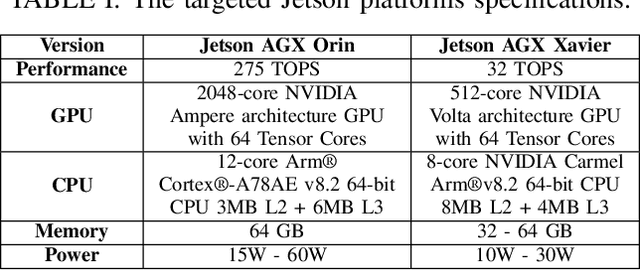
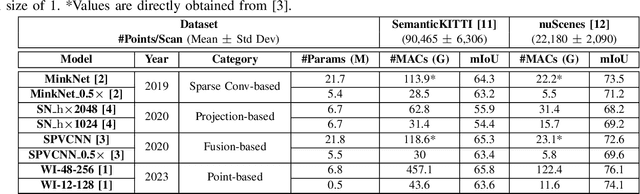
Within a perception framework for autonomous mobile and robotic systems, semantic analysis of 3D point clouds typically generated by LiDARs is key to numerous applications, such as object detection and recognition, and scene reconstruction. Scene semantic segmentation can be achieved by directly integrating 3D spatial data with specialized deep neural networks. Although this type of data provides rich geometric information regarding the surrounding environment, it also presents numerous challenges: its unstructured and sparse nature, its unpredictable size, and its demanding computational requirements. These characteristics hinder the real-time semantic analysis, particularly on resource-constrained hardware architectures that constitute the main computational components of numerous robotic applications. Therefore, in this paper, we investigate various 3D semantic segmentation methodologies and analyze their performance and capabilities for resource-constrained inference on embedded NVIDIA Jetson platforms. We evaluate them for a fair comparison through a standardized training protocol and data augmentations, providing benchmark results on the Jetson AGX Orin and AGX Xavier series for two large-scale outdoor datasets: SemanticKITTI and nuScenes.
RayGauss: Volumetric Gaussian-Based Ray Casting for Photorealistic Novel View Synthesis
Aug 06, 2024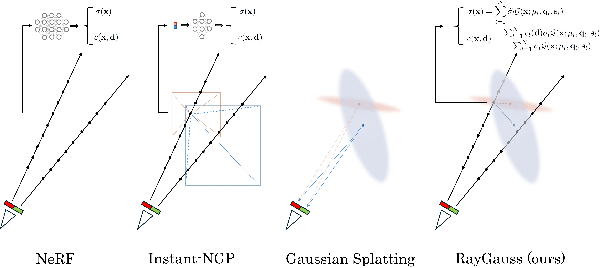
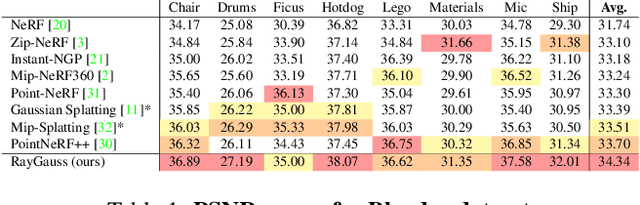


Differentiable volumetric rendering-based methods made significant progress in novel view synthesis. On one hand, innovative methods have replaced the Neural Radiance Fields (NeRF) network with locally parameterized structures, enabling high-quality renderings in a reasonable time. On the other hand, approaches have used differentiable splatting instead of NeRF's ray casting to optimize radiance fields rapidly using Gaussian kernels, allowing for fine adaptation to the scene. However, differentiable ray casting of irregularly spaced kernels has been scarcely explored, while splatting, despite enabling fast rendering times, is susceptible to clearly visible artifacts. Our work closes this gap by providing a physically consistent formulation of the emitted radiance c and density {\sigma}, decomposed with Gaussian functions associated with Spherical Gaussians/Harmonics for all-frequency colorimetric representation. We also introduce a method enabling differentiable ray casting of irregularly distributed Gaussians using an algorithm that integrates radiance fields slab by slab and leverages a BVH structure. This allows our approach to finely adapt to the scene while avoiding splatting artifacts. As a result, we achieve superior rendering quality compared to the state-of-the-art while maintaining reasonable training times and achieving inference speeds of 25 FPS on the Blender dataset. Project page with videos and code: https://raygauss.github.io/
COLA: COarse-LAbel multi-source LiDAR semantic segmentation for autonomous driving
Nov 06, 2023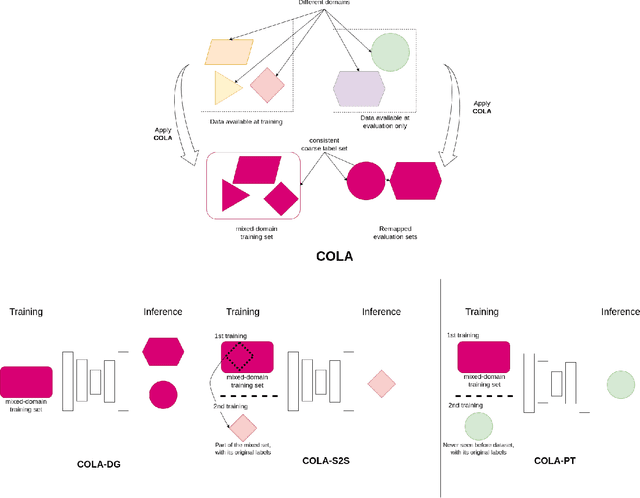
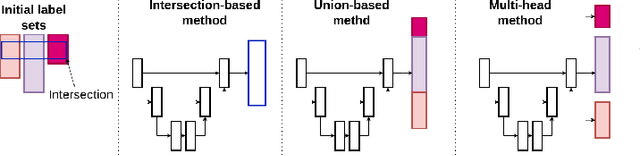
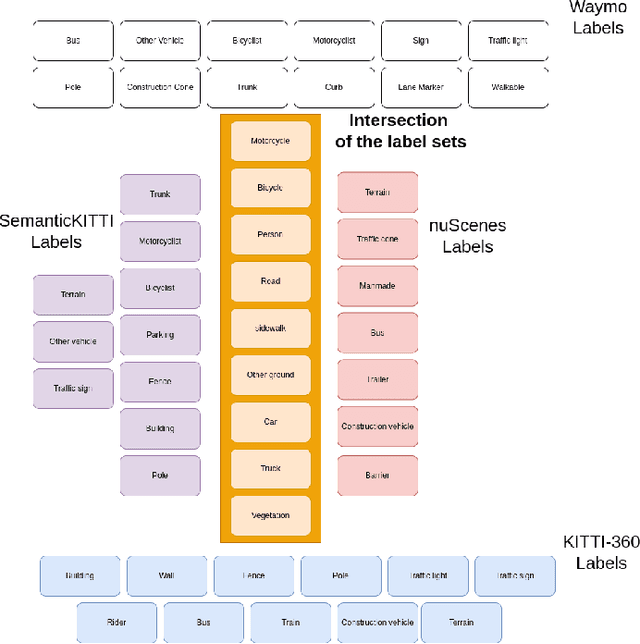
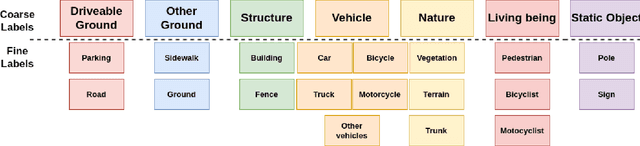
LiDAR semantic segmentation for autonomous driving has been a growing field of interest in the past few years. Datasets and methods have appeared and expanded very quickly, but methods have not been updated to exploit this new availability of data and continue to rely on the same classical datasets. Different ways of performing LIDAR semantic segmentation training and inference can be divided into several subfields, which include the following: domain generalization, the ability to segment data coming from unseen domains ; source-to-source segmentation, the ability to segment data coming from the training domain; and pre-training, the ability to create re-usable geometric primitives. In this work, we aim to improve results in all of these subfields with the novel approach of multi-source training. Multi-source training relies on the availability of various datasets at training time and uses them together rather than relying on only one dataset. To overcome the common obstacles found for multi-source training, we introduce the coarse labels and call the newly created multi-source dataset COLA. We propose three applications of this new dataset that display systematic improvement over single-source strategies: COLA-DG for domain generalization (up to +10%), COLA-S2S for source-to-source segmentation (up to +5.3%), and COLA-PT for pre-training (up to +12%).
ParisLuco3D: A high-quality target dataset for domain generalization of LiDAR perception
Oct 25, 2023
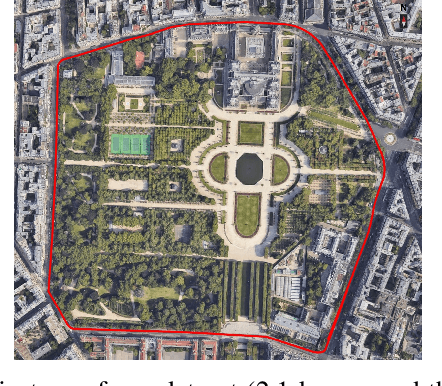

LiDAR is a sensor system that supports autonomous driving by gathering precise geometric information about the scene. Exploiting this information for perception is interesting as the amount of available data increases. As the quantitative performance of various perception tasks has improved, the focus has shifted from source-to-source perception to domain adaptation and domain generalization for perception. These new goals require access to a large variety of domains for evaluation. Unfortunately, the various annotation strategies of data providers complicate the computation of cross-domain performance based on the available data This paper provides a novel dataset, specifically designed for cross-domain evaluation to make it easier to evaluate the performance of various source datasets. Alongside the dataset, a flexible online benchmark is provided to ensure a fair comparison across methods.
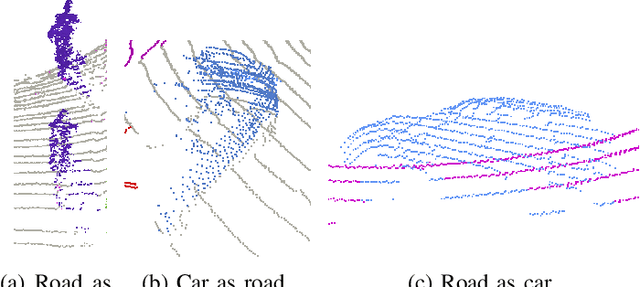
MDT3D: Multi-Dataset Training for LiDAR 3D Object Detection Generalization
Aug 02, 2023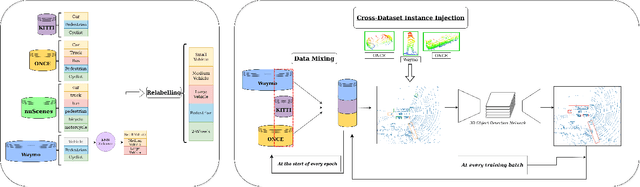
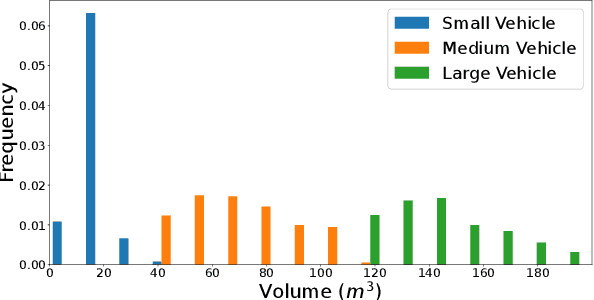


Supervised 3D Object Detection models have been displaying increasingly better performance in single-domain cases where the training data comes from the same environment and sensor as the testing data. However, in real-world scenarios data from the target domain may not be available for finetuning or for domain adaptation methods. Indeed, 3D object detection models trained on a source dataset with a specific point distribution have shown difficulties in generalizing to unseen datasets. Therefore, we decided to leverage the information available from several annotated source datasets with our Multi-Dataset Training for 3D Object Detection (MDT3D) method to increase the robustness of 3D object detection models when tested in a new environment with a different sensor configuration. To tackle the labelling gap between datasets, we used a new label mapping based on coarse labels. Furthermore, we show how we managed the mix of datasets during training and finally introduce a new cross-dataset augmentation method: cross-dataset object injection. We demonstrate that this training paradigm shows improvements for different types of 3D object detection models. The source code and additional results for this research project will be publicly available on GitHub for interested parties to access and utilize: https://github.com/LouisSF/MDT3D