 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Ready for Real-Time LiDAR Semantic Segmentation in Autonomous Driving?
Paper and Code
Oct 10, 2024
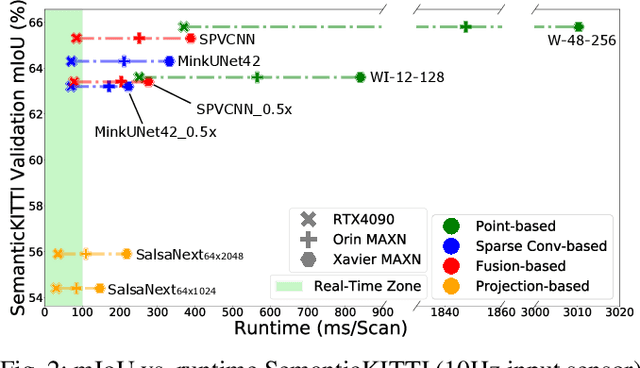
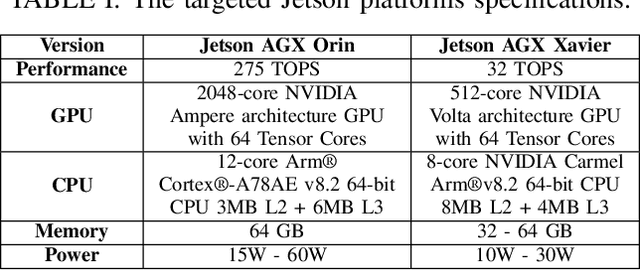
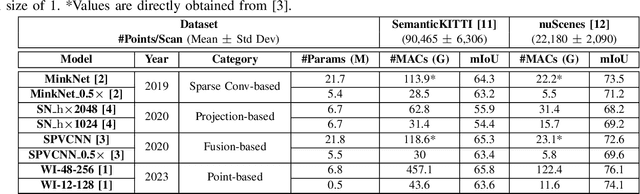
Within a perception framework for autonomous mobile and robotic systems, semantic analysis of 3D point clouds typically generated by LiDARs is key to numerous applications, such as object detection and recognition, and scene reconstruction. Scene semantic segmentation can be achieved by directly integrating 3D spatial data with specialized deep neural networks. Although this type of data provides rich geometric information regarding the surrounding environment, it also presents numerous challenges: its unstructured and sparse nature, its unpredictable size, and its demanding computational requirements. These characteristics hinder the real-time semantic analysis, particularly on resource-constrained hardware architectures that constitute the main computational components of numerous robotic applications. Therefore, in this paper, we investigate various 3D semantic segmentation methodologies and analyze their performance and capabilities for resource-constrained inference on embedded NVIDIA Jetson platforms. We evaluate them for a fair comparison through a standardized training protocol and data augmentations, providing benchmark results on the Jetson AGX Orin and AGX Xavier series for two large-scale outdoor datasets: SemanticKITTI and nuScenes.