 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARP-NeXt: High-Speed and Accurate Range-Point Fusion Network for 3D LiDAR Semantic Segmentation
Oct 08, 2025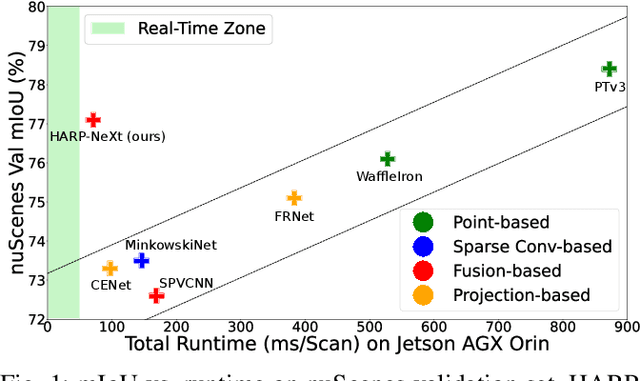
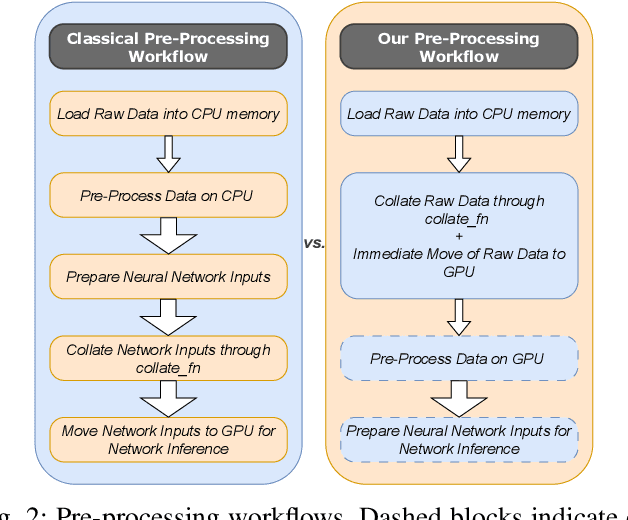
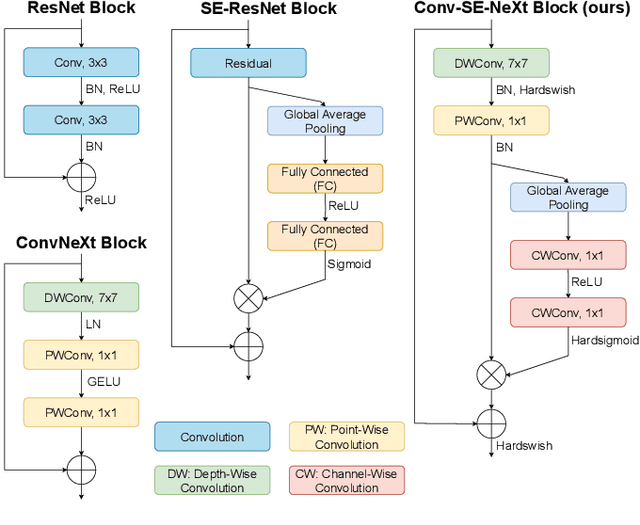
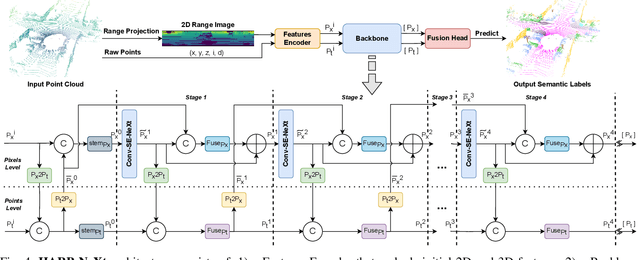
LiDAR semantic segmentation is crucial for autonomous vehicles and mobile robots, requiring high accuracy and real-time processing, especially on resource-constrained embedded systems. Previous state-of-the-art methods often face a trade-off between accuracy and speed. Point-based and sparse convolution-based methods are accurate but slow due to the complexity of neighbor searching and 3D convolutions. Projection-based methods are faster but lose critical geometric information during the 2D projection. Additionally, many recent methods rely on test-time augmentation (TTA) to improve performance, which further slows the inference. Moreover, the pre-processing phase across all methods increases execution time and is demanding on embedded platforms. Therefore, we introduce HARP-NeXt, a high-speed and accurate LiDAR semantic segmentation network. We first propose a novel pre-processing methodology that significantly reduces computational overhead. Then, we design the Conv-SE-NeXt feature extraction block to efficiently capture representations without deep layer stacking per network stage. We also employ a multi-scale range-point fusion backbone that leverages information at multiple abstraction levels to preserve essential geometric details, thereby enhancing accuracy. Experiments on the nuScenes and SemanticKITTI benchmarks show that HARP-NeXt achieves a superior speed-accuracy trade-off compared to all state-of-the-art methods, and, without relying on ensemble models or TTA, is comparable to the top-ranked PTv3, while running 24$\times$ faster. The code is available at https://github.com/SamirAbouHaidar/HARP-NeXt
Are We Ready for Real-Time LiDAR Semantic Segmentation in Autonomous Driving?
Oct 10, 2024
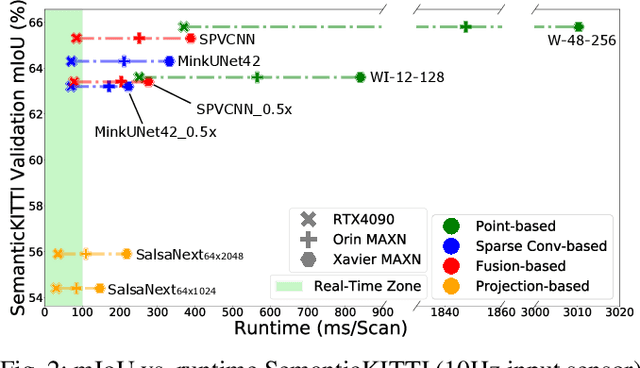
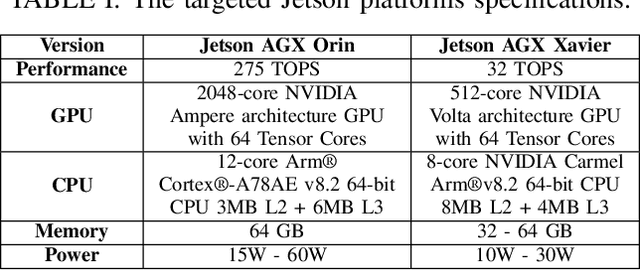
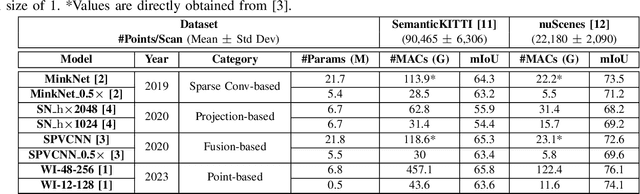
Within a perception framework for autonomous mobile and robotic systems, semantic analysis of 3D point clouds typically generated by LiDARs is key to numerous applications, such as object detection and recognition, and scene reconstruction. Scene semantic segmentation can be achieved by directly integrating 3D spatial data with specialized deep neural networks. Although this type of data provides rich geometric information regarding the surrounding environment, it also presents numerous challenges: its unstructured and sparse nature, its unpredictable size, and its demanding computational requirements. These characteristics hinder the real-time semantic analysis, particularly on resource-constrained hardware architectures that constitute the main computational components of numerous robotic applications. Therefore, in this paper, we investigate various 3D semantic segmentation methodologies and analyze their performance and capabilities for resource-constrained inference on embedded NVIDIA Jetson platforms. We evaluate them for a fair comparison through a standardized training protocol and data augmentations, providing benchmark results on the Jetson AGX Orin and AGX Xavier series for two large-scale outdoor datasets: SemanticKITTI and nuScenes.
MagHT: a Magnetic Hough Transform for Fast Indoor Place Recognition
Dec 08, 2023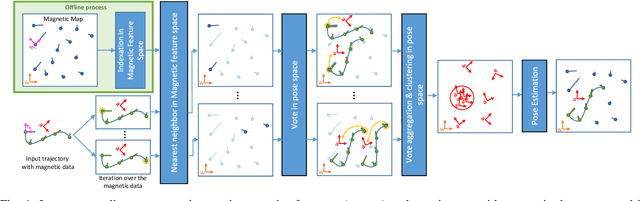
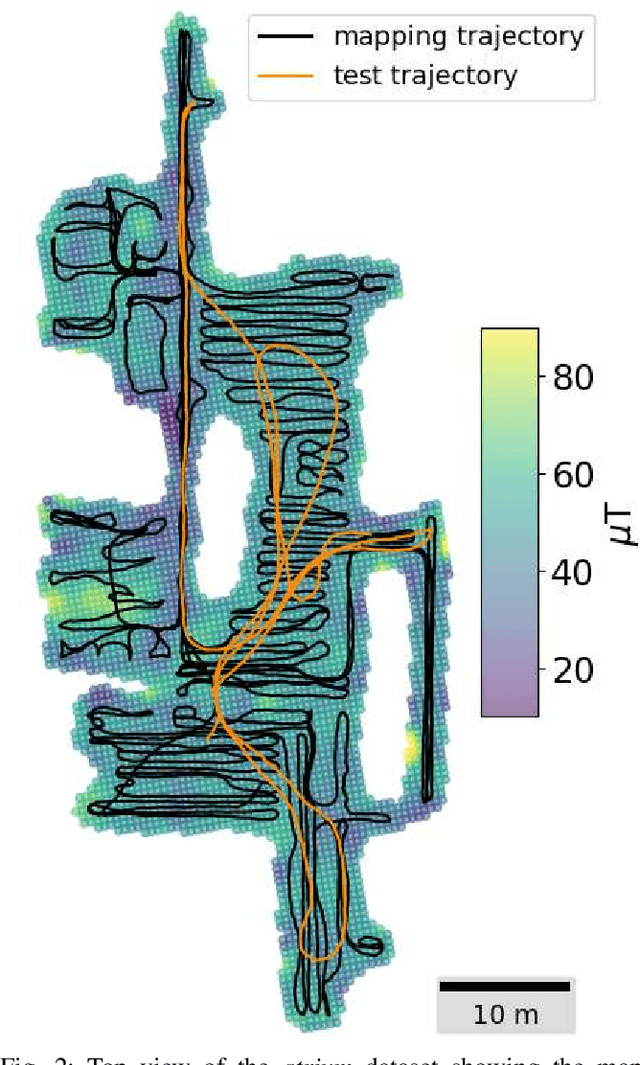
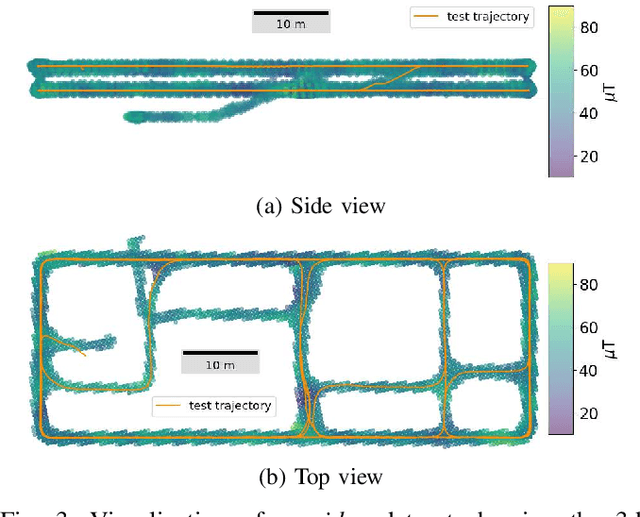
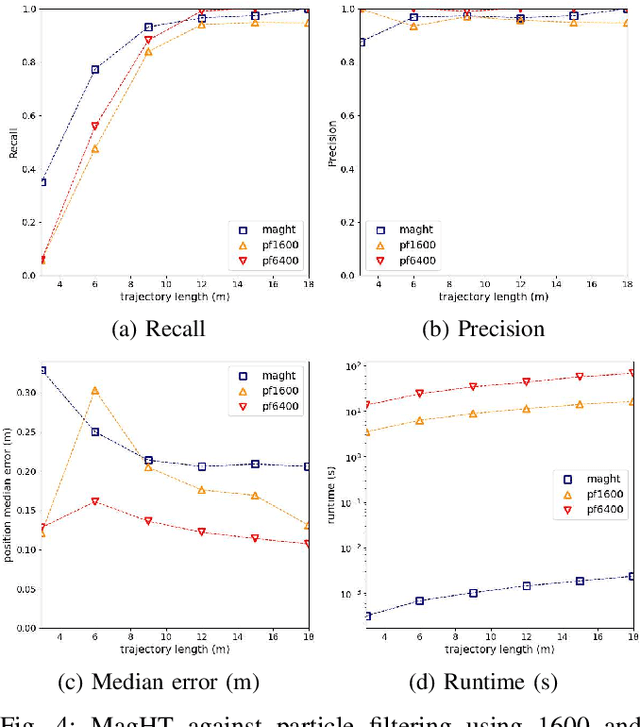
This article proposes a novel indoor magnetic field-based place recognition algorithm that is accurate and fast to compute. For that, we modified the generalized ''Hough Transform'' to process magnetic data (MagHT). It takes as input a sequence of magnetic measures whose relative positions are recovered by an odometry system and recognizes the places in the magnetic map where they were acquired. It also returns the global transformation from the coordinate frame of the input magnetic data to the magnetic map reference frame. Experimental results on several real datasets in large indoor environments demonstrate that the obtained localization error, recall, and precision are similar to or are better than state-of-the-art methods while improving the runtime by several orders of magnitude. Moreover, unlike magnetic sequence matching-based solutions such as DTW, our approach is independent of the path taken during the magnetic map creation.
Deep Sensor Fusion for Real-Time Odometry Estimation
Jul 31, 2019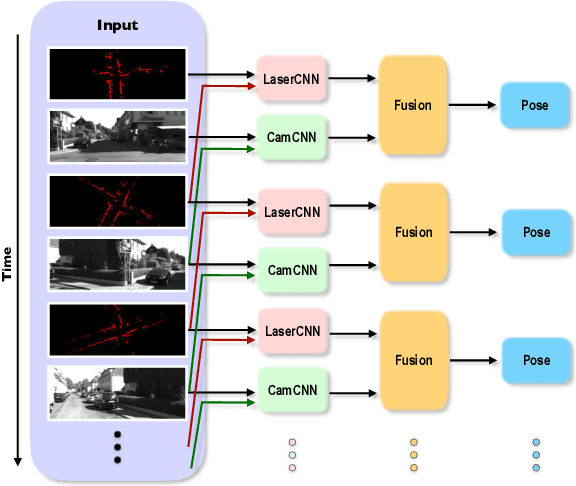
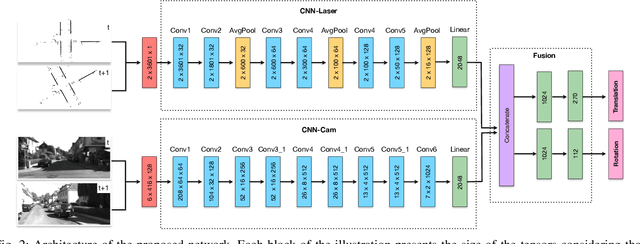
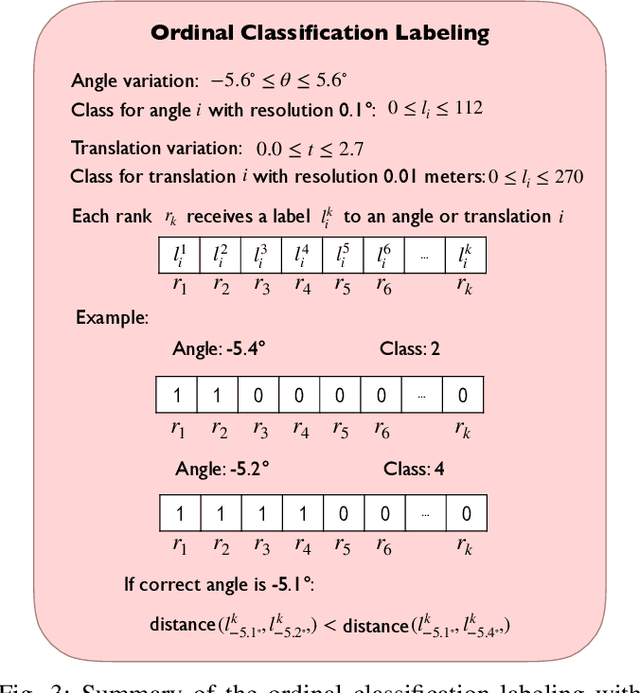
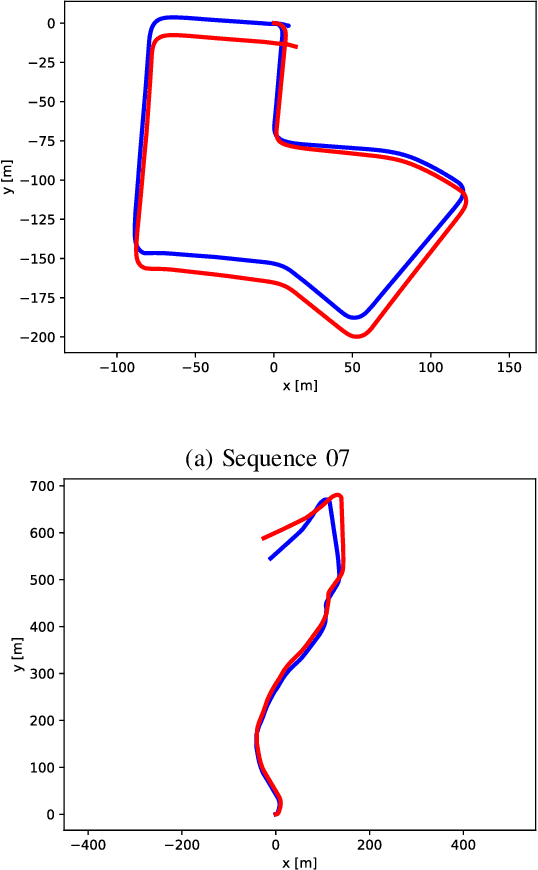
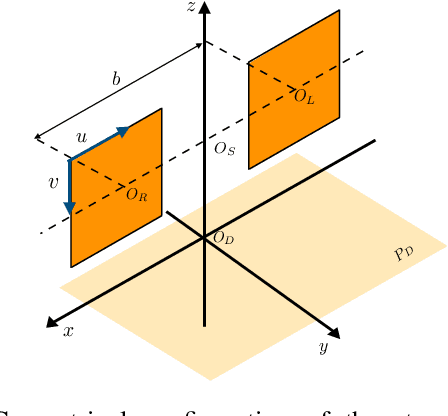
Cameras and 2D laser scanners, in combination, are able to provide low-cost, light-weight and accurate solutions, which make their fusion well-suited for many robot navigation tasks. However, correct data fusion depends on precise calibration of the rigid body transform between the sensors. In this paper we present the first framework that makes use of Convolutional Neural Networks (CNNs) for odometry estimation fusing 2D laser scanners and mono-cameras. The use of CNNs provides the tools to not only extract the features from the two sensors, but also to fuse and match them without needing a calibration between the sensors. We transform the odometry estimation into an ordinal classification problem in order to find accurate rotation and translation values between consecutive frames. Results on a real road dataset show that the fusion network runs in real-time and is able to improve the odometry estimation of a single sensor alone by learning how to fuse two different types of data information.
Fusing Laser Scanner and Stereo Camera in Evidential Grid Maps
Feb 22, 2019
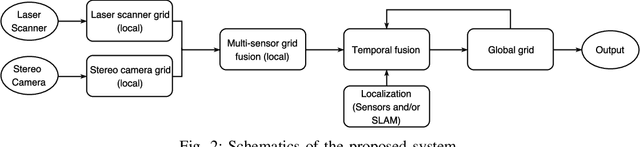
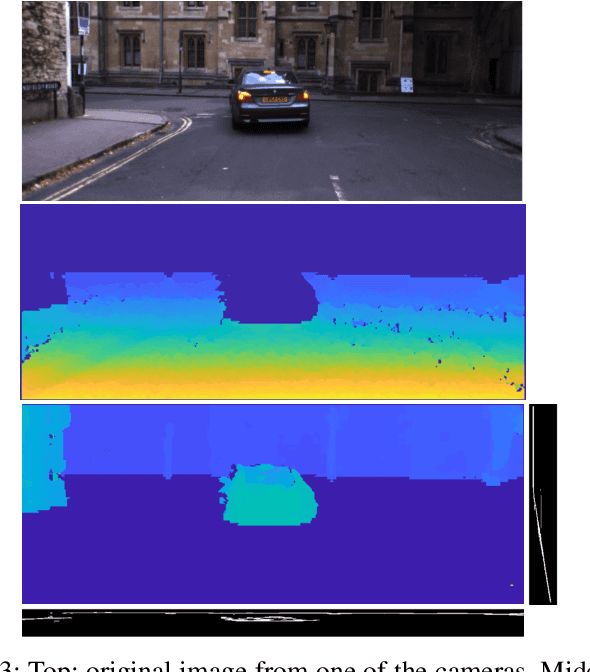
Automation driving techniques have seen tremendous progresses these last years, particularly due to a better perception of the environment. In order to provide safe yet not too conservative driving in complex urban environment, data fusion should not only consider redundant sensing to characterize the surrounding obstacles, but also be able to describe the uncertainties and errors beyond presence/absence (be it binary or probabilistic). This paper introduces an enriched representation of the world, more precisely of the potential existence of obstacles through an evidential grid map. A method to create this representation from 2 very different sensors, laser scanner and stereo camera, is presented along with algorithms for data fusion and temporal updates. This work allows a better handling of the dynamic aspects of the urban environment and a proper management of errors in order to create a more reliable map. We use the evidential framework based on the Dempster-Shafer theory to model the environment perception by the sensors. A new combination operator is proposed to merge the different sensor grids considering their distinct uncertainties. In addition, we introduce a new long-life layer with high level states that allows the maintenance of a global map of the entire vehicle's trajectory and distinguish between static and dynamic obstacles. Results on a real road dataset show that the environment mapping data can be improved by adding relevant information that could be missed without the proposed approach.
An LSTM Network for Real-Time Odometry Estimation
Feb 22, 2019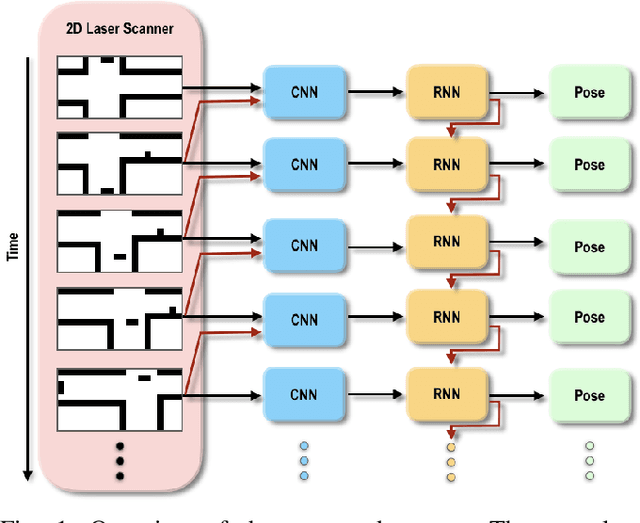
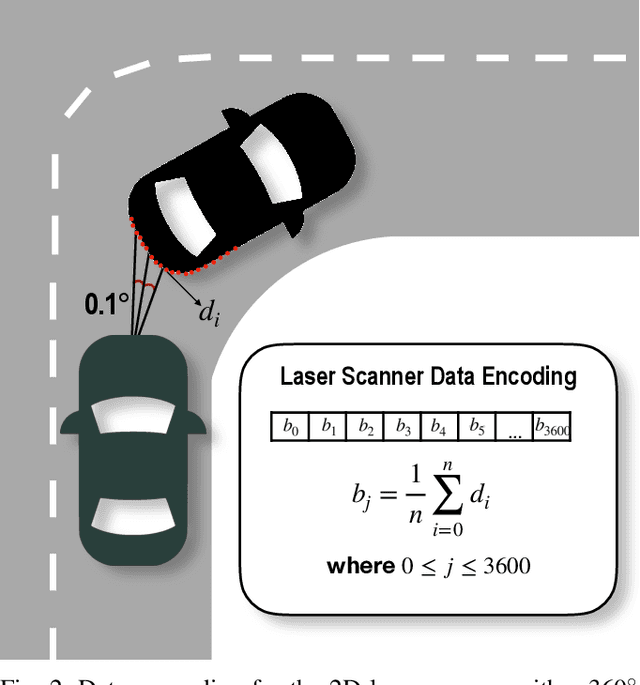
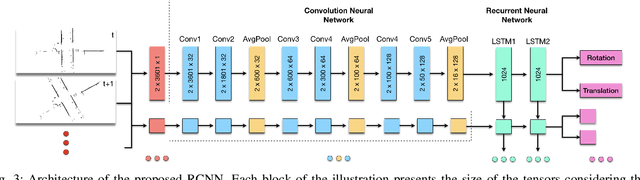
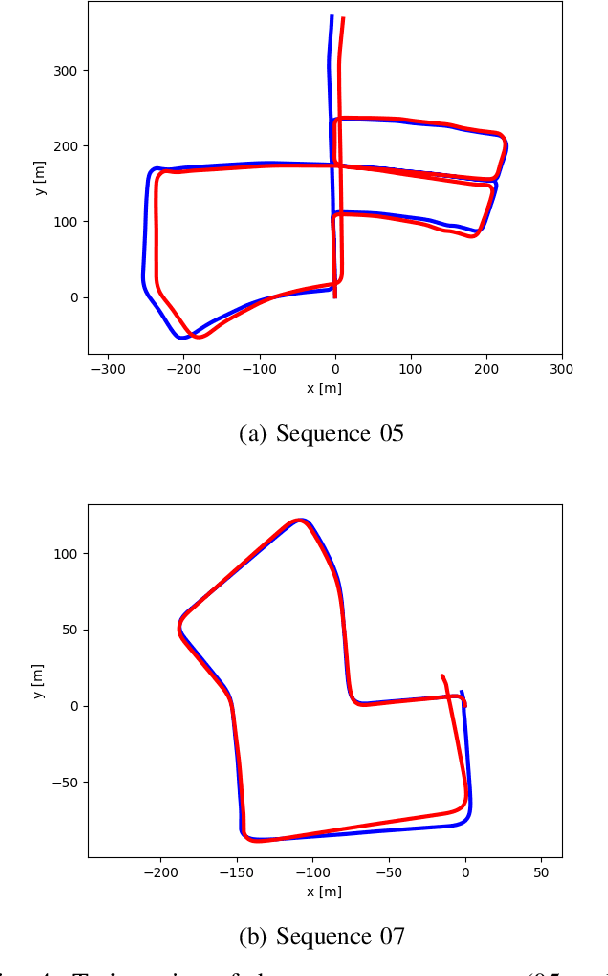
The use of 2D laser scanners is attractive for the autonomous driving industry because of its accuracy, light-weight and low-cost. However, since only a 2D slice of the surrounding environment is detected at each scan, it is a challenge to execute important tasks such as the localization of the vehicle. In this paper we present a novel framework that explores the use of deep Recurrent Convolutional Neural Networks (RCNN) for odometry estimation using only 2D laser scanners. The application of RCNNs provides the tools to not only extract the features of the laser scanner data using Convolutional Neural Networks (CNNs), but in addition it models the possible connections among consecutive scans using the Long Short-Term Memory (LSTM) Recurrent Neural Network. Results on a real road dataset show that the method can run in real-time without using GPU acceleration and have competitive performance compared to other methods, being an interesting approach that could complement traditional localization systems.
Monocular Urban Localization using Street View
Jun 16, 2016

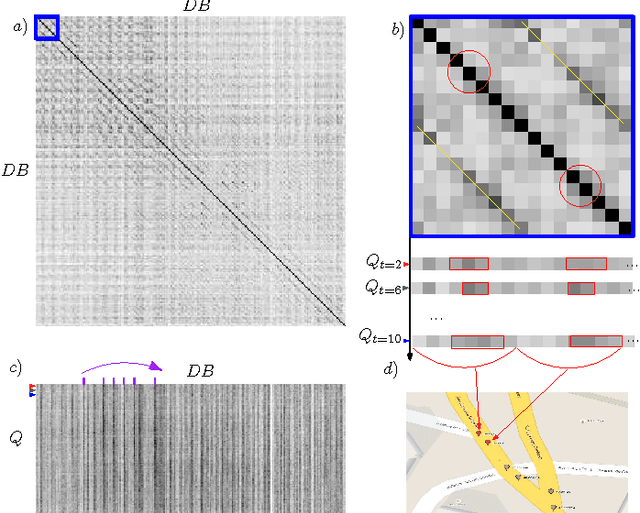

This paper presents a metric global localization in the urban environment only with a monocular camera and the Google Street View database. We fully leverage the abundant sources from the Street View and benefits from its topo-metric structure to build a coarse-to-fine positioning, namely a topological place recognition process and then a metric pose estimation by local bundle adjustment. Our method is tested on a 3 km urban environment and demonstrates both sub-meter accuracy and robustness to viewpoint changes, illumination and occlusion. To our knowledge, this is the first work that studies the global urban localization simply with a single camera and Street View.