 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointmap-Conditioned Diffusion for Consistent Novel View Synthesis
Jan 06, 2025



In this paper, we present PointmapDiffusion, a novel framework for single-image novel view synthesis (NVS) that utilizes pre-trained 2D diffusion models. Our method is the first to leverage pointmaps (i.e. rasterized 3D scene coordinates) as a conditioning signal, capturing geometric prior from the reference images to guide the diffusion process. By embedding reference attention blocks and a ControlNet for pointmap features, our model balances between generative capability and geometric consistency, enabling accurate view synthesis across varying viewpoints. Extensive experiments on diverse real-world datasets demonstrate that PointmapDiffusion achieves high-quality, multi-view consistent results with significantly fewer trainable parameters compared to other baselines for single-image NVS tasks.
RoDUS: Robust Decomposition of Static and Dynamic Elements in Urban Scenes
Mar 14, 2024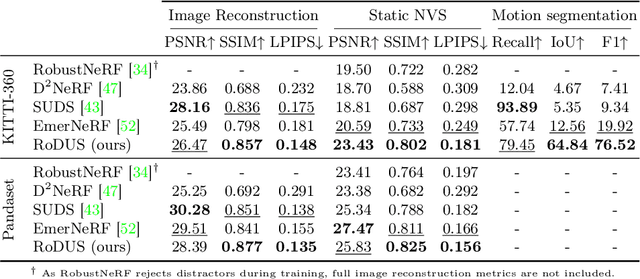
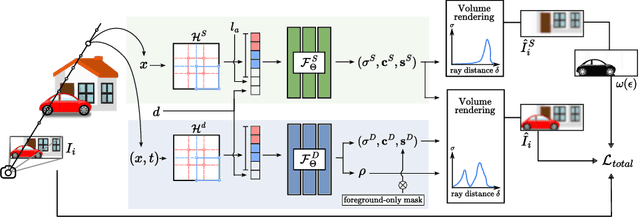
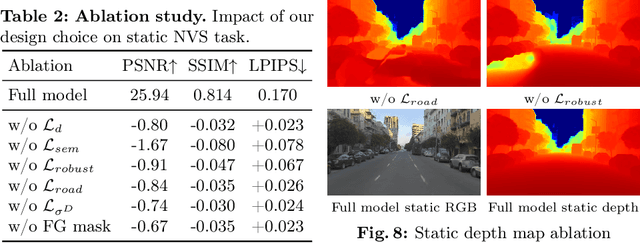
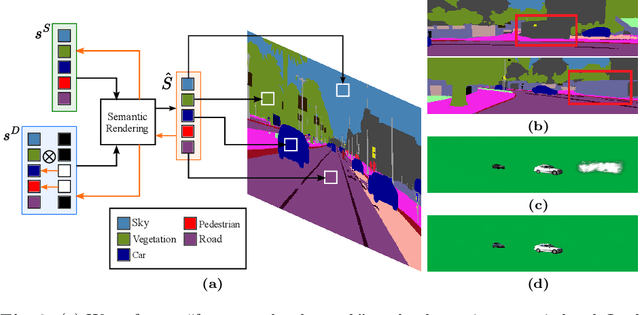
The task of separating dynamic objects from static environments using NeRFs has been widely studied in recent years. However, capturing large-scale scenes still poses a challenge due to their complex geometric structures and unconstrained dynamics. Without the help of 3D motion cues, previous methods often require simplified setups with slow camera motion and only a few/single dynamic actors, leading to suboptimal solutions in most urban setups. To overcome such limitations, we present RoDUS, a pipeline for decomposing static and dynamic elements in urban scenes, with thoughtfully separated NeRF models for moving and non-moving components. Our approach utilizes a robust kernel-based initialization coupled with 4D semantic information to selectively guide the learning process. This strategy enables accurate capturing of the dynamics in the scene, resulting in reduced artifacts caused by NeRF on background reconstruction, all by using self-supervision. Notably, experimental evaluations on KITTI-360 and Pandaset datasets demonstrate the effectiveness of our method in decomposing challenging urban scenes into precise static and dynamic components.
Semantically-aware Neural Radiance Fields for Visual Scene Understanding: A Comprehensive Review
Feb 17, 2024



This review thoroughly examines the role of semantically-aware Neural Radiance Fields (NeRFs) in visual scene understanding, covering an analysis of over 250 scholarly papers. It explores how NeRFs adeptly infer 3D representations for both stationary and dynamic objects in a scene. This capability is pivotal for generating high-quality new viewpoints, completing missing scene details (inpainting), conducting comprehensive scene segmentation (panoptic segmentation), predicting 3D bounding boxes, editing 3D scenes, and extracting object-centric 3D models. A significant aspect of this study is the application of semantic labels as viewpoint-invariant functions, which effectively map spatial coordinates to a spectrum of semantic labels, thus facilitating the recognition of distinct objects within the scene. Overall, this survey highlights the progression and diverse applications of semantically-aware neural radiance fields in the context of visual scene interpretation.