 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Redundancy and Biases in Public Document Information Extraction Benchmarks
Apr 28, 2023



Advances in the Visually-rich Document Understanding (VrDU) field and particularly the Key-Information Extraction (KIE) task are marked with the emergence of efficient Transformer-based approaches such as the LayoutLM models. Despite the good performance of KIE models when fine-tuned on public benchmarks, they still struggle to generalize on complex real-life use-cases lacking sufficient document annotations. Our research highlighted that KIE standard benchmarks such as SROIE and FUNSD contain significant similarity between training and testing documents and can be adjusted to better evaluate the generalization of models. In this work, we designed experiments to quantify the information redundancy in public benchmarks, revealing a 75% template replication in SROIE official test set and 16% in FUNSD. We also proposed resampling strategies to provide benchmarks more representative of the generalization ability of models. We showed that models not suited for document analysis struggle on the adjusted splits dropping on average 10,5% F1 score on SROIE and 3.5% on FUNSD compared to multi-modal models dropping only 7,5% F1 on SROIE and 0.5% F1 on FUNSD.
Information Extraction from Documents: Question Answering vs Token Classification in real-world setups
Apr 21, 2023Research in Document Intelligence and especially in Document Key Information Extraction (DocKIE) has been mainly solved as Token Classification problem. Recent breakthroughs in both natural language processing (NLP) and computer vision helped building document-focused pre-training methods, leveraging a multimodal understanding of the document text, layout and image modalities. However, these breakthroughs also led to the emergence of a new DocKIE subtask of extractive document Question Answering (DocQA), as part of the Machine Reading Comprehension (MRC) research field. In this work, we compare the Question Answering approach with the classical token classification approach for document key information extraction. We designed experiments to benchmark five different experimental setups : raw performances, robustness to noisy environment, capacity to extract long entities, fine-tuning speed on Few-Shot Learning and finally Zero-Shot Learning. Our research showed that when dealing with clean and relatively short entities, it is still best to use token classification-based approach, while the QA approach could be a good alternative for noisy environment or long entities use-cases.
Robust Domain Adaptation for Pre-trained Multilingual Neural Machine Translation Models
Oct 26, 2022Recent literature has demonstrated the potential of multilingual Neural Machine Translation (mNMT) models. However, the most efficient models are not well suited to specialized industries. In these cases, internal data is scarce and expensive to find in all language pairs. Therefore, fine-tuning a mNMT model on a specialized domain is hard. In this context, we decided to focus on a new task: Domain Adaptation of a pre-trained mNMT model on a single pair of language while trying to maintain model quality on generic domain data for all language pairs. The risk of loss on generic domain and on other pairs is high. This task is key for mNMT model adoption in the industry and is at the border of many others. We propose a fine-tuning procedure for the generic mNMT that combines embeddings freezing and adversarial loss. Our experiments demonstrated that the procedure improves performances on specialized data with a minimal loss in initial performances on generic domain for all languages pairs, compared to a naive standard approach (+10.0 BLEU score on specialized data, -0.01 to -0.5 BLEU on WMT and Tatoeba datasets on the other pairs with M2M100).
Information Extraction from Visually Rich Documents with Font Style Embeddings
Nov 07, 2021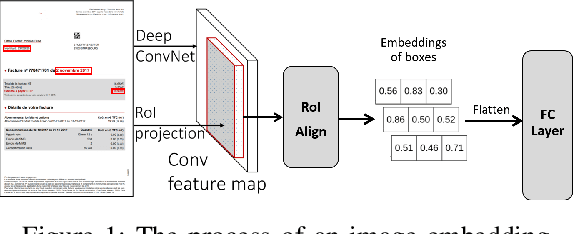
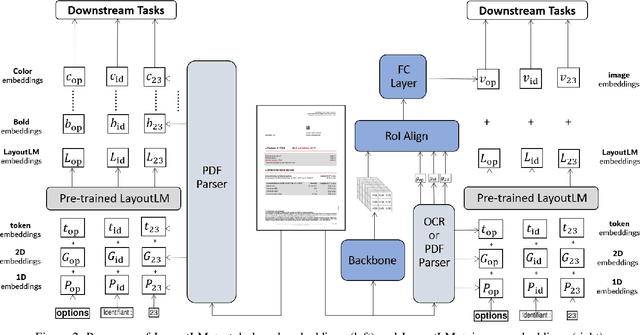


Information extraction (IE) from documents is an intensive area of research with a large set of industrial applications. Current state-of-the-art methods focus on scanned documents with approaches combining computer vision, natural language processing and layout representation. We propose to challenge the usage of computer vision in the case where both token style and visual representation are available (i.e native PDF documents). Our experiments on three real-world complex datasets demonstrate that using token style attributes based embedding instead of a raw visual embedding in LayoutLM model is beneficial. Depending on the dataset, such an embedding yields an improvement of 0.18% to 2.29% in the weighted F1-score with a decrease of 30.7% in the final number of trainable parameters of the model, leading to an improvement in both efficiency and effectiveness.