 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Extraction from Visually Rich Documents with Font Style Embeddings
Nov 07, 2021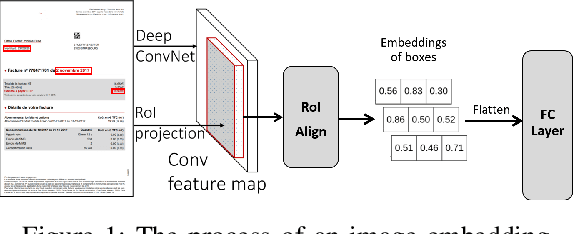
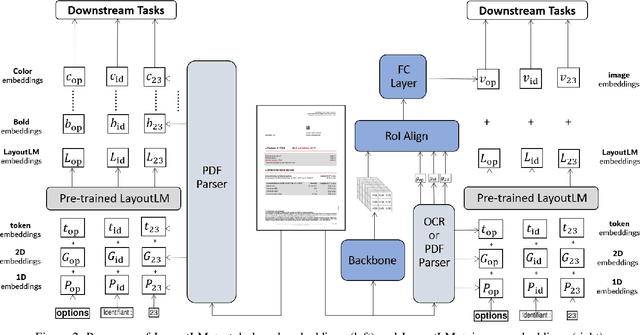


Information extraction (IE) from documents is an intensive area of research with a large set of industrial applications. Current state-of-the-art methods focus on scanned documents with approaches combining computer vision, natural language processing and layout representation. We propose to challenge the usage of computer vision in the case where both token style and visual representation are available (i.e native PDF documents). Our experiments on three real-world complex datasets demonstrate that using token style attributes based embedding instead of a raw visual embedding in LayoutLM model is beneficial. Depending on the dataset, such an embedding yields an improvement of 0.18% to 2.29% in the weighted F1-score with a decrease of 30.7% in the final number of trainable parameters of the model, leading to an improvement in both efficiency and effectiveness.
Batch Clustering for Multilingual News Streaming
Apr 17, 2020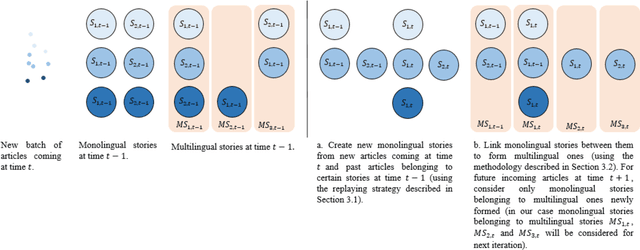
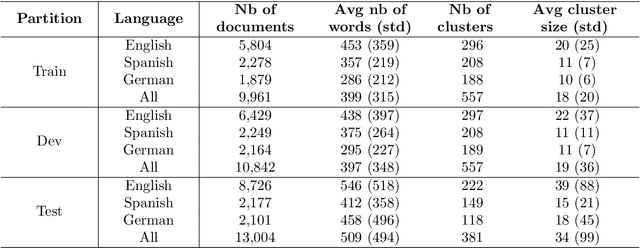
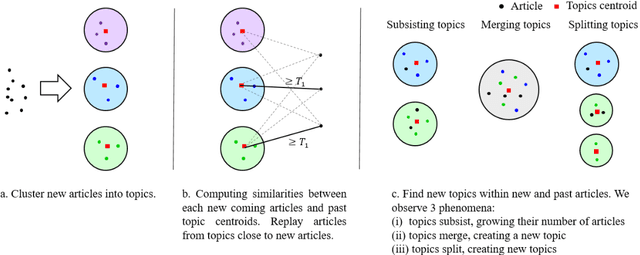
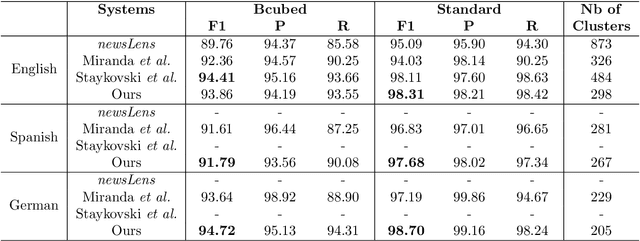
Nowadays, digital news articles are widely available, published by various editors and often written in different languages. This large volume of diverse and unorganized information makes human reading very difficult or almost impossible. This leads to a need for algorithms able to arrange high amount of multilingual news into stories. To this purpose, we extend previous works on Topic Detection and Tracking, and propose a new system inspired from newsLens. We process articles per batch, looking for monolingual local topics which are then linked across time and languages. Here, we introduce a novel "replaying" strategy to link monolingual local topics into stories. Besides, we propose new fine tuned multilingual embedding using SBERT to create crosslingual stories. Our system gives monolingual state-of-the-art results on dataset of Spanish and German news and crosslingual state-of-the-art results on English, Spanish and German news.
* 7 pages, 2 figures